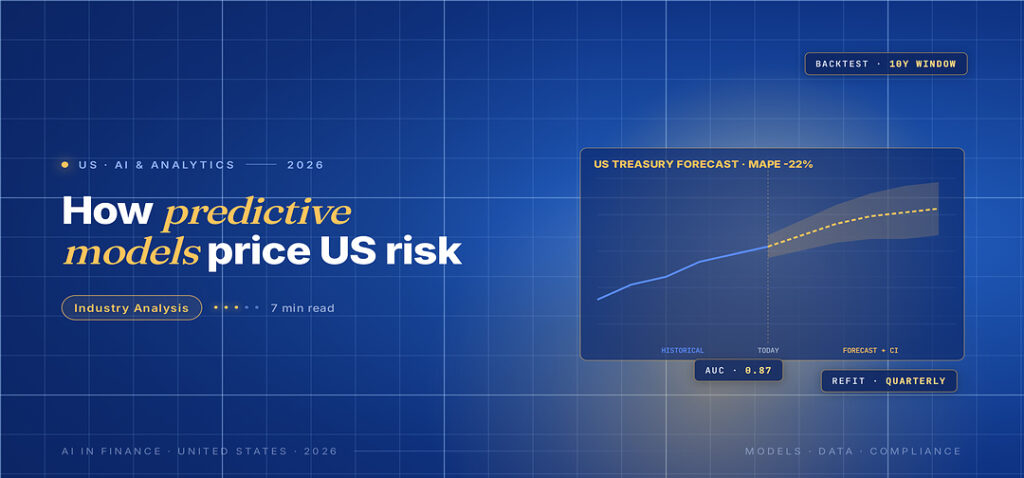
A treasury team at a mid-size US bank used to plan its quarterly liquidity moves by exporting six Excel files into a single workbook, eyeballing the trend lines, and arguing in a conference room about which assumption to defend to the audit committee. Two years ago, the same team retired the workbook. They now run a fortnightly liquidity forecast on a Python pipeline that retrains nightly against the bank’s general ledger and an internal feature store. The forecast is no more correct than the old workbook on its best days. It is much more correct on average, much faster to update, and much harder to politicise.
What predictive modelling actually does in US finance today
Predictive modelling in US finance now covers four distinct families of work. The first is forecasting: liquidity, deposit balances, loan delinquencies and operational losses. The second is propensity modelling: which customer will churn, which prospect will accept an offer, which transaction will be returned. The third is risk scoring: credit, fraud, anti-money-laundering. The fourth is pricing: from algorithmic execution at trading desks to dynamic insurance underwriting.
Each of those families has different stakeholders, different regulatory exposure and different operational pace. Forecasting often serves a CFO. Propensity serves growth. Risk scoring serves the chief credit or risk officer. Pricing serves the trading or insurance underwriting head. The models look similar on paper, but the surrounding governance and review cycles vary widely.
The technology baseline has converged. Gradient-boosted trees (XGBoost, LightGBM, CatBoost) carry the bulk of structured-data prediction in US finance. Neural networks dominate unstructured tasks such as filings analysis, document classification and image-based ID verification. Linear and logistic regression still hold their place where regulatory documentation matters more than marginal accuracy gains. The US payment rails most fintechs sit on generate much of the data these models actually consume.
Each family also has its own data shape. Forecasting consumes time-series with strong seasonality. Propensity consumes wide customer feature tables. Risk scoring consumes joined transaction histories with regulatory carve-outs. Pricing consumes high-frequency tick data. Teams that try to share one feature pipeline across all four families almost always discover, six months in, that they should have built four.
How a US fintech ships a predictive model into production in 2026
The pipeline that takes a model from notebook to production has standardised. A typical US fintech path looks like this: a data scientist explores in a Jupyter or VSCode notebook against a feature store, runs experiments tracked in MLflow or Weights and Biases, packages the model as a container that exposes a REST or gRPC endpoint, deploys it through a feature flag system, and watches a model monitoring dashboard for drift.
Feature stores have become a real layer rather than a buzzword. Feast, Tecton and the internal stores at the largest fintechs (often built on Snowflake or BigQuery plus a low-latency Redis or Cassandra cache) have made it possible to share features between training and serving without the data drift that used to plague handoffs.
Model risk management has caught up. The Federal Reserve’s SR 11-7 guidance, originally written for banks, is now a de facto checklist for any US fintech of meaningful size. Validation, documentation, backtesting and ongoing monitoring requirements once unique to commercial banks have spread across the rest of US finance. The ACH plumbing that powers most retail fintech imposes its own data quality demands that flow into model design.
The largest US asset managers and insurers have built dedicated model risk organisations that look more like internal regulators than like analytics groups. These groups own the inventory, the validation cycle, the documentation templates and the ongoing monitoring playbooks for every production model in the firm. A model that has not passed through this organisation cannot reach a customer-facing decision, regardless of how good it looked in the data science team’s notebook. That is now the norm at any US firm above several billion in assets under management.
A scoreboard for predictive modelling adoption in US finance
The composite figures below come from joint US bank technology surveys, vendor benchmarks (Snowflake, Databricks, AWS) and disclosed model risk inventories from the largest issuers. They sketch where US finance is actually using prediction today and what those models cost to operate.
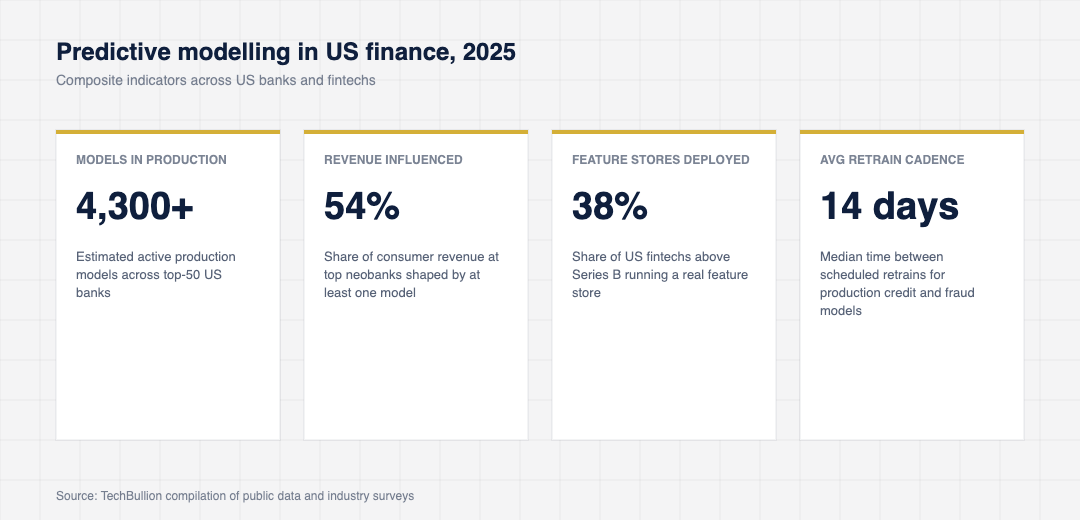
The number that surprises most operators is the share of US fintech revenue now influenced by model output. The same surveys that found single-digit shares in 2018 now find that more than half of revenue at the largest neobanks flows through a customer interaction that is shaped by at least one production model. That share is still rising.
Cost discipline has become a serious topic. Compute spend on training and inference for predictive modelling at large US banks now routinely lands in the tens of millions of dollars per year, and the FinOps practice around model workloads has matured to the point where most platform teams price each model by its compute and storage cost per prediction. Models that are expensive to run and do not earn their keep get retired aggressively.
The mistakes US finance teams keep making with prediction
Three mistakes recur in post-mortems of failed US predictive modelling initiatives. The first is the data leakage trap. A team trains a model that performs beautifully in backtest, ships it, and then discovers the features it relied on were unavailable at decision time in production. The fix is rigorous point-in-time correctness in the feature store, which sounds obvious and is harder than it sounds.
The second is treating accuracy as the only metric. A US bank fraud model that catches an extra two percent of fraud but raises false positives by ten percent will degrade customer experience badly enough that the line-of-business owner will quietly turn it off within a quarter. Modern teams optimise for a basket of metrics that includes false positive rate, latency, fairness and explainability, not just AUC.
The third is model staleness. A model deployed and forgotten will degrade. The deployment teams that survive in US finance have ritualised retraining cadences, drift detection on both inputs and outputs, and a tested rollback path. Without those three, the first regulatory exam or the first customer complaint reveals problems that should have been caught much earlier. Banking innovation that scales globally almost always sits on top of a model serving platform with serious operational discipline.
The state of explainability tooling has improved enough to change what regulators ask for. SHAP, surrogate models, counterfactual explanations and partial dependence analyses are now table stakes in any US bank model validation document. The smaller US fintechs that adopt these tools early tend to navigate partner-bank diligence faster than those that treat explanation as an afterthought.
What US fintech founders should understand about predictive modelling now
For a US fintech founder building anything that depends on prediction, three rules apply in 2026. Treat the data pipeline as the actual product. Most modelling failures are upstream of the model itself: missing features, broken joins, stale snapshots. A founder who insists on clean data lineage before any modelling work will end up with a much smaller team and a much more reliable product.
Hire one senior person who has shipped a model through a US regulatory exam, even if your fintech is not yet regulated. The exam vocabulary (model risk, ongoing monitoring, challenger models, conceptual soundness) becomes the operating vocabulary of any team that wants to sell to banks, and you will pay for that hire many times over the first time a partner bank asks you to document your fairness testing.
Resist the urge to ship a model into a critical path before you have a credible rollback. Most US fintechs that have had a model-related outage discovered, in the heat of incident response, that no one had defined what a fallback prediction was. The rollback design is more useful than any model performance graph.
The retired Excel workbook is the visible artefact of a deeper shift. US finance teams are not predicting better because their models are smarter. They are predicting better because the surrounding operational discipline finally caught up with the modelling.
For the modeling-governance framework that US banks follow, see Federal Reserve SR 11-7 model risk management guidance.






































