The reconciliation team at a US neobank used to spend three of every five business days chasing a single class of bug. A user would tap a card, the authorisation would post, and somewhere between the issuer processor and the bank’s ledger a write would land in the wrong order. By 2023 that team had shrunk to one person, and the bug had effectively disappeared. The change had nothing to do with the team’s diligence and everything to do with a single architectural shift: the bank had moved its internal payments stack to an event-driven design where every state change was first written to an append-only log.
Why US finance teams moved toward event-driven architecture
The shift started in the trading world, where matching engines have always been event-driven by necessity, and it spread outward into US fintech through a combination of vendor maturity and incident learning. Kafka reached production maturity around 2015. AWS Kinesis hit reliable scale by 2017. By 2019, the largest US fintechs had at least one team running event sourcing in production. By 2023, the pattern had become the default for any new build that touched money.
Three drivers explain the move. The first is audit. Financial regulators expect every state change to be reproducible from a chronological record, and an append-only log is the most natural form for that record. The second is reconciliation. When two services disagree about state, having both subscribe to the same log eliminates the class of bug that comes from out-of-order writes. The third is throughput. Event-driven systems decouple producers from consumers, which lets a US fintech absorb a payday spike without scaling every downstream service in lockstep.
The cultural side matters too. Engineering teams that adopt event-driven thinking tend to develop a discipline around invariants, replayability and idempotency that compounds across the codebase. A junior engineer who learns to ask whether a handler is idempotent before writing it tends to write fewer bugs across their entire career.
Tooling around event-driven systems has matured fast. Schema Registry now ships in every commercial Kafka distribution. Lenses, Conduktor and Kpow give operators a usable UI for the topics in their cluster. Debezium and the major change-data-capture connectors make it easy to wire a Postgres write stream into a Kafka topic without writing custom code. The barrier to entry for a small US fintech team has fallen dramatically in the last five years, and the ecosystem assumption is now that the team can adopt the pattern without hiring a dedicated platform engineer.
What an event-driven US fintech actually looks like under the hood
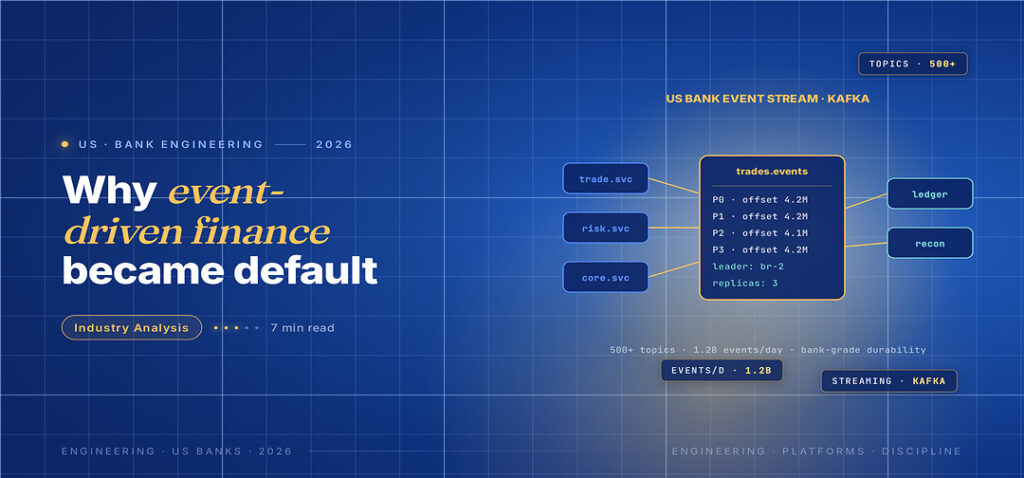
A typical 2026 US fintech runs an event-driven core that has three layers. The first layer is the event broker, almost always Kafka, Confluent Cloud, AWS Kinesis or Redpanda. The second is a small set of stateless services that consume events, apply business rules and emit new events. The third is a materialised view layer, usually a Postgres or ClickHouse store, that serves the read paths the application actually uses.
The event topics themselves are versioned, schema-controlled and treated as a public API. Schema registries (Confluent’s Avro registry, Apicurio, the JSON Schema variants) keep producers and consumers honest. A breaking change to an event schema at a serious US fintech requires a deprecation cycle that can take months, which is exactly the kind of discipline that database tables historically did not get.
Saga patterns and choreography handle multi-step flows. A money movement that touches authorisation, fraud screening, ledger posting and notification is expressed as a series of events with compensating actions, rather than as a giant transaction holding locks across services. The US payment rails most fintechs sit on are now usually reached through a saga handler that emits a payment-initiated event, waits for partner responses, and emits the appropriate follow-up.
The migration from a database-centric architecture to an event-driven one is rarely all-or-nothing. The pattern that works best in US fintech is to introduce events alongside the existing database writes, with the database remaining the source of truth, and to incrementally shift authority over to the event log. After six to twelve months, the event log usually wins, but the path that gets there is incremental rather than dramatic.
A scoreboard for event-driven adoption in US fintech
The data below comes from a composite of vendor surveys (Confluent, AWS, Datadog), open-source project download statistics, and US fintech engineering blog disclosures over the past two years. It sketches where the pattern has actually taken hold.
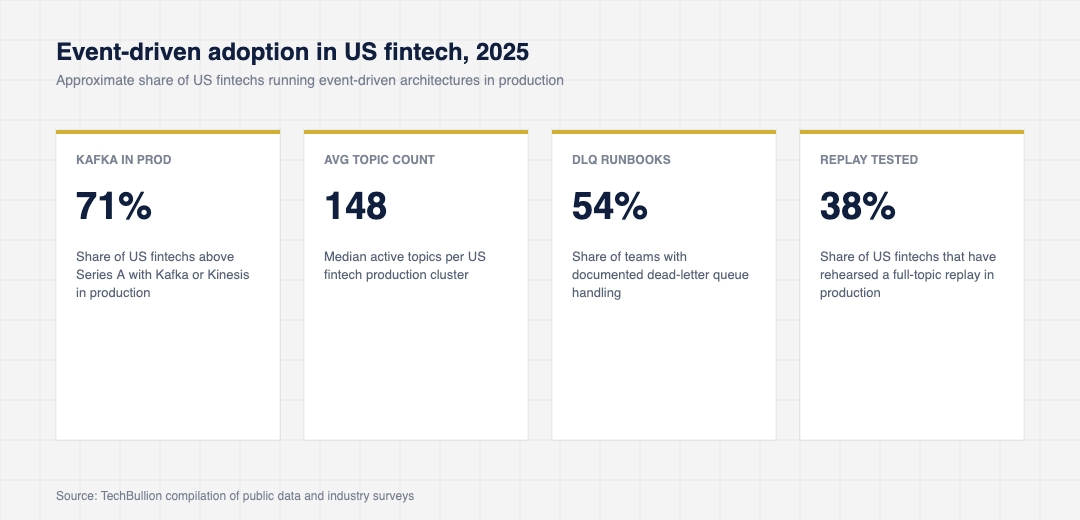
The number that surprises most operators is the share of US fintech POSTs that now flow through Kafka rather than being committed directly to the database. The pattern is no longer experimental. It is mainstream, and the operational tooling around it has caught up to make this normal for engineering teams that would have considered it heroic five years ago.
One subtle benefit of event-driven design that often surprises operators is observability. Because every state change is captured as an event, tools like ksqlDB, Materialize and even simple analytical SQL on a topic mirror let teams answer questions about live system behaviour without having to instrument anything new. A product manager who used to wait two weeks for a data team to run a query can now write the query themselves against the event stream.
The failure modes that still bite event-driven US fintech
Three failure modes recur in disclosed US fintech incident reports involving event-driven systems. The first is consumer lag. A slow downstream service builds up topic backlog, the broker eventually exerts back-pressure, and customer-facing flows stall. The mitigation is rigorous lag monitoring with alerting at the topic level, plus the ability to deploy faster consumer instances quickly.
The second is poison-pill messages. A single malformed event can crash a consumer in a tight loop. The cure is a dead-letter topic plus a well-rehearsed runbook for triaging and re-processing those messages.
The third is replay surprises. Replaying a topic to recover from a bug is powerful but dangerous, because side effects (notifications, partner-bank API calls, ACH submissions) cannot be replayed safely. The teams that have invested in replay-safe handlers, with idempotency keys and side-effect quarantine, can recover from production bugs in minutes. The teams that have not often discover their event-driven system can recover state perfectly while doubling every notification the customer was supposed to get. The ACH-based plumbing that flows through most US retail fintech is unforgiving of side-effect mistakes.
Cost discipline matters too. Kafka clusters at any meaningful US fintech now run into seven-figure annual spend, and the cost is driven less by storage than by network egress and inter-region replication. The teams that watch this line tend to be the same teams that retire stale topics aggressively, which has the side benefit of keeping the schema surface clean.
What founders building money movement should take from this
For a US fintech founder shipping a money movement product in 2026, three pieces of advice from the engineering teams that have done this at scale tend to hold up. First, write every handler as if it will be replayed three times in the next year, because it will. Idempotency keys are not optional.
Second, treat the event schema as the actual contract. The shape of the events your services emit is more durable than the shape of any single service, and it will outlive at least one full rewrite. Investing in clean event schemas in year one pays back across every later refactor.
Third, instrument the lag and the dead-letter queue from day one. Most US fintech outages involving event-driven systems are visible on lag and DLQ dashboards twenty minutes before they become customer-visible. The teams that watch those dashboards close those incidents quietly. Banking innovation that scales globally almost always has a serious investment in this kind of telemetry by the time it crosses Series B.
The append-only log is no longer an exotic architectural choice in US finance. It is now the default for any team that wants the audit, throughput and reconciliation properties the regulator and the customer both quietly require. The reconciliation team that shrank from five engineers to one is the visible outcome of a much larger pattern.
For the foundational documentation behind most event-log deployments described above, see Apache Kafka documentation.