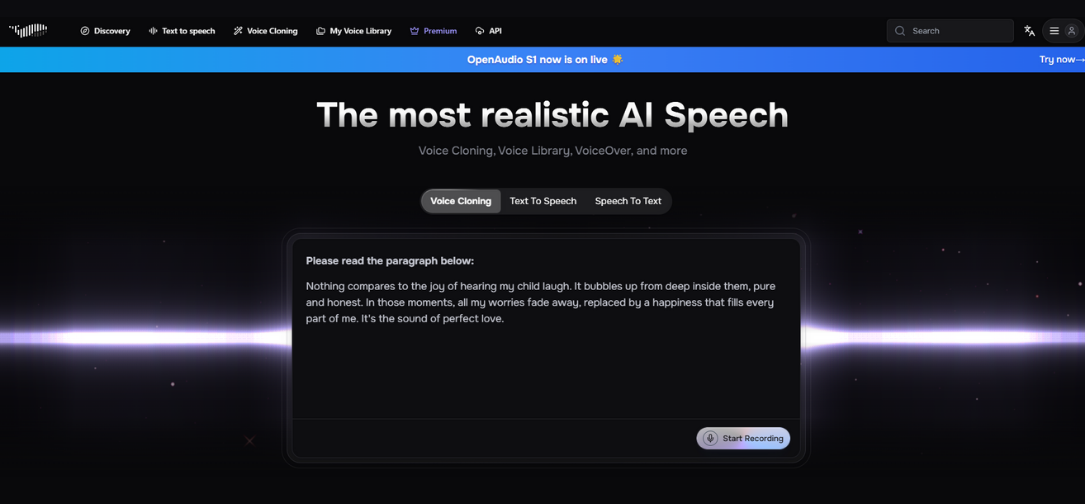
SAN FRANCISCO — June 4, 2025: Hanabi AI, an emerging leader in generative voice technology, today announced the launch of OpenAudio S1, the world’s first AI voice actor designed to give users real-time control over emotional and tonal expression. OpenAudio S1 redefines voice synthesis, transforming machine speech from robotic narration into expressive, emotionally resonant performance. The model is now available in open beta at fish.audio, free for anyone to try.
“We believe the future of AI voice-driven storytelling isn’t just about generating speech — it’s about performance,” said Shijia Liao, founder and CEO of Hanabi AI. “With OpenAudio S1, we’re shaping what we see as the next creative frontier: AI voice acting.”
From Text-to-Speech to AI-Directed Performance
Unlike conventional text-to-speech tools, OpenAudio S1 doesn’t simply read lines—it performs them. Built to mirror the richness of human vocal delivery, S1 enables precise emotional tuning and vocal control. Users can manipulate tone, pacing, and emotional nuance in real time, whether they want a voice that quivers with anxiety or bursts with joy.
“Voice is one of the most powerful ways to convey emotion, yet it’s the most nuanced, the hardest to replicate, and the key to making machines feel truly human,” said Liao. “OpenAudio S1 is the first AI speech model that gives creators the power to direct voice acting as if they were working with a real human actor.”
Built for Creators, Powered by Advanced AI
Under the hood, OpenAudio S1 is driven by a 4-billion parameter architecture trained on a diverse set of text and audio data. It offers creators, developers, and performers cinematic-quality voice output—instantly. Integrated into the Fish Audio platform, S1 supports applications ranging from short-form social content to full-length audio dramas.
Independent testing from Hugging Face’s TTS Arena places OpenAudio S1 ahead of industry leaders like OpenAI, ElevenLabs, and Cartesia in several key areas:
- Expressiveness: Delivers film-grade emotional realism, from subtle sarcasm to raw fear.
- Sub-100ms Latency: Enables seamless voice interaction in real-time environments like gaming or live streaming.
- Fine-Grained Real-Time Control: Adjust pitch, pace, and emotion on the fly with natural language cues such as “(confident but hiding fear)” or “(whispering with urgency)”.
- State-of-the-Art Voice Cloning: Faithfully captures and reproduces the unique rhythm, tone, and texture of a speaker’s voice.
- Multilingual Mastery: Supports 11 languages with fluent switching between speakers and dialects—ideal for multilingual storytelling and global audiences.
More Than a Product—A Vision
OpenAudio S1 marks the beginning of Hanabi AI’s broader mission to develop emotionally intelligent AI companions. Rather than viewing voice as a final output, Hanabi positions it as the emotional core of human-machine interaction.
To achieve this, Hanabi operates through two tightly aligned initiatives:
- OpenAudio Lab, the company’s internal research division, is advancing breakthroughs in speech fidelity, controllability, and emotional range.
- Fish Audio, the consumer-facing platform, brings these innovations to life with creator-focused tools and APIs.
Hanabi also plans to progressively open-source key components of its voice architecture and training infrastructure, staying true to its roots in the open AI community.
Scaling Fast with a Gen Z Team
Founded by a four-person Gen Z team, Hanabi AI has grown explosively in 2025—scaling annualized revenue from $400,000 to over $5 million in just four months and increasing monthly active users from 50,000 to over 420,000. This growth is driven by Fish Audio’s suite of real-time and long-form voice tools, which are rapidly gaining traction among creators worldwide.
CEO Shijia Liao, a veteran of the open-source voice community, previously contributed to widely-used models like So-VITS-SVC, GPT-SOVITS, and Bert-VITS2. That foundation of technical excellence and community trust now fuels the company’s commercial momentum.
To learn more about OpenAudio S1 and the team’s research-driven approach, visit the official launch blog: https://openaudio.com/blogs/s1
Pricing and Availability
- Fish Audio Playground Premium: Unlimited voice generation for $15/month or $120/year
- API Access: $15 per million UTF-8 bytes (~20 hours of audio)
About Hanabi AI
Hanabi AI Inc. is shaping the next generation of voice technology. With OpenAudio S1, the company empowers storytellers to direct AI voices as they would human actors—down to every pause, whisper, and emotional beat. Built on open-source principles and designed for creators, Hanabi’s Fish Audio platform is setting a new standard for voice performance in AI.
Media Contact
Derek Huang
Email: dderekhuang@fish.audio