The first time a senior US bank technologist proposed running customer facing services on Kubernetes, the response from the audit team was a measured pause and a request for written justification. A few years later, the same audit team writes Kubernetes specific control standards as part of the bank’s internal policy, and the same technologist runs thousands of pods in production. Kubernetes for financial systems has stopped being a controversial choice inside US banks, although the path it took to get there was not nearly as clean as the vendor decks suggest.
Where Kubernetes for Financial Systems Now Sits in the US Stack
Inside a typical large US bank, Kubernetes runs three categories of workload. The first is consumer facing applications, including the API tier behind the mobile app and the online banking portal. The second is internal services, including the dashboards, workflow systems, and tooling that bank employees use every day. The third is data and machine learning workloads, including feature stores, model training jobs, and real time scoring services that need to scale predictably under load.
The pattern is consistent. Workloads that are stateless, that need to scale horizontally, and that benefit from declarative deployment have moved to Kubernetes. Workloads that depend on a specific server, a specific kernel feature, or a specific licensing model have largely stayed where they were. The federation between these is now the practical architecture inside most US banks.
The cloud landscape behind these clusters is mixed. Most large US banks run a combination of cloud managed Kubernetes, including Amazon EKS, Google GKE, and Azure AKS, with on premise clusters for sensitive workloads. A smaller set of institutions run their own Kubernetes platforms based on the OpenShift distribution or directly on upstream Kubernetes.
The Workloads Where Kubernetes Has the Clearest Wins
Three categories of US bank work have a strong fit with the Kubernetes model.
The first is APIs behind the consumer mobile and web channels. These workloads benefit from horizontal scale during peak hours, automated failover when a node fails, and the ability to deploy a new version with a controlled rollout. The infrastructure to do this on bare metal or on basic virtual machines is real, and Kubernetes provides it as a primitive rather than a custom implementation.
The second is event driven processing. Fraud signal pipelines, payment routing services, and notification systems sit naturally on a platform that can scale workers based on queue depth. Kubernetes with Kafka, KEDA, and a service mesh has become the reference architecture for these workloads at most large US banks.
The third is batch and machine learning. Model training jobs, large scale reporting pipelines, and end of day batch work benefit from the ability to spin up many parallel containers, run a job, and tear the resources down. Kubernetes Jobs, Argo Workflows, and similar tools have made this pattern straightforward for US bank data engineering teams.
A fourth strong fit is the integration tier between modern services and legacy core systems. US banks run a meaningful amount of code that does translation, enrichment, and reformatting between modern APIs and mainframe protocols. Kubernetes handles this layer well because the workload is stateless, the throughput requirement is high, and the deployment cycle benefits from continuous delivery.
How Kubernetes for Financial Systems Compares to the Alternatives
The comparison is rarely framed as Kubernetes versus a single alternative. It is framed as where each workload best lives.
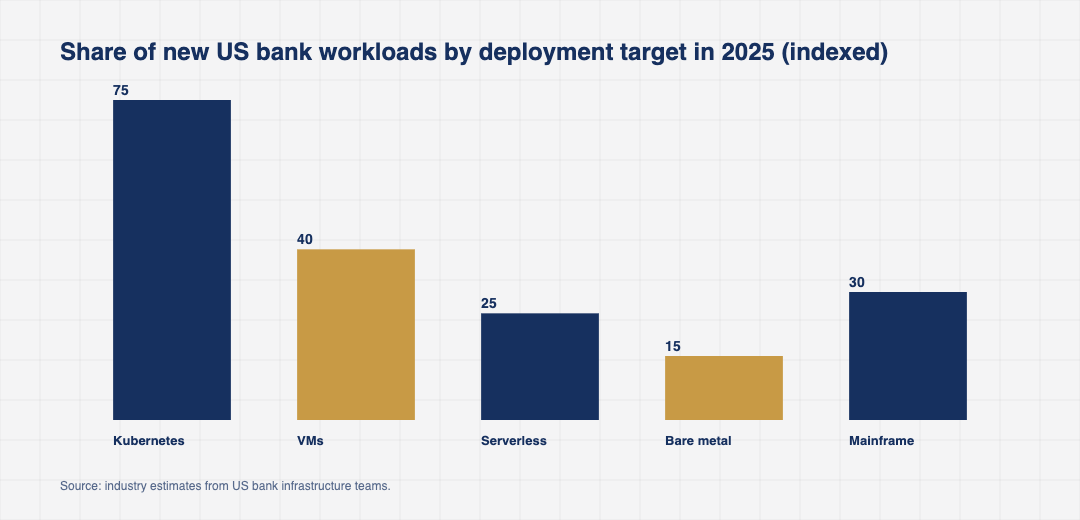
Virtual machines remain in use for vendor packaged applications, for legacy systems that cannot be containerized cleanly, and for some database deployments. Mainframes continue to run the core ledger and certain transaction processing systems where the operational track record outweighs the modernization case. Managed serverless, including AWS Lambda and Azure Functions, has taken share for short lived event handlers and integration glue.
The honest picture in 2026 is that Kubernetes is the default for new microservices, and that the rest of the estate is being modernized where the economic case is clear and left alone where it is not. That balance is what makes the platform economics work.
The Friction Points US Bank Kubernetes Teams Still Manage
Four frictions come up repeatedly.
The first is operational complexity. A Kubernetes cluster at bank scale has many moving parts, including the control plane, the network layer, the storage layer, the service mesh, the observability stack, and the policy engine. Each one is a piece of software that needs to be operated, upgraded, and secured. US banks have responded by hiring dedicated platform teams and by standardizing on managed offerings where they can.
The second is security and compliance. US bank security teams have had to develop new tooling and processes for container image scanning, runtime threat detection, network policy enforcement, and secrets management. The vendors in this space, including Aqua, Sysdig, Snyk, and Wiz, have built meaningful businesses on US bank Kubernetes spend.
The third is cost. Kubernetes is not inherently cheap, and US banks running large clusters have learned that careful resource requests, autoscaling configuration, and FinOps practices are required to keep spend under control. The cost of a poorly tuned cluster can exceed the equivalent virtual machine deployment by a meaningful margin.
The fourth is regulatory traceability. When a transaction passes through a workload running on Kubernetes, the auditor needs to know exactly which version of the image processed it, when it was deployed, by whom, and against which configuration. The tooling to provide that level of traceability has matured, but it has not been free.
Where Kubernetes for Financial Systems Is Heading
Three signals shape the next phase.
The first is the platform engineering shift. US banks have built internal developer platforms on top of Kubernetes, with golden path templates, automated provisioning, and self service capabilities. Tools like Backstage, Crossplane, and bank specific internal frameworks have become the way teams interact with the underlying clusters. The platform layer is where the productivity gains live.
The second is the slow but steady move toward multi cluster and multi region deployments. US banks operating critical workloads now run them across multiple Kubernetes clusters, in multiple regions, with traffic routing and failover handled by the platform. The investment in multi cluster operations is significant, and it is what allows the bank to meet recovery time objectives that were previously hard to achieve.
The third is the rise of policy as code. Tools like Open Policy Agent, Kyverno, and bank specific policy engines have made it possible to encode security and compliance rules as Kubernetes objects, enforced at admission time. This is how US banks scale their compliance posture without slowing development to the pace of the manual review process.
For US bank technology leaders, the question is no longer whether to invest in Kubernetes. It is how to keep the platform coherent, how to manage the cost, and how to evolve the operating model as the workload mix continues to shift.
A fourth signal is the deepening role of WebAssembly and sandboxed runtimes inside the Kubernetes platform. US banks evaluating these technologies see a path to running untrusted or partner provided code with stronger isolation than a container alone can offer. The work is still early, but the use cases for embedded partner integrations and policy enforcement are real.
The measured pause from the audit team in the earlier example has become a written control standard, and the Kubernetes platform inside the bank has become a piece of infrastructure that the audit team itself relies on for evidence collection. That shift, from a controversial choice to a working part of the bank operating model, is what made Kubernetes for financial systems durable inside US institutions, and it is what will keep it funded through the rest of the decade as the next generation of workloads is built on top of it.