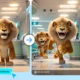
Most of the early reaction to Google’s leaked Gemini Omni model has fixated on the obvious thing: the video output looks good. A professor working a trigonometric proof onto a chalkboard, a seaside dinner scene with believable lighting, hand movements that don’t drift off-frame. Those samples are doing the rounds because they’re impressive, and because impressive video is the easiest thing to share on X. But the more interesting bet inside the leak isn’t about how the model generates — it’s about what happens to a video after it exists.
The card that surfaced in the Gemini app last week described Omni in four short clauses: “Create with Gemini Omni: meet our new video model. Remix your videos, edit directly in chat, try a template, and more.” Three of those four phrases are about post-generation behavior, not generation. That’s the part of the story that hasn’t been priced in yet.
The Chat-Native Editing Bet
For three years, AI video has effectively meant “type a prompt, get a clip, regenerate if it’s wrong.” Iteration cost has been roughly the same as starting over. Nano Banana broke that ceiling for static images by making targeted edits — change the hat, swap the background, remove the watermark — work inside a conversational loop. Google is now applying that exact playbook to video.
The implication is that “make the chalk in the third second stop fading” or “replace the spaghetti with rice noodles” becomes a chat instruction, not a fresh generation. If the model holds together on real edits — preserving the rest of the frame, maintaining temporal coherence, not introducing new artifacts — it would be the first widely available video model where iteration cost actually drops below the cost of regenerating.
This is the structural advantage Google has been positioning toward for two years. Veo 3 and Veo 3.1 were strong on cinematic shot quality but didn’t fundamentally change the iteration loop. Omni, on the evidence so far, looks designed to.
What the Demos Actually Show
Two prompts from the leaked staging access have done most of the work shaping the early impression.
The math proof video is the stronger sample. The professor’s hand tracks correctly across the board, the trigonometric identities are formally valid, the lighting is consistent, and the model handles the kind of fine motor detail — writing speed, chalk pressure — that has historically been a giveaway. There are still tells; the chalk fades inconsistently toward the end of the clip. But the overall scene reads as a real demonstration rather than a generated approximation.
The dinner scene is the weaker one. Spaghetti appears on plates that were empty a frame earlier. Chewing motions don’t match bite counts. Object permanence breaks in ways that ByteDance’s Seedance 2.0 handles cleanly on a comparable prompt. This is the part of the model that suggests Omni — at least the Flash-tier variant most likely behind these public samples — still trails the best benchmark scores on complex multi-object scenes.
The right read is that Omni isn’t trying to win the static-frame quality competition. It’s trying to win the workflow.
Why Google Is Consolidating the Brand
The shift from Veo to Gemini Omni is the other tell most coverage has underweighted. Google has spent two years maintaining parallel product lines — Veo for video, Imagen for images, Nano Banana for image editing, Gemini for text and reasoning. Each had its own brand, its own access path, its own quirks.
Omni dissolves that. If the metadata reports are right — that Omni is technically an extension of Veo but ships under unified Gemini branding — Google is signaling that video is no longer a separate product. It’s a modality inside the same conversational surface as everything else. You ask, you get a video, you edit it in the same thread, you remix it with an image you generated three turns ago.
That’s the bet that matters for anyone building creator tools, marketing pipelines, or video-first applications. If you want to see how the workflow feels in practice before the official rollout, the Gemini Omni demo is the cleanest current path — it aggregates the leaked outputs and prompt examples without the friction of waiting for staged access.
Where Omni Sits in the Field
The competitive context, briefly:
- ByteDance Seedance 2.0 currently holds most public benchmark titles, particularly on complex scenes and physical accuracy.
- Alibaba Wan 2.7 ships the most comprehensive feature set — text-to-video, image-to-video, reference-to-video, video editing, 1080p with audio sync.
- Kuaishou Kling V3.0 is competitive on cinematic output, particularly for Asia-market creators.
- OpenAI Sora 2 is API-only after the consumer app shutdown at the end of April. Still strong on physics, but its addressable surface area has shrunk.
- Google Veo 3.1 leads on cinematic camera work and remains the only frontier model with reliable native audio generation.
If Omni inherits Veo’s audio capabilities while adding chat-native editing, it doesn’t need to beat Seedance on raw generation benchmarks to be the most useful tool in the lineup. Workflow speed compounds in ways that benchmark wins don’t. Creators who test Gemini Omni before that calculation becomes consensus will have a meaningful head start.
What to Expect at I/O
Google I/O runs May 19–20, 2026, and the signal-to-noise on Omni’s launch timing is unusually clean. The UI strings have shipped to a small cohort, the metadata is public, and TestingCatalog has surfaced internal notes suggesting Omni will be exposed through the Gemini API as an agent-like product on the same pattern as Deep Research in AI Studio.
The specific things worth watching on stage:
- Whether Omni ships in both Flash and Pro variants on day one, or staggers.
- Whether API access opens immediately, or trails the consumer rollout by weeks.
- Whether the chat-native editing capability is gated behind the Pro tier (likely) or available across both.
- Whether Google publishes any direct comparison against Seedance 2.0 or Sora 2 — historically they avoid this, but the framing of a unified Gemini model might push them to.
Pricing will also matter. The early staging user burned through 86% of their daily Pro-tier quota on two generations, which suggests Google is either undersizing the quota deliberately or the per-generation compute cost is high enough that consumer-tier pricing won’t be sustainable. Both readings imply a tightened tier structure at launch.
The Bottom Line
Gemini Omni isn’t the model that wins benchmark leaderboards. It’s the model that might make benchmark leaderboards less relevant. Chat-native editing, video remixing, and the consolidation of Google’s generative stack under one brand all point in the same direction: the next phase of AI video competition is about workflow, not just frame quality.
The full picture will arrive on stage at I/O. Until then, the Gemini Omni video model is the most direct way to see what Google has actually built — and to start thinking about what your own video pipeline looks like when iteration is a conversation, not a regeneration.