Every team building on LLMs is about to have the same budget conversation. Anthropic’s Claude Fable 5, released June 9, 2026, opens a new Mythos-class capability tier — and a new price tier to match, at $10 per million input tokens and $50 per million output tokens. The teams that adopt it without their bills exploding share one architectural habit: they put a gateway in front of their models. OrcaRouter is built for exactly this — one API key, 200+ models including Claude Fable 5 at pass-through pricing with 0% markup, plus an integrated AI firewall that enforces guardrails and tool-call policies for agent traffic. This article lays out the cost math and the routing strategy that makes a $50/M model affordable in production.
Do the math before you adopt
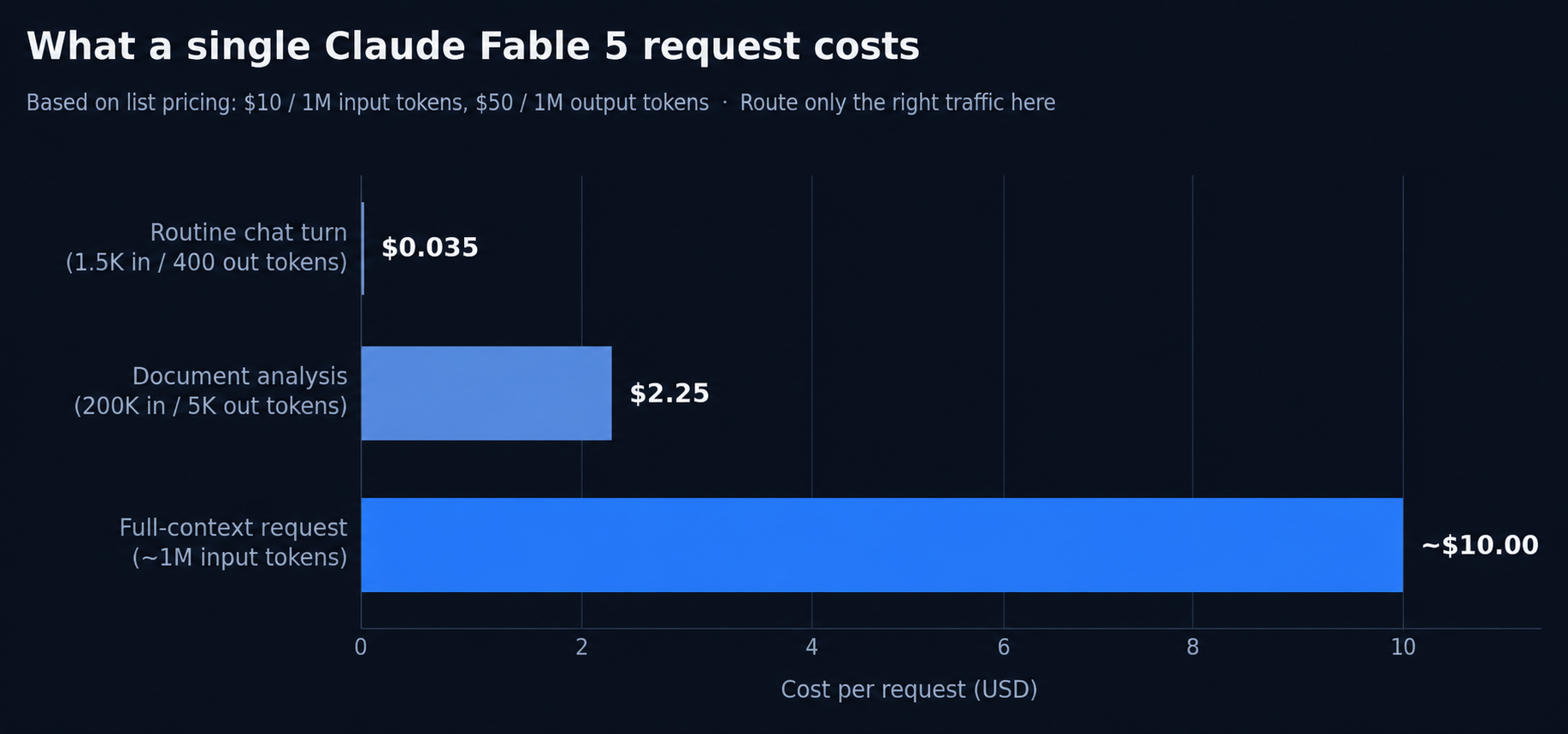
Sticker prices per million tokens feel abstract, so let’s make them concrete with three realistic request profiles.
A routine chat turn — say 1,500 input tokens and 400 output tokens — costs about $0.035 on Fable 5. Run 100,000 of those a day and you’re at roughly $3,500 daily, over $100K a month, for traffic a budget model would handle indistinguishably well at a small fraction of the cost.
A serious document analysis — 200,000 tokens of contracts in, a 5,000-token structured summary out — costs about $2.25. For legal review or due diligence, that’s trivially worth it; the same task used to require chunking pipelines, retrieval infrastructure, and an engineer’s afternoon.
A full-context request — using most of the 1,000,000-token window — costs around $10 in input alone. This is the headline capability of Fable 5, and it’s priced like one. You want these requests to exist, because they replace entire workflows. You just don’t want them to be accidental.
The pattern is obvious once you write it down: frontier pricing punishes indiscriminate usage and rewards precision. The cost problem is not the model’s rate; it’s sending the wrong traffic to it.
Per-request cost at list pricing — the case for tiered routing
Step one: separate your traffic into tiers
Audit a week of production requests and most teams find a distribution like this: the overwhelming majority is routine — classification, extraction, short summaries, formatting, FAQ-style chat. A thin slice is genuinely hard — multi-step reasoning, long-context analysis, agentic coding sessions, multimodal document work.
That thin slice is where Fable 5 earns its rate. Anthropic’s published benchmarks show it leading on exactly these workloads — 80.3% on SWE-Bench Pro for agentic coding and 85.0 on OSWorld-Verified for computer use — while for the routine majority, a model costing twenty times less produces output your users cannot tell apart.
The strategy, then, is not “can we afford Fable 5?” It’s “can we guarantee Fable 5 only sees Fable-5-shaped requests?”
Step two: enforce the tiers at the gateway, not in app code
Teams sometimes try to implement tiering inside their application: if/else statements choosing models, scattered across services, each with its own provider credentials. It works until the third service and the second provider, after which nobody can answer “what are we actually spending per feature?”
The cleaner pattern is to centralize model selection at a gateway layer. Your services all talk to one OpenAI-compatible endpoint; the gateway holds the provider relationships and the routing policy. Calling the premium tier explicitly looks like any other request:
from openai import OpenAI
client = OpenAI(
base_url=”https://api.orcarouter.ai/v1″,
api_key=”YOUR_ORCAROUTER_API_KEY”,
)
response = client.chat.completions.create(
model=”anthropic/claude-fable-5″, # explicit premium tier
messages=[{“role”: “user”, “content”: “Analyze this 300-page filing and extract all covenant terms.”}],
)
And for everything else, adaptive routing picks the cost-optimal model per request automatically, with under 1 millisecond of added latency — so the routine 95% of your traffic flows to economical models without anyone maintaining if/else trees. Teams applying cost-optimal routing across full production traffic typically see total LLM spend drop by around 40%, which in practice is what funds the premium tier: the savings on routine traffic pay for the Fable 5 requests that move the needle.
Because pricing is passed through at provider rates with no markup, the gateway layer itself adds nothing to your unit costs — the 40% is pure routing efficiency, not a discount scheme with strings attached.
Step three: make spend visible per workload
The final piece is observability. When every model call flows through one endpoint under one key, cost attribution stops being forensic accounting. You can see which feature consumes which tier, catch a misrouted endpoint sending chat traffic to a $50/M model before the invoice does, and answer the CFO’s question with a dashboard instead of a spreadsheet archaeology project.
This is also where consolidation compounds: one bill instead of four, one rate-limit policy instead of four, one place to rotate credentials. The operational savings are harder to quantify than the routing savings, but every platform team that has reconciled multi-provider invoices knows they are real.
The bottom line
Claude Fable 5 is worth adopting — million-token context and frontier agentic performance unlock work that simply wasn’t automatable last quarter. The way to adopt it without budget whiplash is discipline by architecture: tier your traffic, enforce the tiers at a gateway, route the routine majority to economical models, and reserve the $50/M rate for requests that genuinely exploit it. Do that, and the frontier tier becomes a scalpel in your stack instead of a tax on every request.