The first time a US bank engineer suggested running customer data on a NoSQL database, the answer involved a regulator, a compliance officer, and a long argument. A decade later, NoSQL is a normal part of the US banking technology stack, with several large institutions running production workloads on MongoDB, Cassandra, DynamoDB, and Redis. The story of how that shift happened, and where the new boundary line settled, is more interesting than the marketing version.
Where NoSQL Databases Sit in the US Banking Stack Today
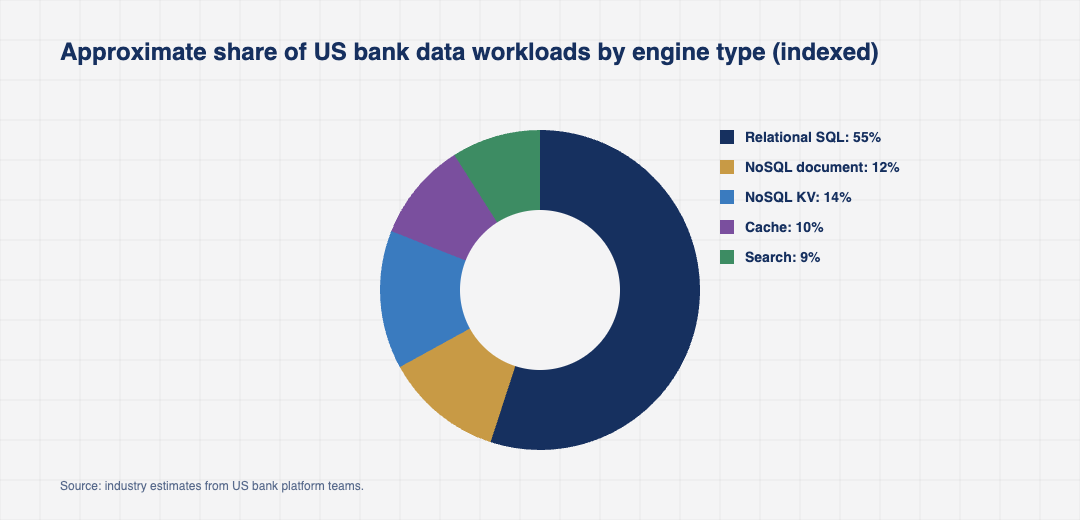
Inside a typical large US bank, NoSQL appears in three categories of workload. The first is high write throughput operational data, including session stores, device telemetry, fraud signal streams, and audit logs. The second is flexible schema customer and product data, where a single document holds a customer profile, account preferences, and embedded sub objects that would otherwise require dozens of relational tables. The third is cached read paths, where Redis or Memcached sits in front of a relational system to absorb the burst load that the relational system cannot handle directly.
None of these workloads have displaced the system of record. The general ledger, the card transaction store, the regulatory data warehouse, and the customer master record at every large US bank still sit on Oracle, IBM Db2, or Microsoft SQL Server. The system of record is where the auditor reads, and where the regulator subpoenas data. NoSQL has stayed in the supporting roles.
The exception is the modern US neobank. Companies like Chime, Varo, and several smaller challengers were built natively on cloud infrastructure with mixed NoSQL and relational stores. Even there, the ledger sits on a relational engine, while customer profile, session, and event data live in NoSQL stores designed for the access pattern.
The Workloads Where NoSQL Has Clear Wins
Three workloads inside US finance have moved decisively to NoSQL.
The first is fraud and risk feature serving. Real time fraud engines need to look up hundreds of features per transaction, return them in single digit milliseconds, and handle peak loads of millions of requests per minute. Key value stores like DynamoDB and Cassandra serve this pattern cleanly. The relational engines that hold the same data for batch analysis are not built for that latency profile.
The second is event sourcing. When a US bank shifts to capturing every change to an entity as an immutable event, the natural store is a partitioned append only log. Apache Kafka holds the stream, and a NoSQL store like Cassandra or DynamoDB holds the materialized view. The pattern shows up in payments processing, identity, and product configuration systems.
The third is content and document workloads. Customer onboarding documents, KYC artefacts, statement files, and product brochures live in document stores or object stores fronted by metadata indexes. The shape of the data does not fit cleanly into relational rows, and the access pattern does not require complex joins.
A fourth NoSQL workload, search and discovery, has settled inside US banks on Elasticsearch and OpenSearch. Customer service consoles, internal knowledge bases, and product search experiences depend on these engines, and they pair well with the rest of the modern data stack rather than competing with the relational core.
How NoSQL Databases Stack Up Against Relational Engines
The comparison inside US finance is rarely a head to head fight. Each engine has a workload it serves best.
Relational engines win on transactional consistency, regulatory traceability, and ad hoc reporting. The auditor can write a SQL query against a relational store and get an answer that matches the financial statements. That is a hard requirement that NoSQL cannot easily replace.
NoSQL wins on high throughput single key access, flexible schema, and horizontal scale at predictable cost. For the workloads that have those characteristics, NoSQL is meaningfully cheaper to operate than forcing a relational engine to do the same job.
The honest picture in 2026 is a federated estate, where each US bank runs both, with clear ownership of which workload lives where, and disciplined data flows between them.
The Friction Points US Bank Teams Still Manage Around NoSQL
Three frictions come up repeatedly.
The first is consistency. Most NoSQL engines offer eventual consistency by default and tunable consistency at a cost. For US bank workloads that need strict serialisability, the engineering team has to make consistency decisions explicit. Getting that wrong shows up as a customer support ticket or, in the worst case, a regulatory finding.
The second is query expressiveness. A NoSQL store optimized for key value lookup does not support the ad hoc analytical query that a finance analyst wants to run. US banks have responded by sinking NoSQL data into a relational warehouse or lakehouse for analytics, but that adds latency and operational overhead.
The third is operational maturity. Running a Cassandra cluster, a MongoDB sharded deployment, or a DynamoDB at bank scale requires deep expertise. The hardest part is not the steady state. It is the recovery from an incident at three in the morning. US banks have hired carefully and invested heavily in the operational backbone around NoSQL, and the cost is a real budget line.
A fourth friction is talent. Engineers who can think across consistency models, partition strategies, and replica topologies are scarce. US banks have built internal training programs and run rotation programs to keep the operational knowledge from clustering in a small number of senior individuals.
Where NoSQL Databases Are Heading in US Finance
Three signals shape the next phase.
The first is the rise of multi model engines. PostgreSQL with JSON columns, Oracle with JSON support, and CockroachDB blur the line between relational and NoSQL. For US bank workloads that need flexible schema with relational guarantees, these multi model engines are an attractive middle ground that several teams have adopted.
The second is serverless and managed NoSQL. AWS DynamoDB on demand, MongoDB Atlas, and Cosmos DB serverless allow US bank engineering teams to provision a NoSQL store without managing the cluster. The trade off is vendor specific behavior and pricing model, both of which require careful capacity planning.
The third is the deepening overlap between operational and analytical workloads. Real time fraud, real time treasury, and intraday liquidity work need data that is both fresh and queryable. The technology stack to deliver that, with NoSQL on the operational side and lakehouse on the analytical side, joined by a streaming layer, has stabilized as the reference architecture inside US banks.
For US bank technology leaders, the question is no longer whether to use NoSQL. It is which workloads belong on which engine, how to keep the estate coherent, and how to manage the operational cost of running a federated data platform.
A fourth signal is the slow movement of regulated workloads onto distributed SQL engines like CockroachDB, Yugabyte, and Google Spanner. These engines offer relational semantics with NoSQL style scalability, and several US banks have started using them for new ledger and customer master deployments where the historical relational engine would have been the default.
NoSQL did not eat the relational database inside US finance, and the original predictions of a single document store running every workload look in retrospect overstated. What did happen is more interesting. NoSQL took on the workloads it was actually built for, the relational engines kept the workloads they were built for, and the resulting estate is more capable than either could have delivered alone. That outcome is the durable one, and it will keep shaping US bank data architecture decisions for at least another decade, and the operational practices that surround it are now part of the standard playbook for any new US financial product launch.