
High-availability system design in U.S. financial software is a mature discipline with a clear set of patterns, but the gap between knowing the patterns and applying them consistently remains wide. The institutions that achieve high availability in production have invested in specific architectural and operational disciplines. The institutions that report high availability without the supporting investment usually live one bad week away from a customer-visible outage that contradicts the reported numbers.
This piece looks at what high-availability system design actually requires in U.S. financial systems, the patterns that work, the patterns that look like high availability without delivering it, and the operational discipline that converts architecture into actual uptime.
Redundancy is necessary, not sufficient
The first design decision in high-availability systems is redundancy at every level: multiple instances of every service, multiple availability zones, multiple regions for the most critical workloads. Redundancy alone does not produce high availability, but the absence of redundancy guarantees its absence. The mature pattern is treating redundancy as the baseline and then layering the disciplines that turn redundancy into actual uptime.
The institutions that confused redundancy with availability usually have multi-region deployments that have never been tested in a region failover. The redundancy is theoretical. The first real failover, when it happens, exposes the configuration drift, monitoring gaps, and operational unfamiliarity that have accumulated. The mature institutions test failovers regularly, on schedules they control rather than on schedules the failures dictate.
Failure-mode analysis as a design input
The second design decision is treating failure modes as inputs to the system design rather than as discoveries during incidents. Mature U.S. financial systems are designed against documented failure modes: instance failures, zone failures, region failures, dependency failures, network partitions, and the slower failure modes like degraded performance under load. Each failure mode has a documented behaviour and a tested response.
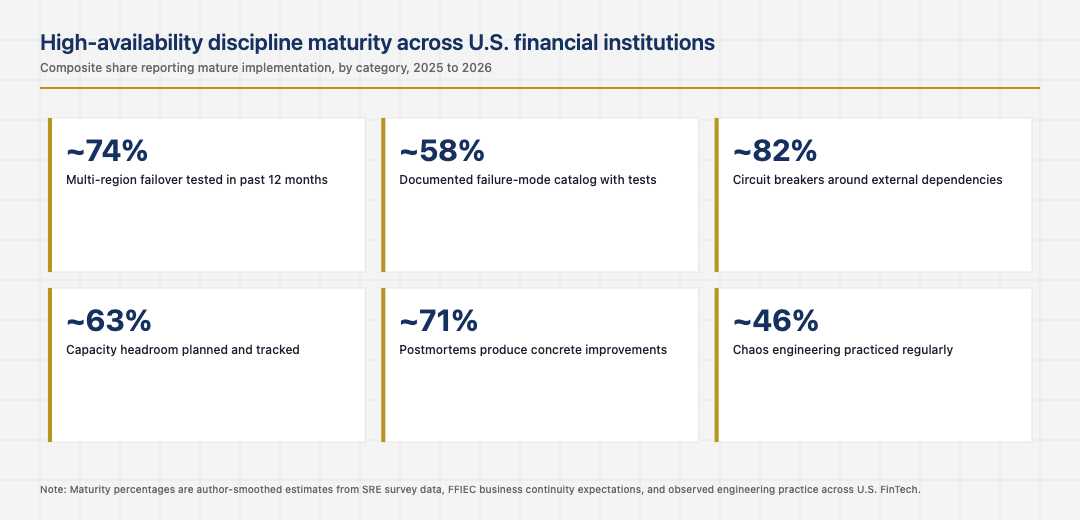
The institutions that work this way have systems that degrade gracefully. The institutions that did not anticipate failure modes usually have systems that work in the happy path and fall over in failure modes that should have been anticipated. The discipline of failure-mode analysis is not glamorous, but it is the difference between architecture that delivers reliability and architecture that hopes for it.
Dependencies are first-class concerns
Every external dependency in a U.S. financial system is a potential single point of failure. Mature designs treat dependencies as first-class concerns: explicit timeouts, circuit breakers, fallback behaviours, and clear semantics for what happens when each dependency is unavailable. The institutions that design for dependency failure handle external outages without customer impact. The institutions that did not have customer impact every time a dependency has a bad day.
The fallback behaviours matter. A payment authorisation system that depends on a fraud-scoring service needs a defined behaviour when the fraud service is unavailable: approve everything, decline everything, or apply a fallback rule. The choice depends on the business semantics. The mature pattern is making the choice deliberately and testing it. The pattern that fails is not making the choice, which usually means the system fails open or fails closed in ways that nobody anticipated.
Capacity planning and the load-induced failure mode
Capacity planning is a quieter input to high availability than redundancy or failure modes, but it matters comparably. Systems that are at capacity have very little margin for the unexpected. Mature U.S. financial systems are run with deliberate capacity headroom that absorbs traffic spikes, gradual growth, and the occasional misbehaving consumer that drives load up unexpectedly.
The institutions that maintain capacity headroom rarely have load-induced failures. The institutions that run at higher utilisation usually have a small number of these failures per year, and the cost of the failures usually exceeds the cost savings from the higher utilisation. The right capacity strategy depends on the workload, but the discipline of measuring, planning, and maintaining headroom is universal.
Operational discipline as the multiplier
The fifth pillar of high availability is operational discipline. Monitoring that surfaces partial degradation, on-call rotations that respond quickly, runbooks that have been exercised, postmortems that produce concrete improvements, and a culture that treats reliability as everyone’s job all multiply the value of the underlying architecture. The institutions that invested in operational discipline alongside their architecture deliver real uptime. The institutions that built strong architectures without the operational layer usually deliver less uptime than the architecture should support.
Read across the full picture, high-availability system design in U.S. finance in 2026 is a mature discipline with specific patterns: redundancy at every level, failure-mode analysis as design input, explicit handling of dependencies, deliberate capacity planning, and operational discipline as the multiplier. The institutions that respect them all deliver reliability. The institutions that miss any one usually deliver less reliability than they report, and the gap shows up in customer-visible incidents that the reported numbers did not predict.
Looking back across the full sweep makes one final point clear. The American financial system has accumulated its strength through the patient layering of standards, institutions, and supervisory expectations on top of an active commercial layer. The application layer captures attention because it is visible and fast-moving. The institutional layer captures durability because it is invisible and slow-moving. Operators who learn to read both layers at once tend to outlast operators who only read the visible one, and the discipline of doing so is not glamorous but it is the discipline that consistently shows up in the firms that compound through multiple cycles instead of just the one they happened to start in.
The same lesson shows up in the founders who quietly build through down cycles that catch the louder ones flat-footed. Reading the institutional rebuild as carefully as the product roadmap is what separates the long-lived operators in 2026 from the ones whose names appear only in retrospectives. The competitive position of the next decade will turn less on the surface features that draw press attention and more on the structural features that draw supervisory attention. The two are increasingly the same set of features, and the operators who recognise that early are the ones who position correctly while the rest are still arguing about whether the rules apply to them.
One last consideration is worth carrying forward. Cross-cycle perspective sharpens any single decision. Looking at how peer ecosystems have handled the same question, what they got right and where they stumbled, almost always reveals something about the decisions that the U.S. system is in the middle of making right now. The operators who travel intellectually as well as commercially tend to make better forecasts about which infrastructure layer will matter most in the next phase, and which segment is being quietly reset under the noise of the daily news. The disciplined version of that practice is what the next ten years of American FinTech will reward most consistently.






































