The most heavily used programming language inside US banks is not Python, not Java, not even COBOL. It is SQL. Every reconciliation, every regulatory filing, every fraud investigation, and every internal report eventually reduces to a query against a relational database. SQL for finance has held its position for more than thirty years, survived the rise of NoSQL, the data lake era, and the lakehouse pitch, and is now starting another decade of dominance for a very practical reason. It works.
Where SQL for Finance Lives Inside a US Institution
Inside a typical US bank, SQL sits in three layers. The first is the operational database layer, where Oracle, IBM Db2, Microsoft SQL Server, and Postgres power the systems that keep day to day banking running. The second is the data warehouse layer, where platforms like Snowflake, Teradata, Databricks SQL, BigQuery, and Redshift hold the historical record that feeds reporting, analytics, and risk modeling. The third is the analyst layer, where individual quants, risk officers, finance teams, and operations leaders write ad hoc queries to answer specific questions.
The volume is significant. A large US bank can process tens of billions of SQL statements per day across its estate, with peak hours running into millions per minute. Most of that volume is automated, generated by applications and pipelines, and a meaningful slice is hand written by humans solving a specific problem in front of them.
What ties these layers together is a common assumption. The data has a shape, the shape is documented in a schema, and the schema can be queried in a language that has not changed materially since the 1990s. For a regulated US institution, that stability is not a side effect. It is the feature that allows compliance officers, auditors, and regulators to read the query and verify that it does what it claims.
The Workloads Where SQL for Finance Has No Real Rival
Three categories of US bank work remain firmly in SQL.
The first is regulatory reporting. Capital ratio reports, liquidity coverage ratios, stress testing submissions, and CCAR filings are all built on SQL pipelines. The reason is straightforward. The data sources are tabular, the joins are well defined, and the auditor needs to be able to follow the logic without learning a new framework. The output gets reviewed by the Federal Reserve and the OCC, and the chain of custody from raw transaction to final number has to be defensible.
The second is fraud and anti money laundering analysis. When a US bank investigator needs to look at every transaction by a customer over the last 90 days, joined against counterparties, geographies, and device fingerprints, the query that produces that view is SQL. The analyst writes it, the platform runs it, and the result lands in a case management system that another analyst opens.
The third is finance and treasury reporting. The general ledger feeds, profitability allocations, intraday liquidity views, and asset liability management reports run on SQL. Every one of these has a deadline, a defined audience, and a level of scrutiny that does not tolerate fuzziness in the underlying logic.
How SQL for Finance Compares to the Alternatives
Several technologies have pitched themselves as the replacement for SQL inside US finance. Each has carved out a niche without displacing the core.
NoSQL databases have taken over for high write, schema flexible workloads like session storage, document management, and certain customer profile services. They have not taken over for analytical workloads, where the lack of standard query semantics and ad hoc joins is a real cost.
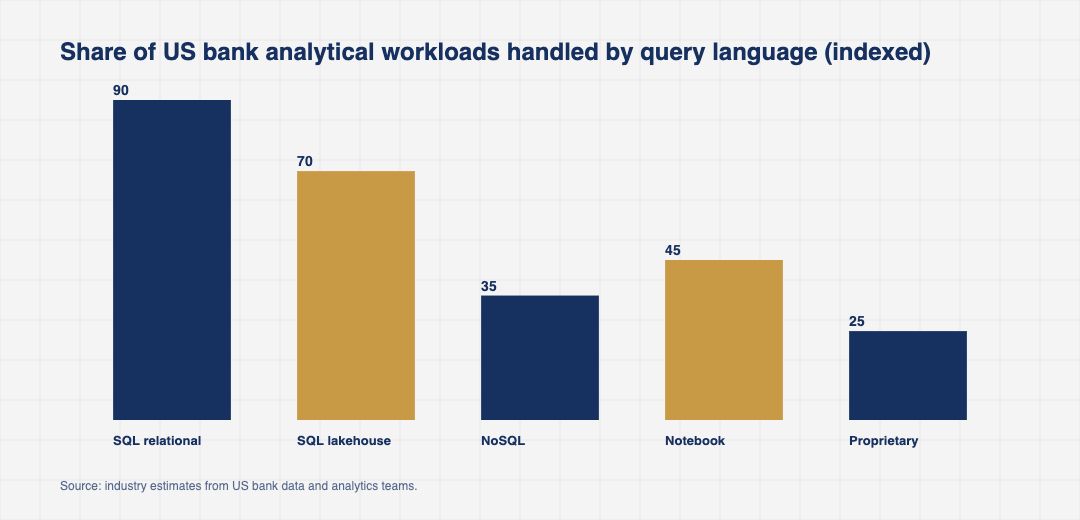
Notebook based analysis in Python and R has taken share in exploratory data science and one off modeling work. For production reporting that has to run on a fixed schedule against a known dataset, SQL remains the default.
Modern lakehouse platforms have effectively done the opposite of replacing SQL. They have brought SQL to the data lake, with engines like Spark SQL, Trino, Presto, and Databricks SQL. The marketing word is lakehouse. The interface is still a SQL query.
A fourth alternative, the operational analytics tier built on stream processors like Flink and Kafka SQL, has started to expand inside US banks. Real time fraud, real time treasury, and intraday liquidity workloads now run on streaming SQL engines. The interface is still recognisable to a relational analyst, which is a deliberate design choice.
The Friction Points That Still Frustrate US Bank SQL Teams
Three frictions are well known and well documented.
The first is performance on very large historical queries. A query that scans ten years of card transactions to look for a fraud pattern can sit on a warehouse for hours and consume significant compute budget. US banks have responded with smarter partitioning, materialized views, query rewrite engines, and aggressive caching, but the cost is real and the line item shows up in technology budgets.
The second is data quality. SQL is only as good as the underlying tables, and US banks run estates with hundreds of source systems, inconsistent codes, and historical anomalies. Most of the engineering time spent on SQL pipelines is not writing the query. It is cleaning the inputs, reconciling the differences, and explaining the result to the person who asked the original question.
The third is the skill gap. Senior SQL engineers who can read an execution plan, tune a complex query, and design a data model are scarce. US banks compete for them with consulting firms, technology companies, and other regulated industries. The mid level talent market is healthier, but the senior end is tight.
Where SQL for Finance Is Heading in the US
Three signals shape the next phase.
The first is the steady expansion of the SQL interface across new platforms. Lakehouses, real time streaming systems, vector databases, and even some operational stores now accept SQL as a first class interface. For US bank analysts who already think in SQL, this lowers the learning cost of every new platform that arrives.
The second is the rise of AI assisted query authoring. GitHub Copilot, internal bank LLMs, and dedicated SQL assistants have started writing first draft queries from natural language prompts. The senior analyst still reviews, tunes, and validates the result, but the time saved on routine queries is measurable.
The third is the growing investment in semantic layers. Tools like dbt, Cube, and proprietary equivalents allow US bank teams to define business metrics once, in version controlled SQL, and reuse them across reports and dashboards. The semantic layer is how the next generation of SQL work avoids the inconsistency that plagued the last generation.
For US bank technology leaders, the question is not whether to invest in SQL. It is how to keep the SQL estate coherent, how to invest in the platforms that make it faster, and how to keep the people who write it engaged in a market that pays well for the skill.
A fourth signal is the deepening role of SQL in regulatory observability. US bank supervisors increasingly expect that a bank can produce, on short notice, queries that demonstrate compliance with a specific rule against the actual production data. The infrastructure to do this without burdening operational systems is now a defined investment category inside large US banks.
The replacement for SQL inside US finance has been forecast many times and has not arrived. The reason is not that better technology does not exist. It is that SQL is the language in which the bank actually thinks about its data, and replacing it would mean rewiring the way every analyst, regulator, and auditor reads the same numbers. That kind of replacement is rare, and SQL for finance is going to keep doing the work for at least another decade.