
Natural language processing in U.S. finance has crossed a meaningful threshold in the past two years. The combination of large language models, financial-domain fine-tuning, and the operational maturity to deploy them in regulated environments has moved NLP from a research capability into a production capability. The institutions that built the supporting infrastructure are extracting real value. The institutions that did not are watching their competitors capture document-processing efficiency that should have been theirs.
This piece looks at where NLP is delivering value in U.S. finance in 2026, the categories that have proven out, the deployment disciplines that distinguish productive programs, and the supervisory considerations that NLP deployment now has to absorb.
Document understanding as the dominant use case
The single largest NLP use case in U.S. finance is document understanding. Loan applications, KYC packets, regulatory filings, insurance claims, contracts, and the long tail of structured documents that financial institutions process at high volume all benefit from NLP-driven extraction, classification, and summarisation. The institutions that deployed document understanding models at scale captured operational efficiency that the institutions still using manual review have not.
The cost of building document understanding pipelines is real, particularly for the document types specific to each institution. The benefit accumulates across every document the pipeline processes. The institutions that took the upfront cost are now extracting it through reduced manual review time, faster cycle times, and better consistency in the extracted information. The institutions that did not are still depending on manual review at scale, which limits both throughput and consistency.
Customer interaction analysis as a quieter use case
Customer interaction analysis is a second NLP use case that has matured significantly. Call transcription, sentiment analysis, complaint classification, and intent detection on customer-service interactions all benefit from NLP. The institutions that built these capabilities at scale have visibility into customer experience that the institutions that did not lack. The visibility translates into faster identification of product issues, more proactive complaint resolution, and better feedback into product development.
The discipline that makes this work is treating the NLP outputs as inputs to operational workflows rather than as standalone analytics. The institutions that integrated the outputs into their case management, escalation, and product feedback processes capture the operational benefit. The institutions that produced the analytics without the workflow integration usually have analytical outputs that demonstrate insight without driving action.
Compliance and the regulatory disclosure use case
NLP applied to regulatory disclosure analysis has become standard practice at larger U.S. financial institutions. The technique allows institutions to monitor regulatory updates, extract changes in supervisory expectations, classify the operational impact of new guidance, and automate the production of internal analyses that previously took compliance staff days to assemble. The institutions that built these capabilities respond faster to regulatory change than the institutions that depend on manual analysis.
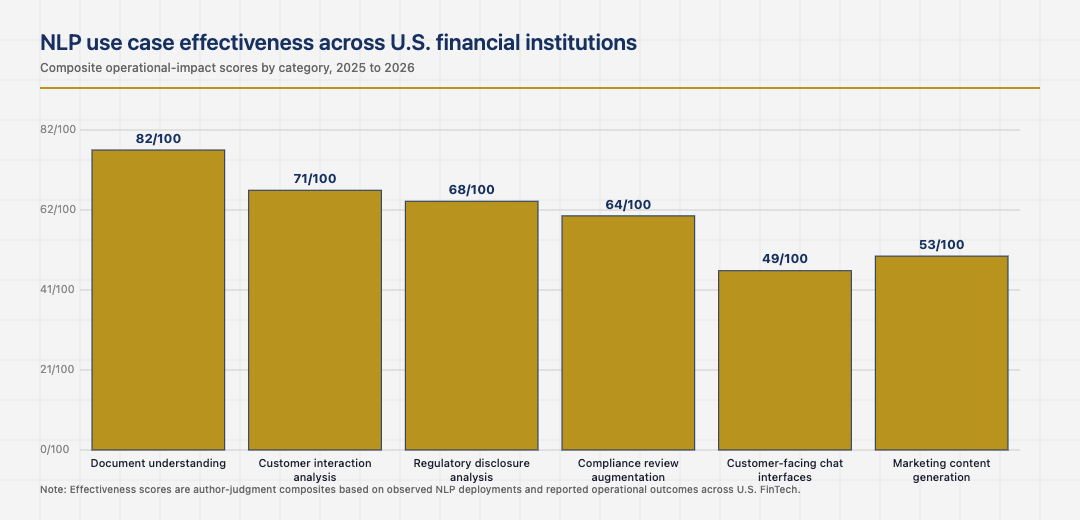
The discipline here is treating NLP as an augmentation rather than a replacement. The compliance staff still make the substantive judgments. The NLP reduces the time it takes to assemble the information they need to make those judgments. The institutions that respect this division of labour capture the efficiency benefit while keeping the supervisory defensibility. The institutions that try to fully automate the substantive judgments usually find themselves either restricted by their supervisors or producing weak analyses that the supervisors do not accept.
Model risk management for language models
Model risk management for language models is harder than model risk management for traditional statistical models. The models are larger, the training data is broader, and the outputs are less obviously auditable. The institutions that extended their SR 11-7 frameworks to cover language models cleanly are deploying NLP at scale. The institutions that treated language models as a separate category outside the existing framework usually have either restricted deployments or a parallel governance process that does not align with the institution’s broader model risk management.
The mature pattern is treating language models as models, applying the existing model risk management discipline with the appropriate adaptations for the technical specifics, and producing the same kinds of validation and monitoring evidence that any other model produces. The institutions that took this approach early are now well-positioned for the continuing wave of language model deployment.
The next phase of NLP in U.S. finance
The next phase is shaped by the integration of language models with structured data systems, the maturation of vector retrieval infrastructure, and the deployment of agent-style workflows that combine NLP with other capabilities. The institutions that built strong document understanding, customer interaction analysis, and compliance NLP foundations are well-positioned to absorb these changes. The institutions that have not are starting from behind on each new layer.
Read across the full picture, NLP in U.S. finance in 2026 is a settled production capability with specific patterns that distinguish productive programs from sprawling ones. Focus on document understanding as the dominant use case, customer interaction analysis as the quieter one, NLP-augmented compliance work, and model risk management adapted for language models are the patterns that compound. The institutions that respect them deliver real efficiency gains. The institutions that miss any one usually deliver NLP demos that do not translate into operational change.
Looking back across the full sweep makes one final point clear. The American financial system has accumulated its strength through the patient layering of standards, institutions, and supervisory expectations on top of an active commercial layer. The application layer captures attention because it is visible and fast-moving. The institutional layer captures durability because it is invisible and slow-moving. Operators who learn to read both layers at once tend to outlast operators who only read the visible one, and the discipline of doing so is not glamorous but it is the discipline that consistently shows up in the firms that compound through multiple cycles instead of just the one they happened to start in.
The same lesson shows up in the founders who quietly build through down cycles that catch the louder ones flat-footed. Reading the institutional rebuild as carefully as the product roadmap is what separates the long-lived operators in 2026 from the ones whose names appear only in retrospectives. The competitive position of the next decade will turn less on the surface features that draw press attention and more on the structural features that draw supervisory attention. The two are increasingly the same set of features, and the operators who recognise that early are the ones who position correctly while the rest are still arguing about whether the rules apply to them.
One last consideration is worth carrying forward. Cross-cycle perspective sharpens any single decision. Looking at how peer ecosystems have handled the same question, what they got right and where they stumbled, almost always reveals something about the decisions that the U.S. system is in the middle of making right now. The operators who travel intellectually as well as commercially tend to make better forecasts about which infrastructure layer will matter most in the next phase, and which segment is being quietly reset under the noise of the daily news. The disciplined version of that practice is what the next ten years of American FinTech will reward most consistently.
Last updated: June 17, 2026


































