Time series forecasting in U.S. finance is one of the older quantitative disciplines, with classical statistical methods dating back decades and modern machine learning methods now firmly in production. The interesting questions are no longer about which technique is theoretically best but about which combination of techniques produces reliable forecasts at the tractable computational cost the operational use case requires.
This piece looks at where time series forecasting in U.S. finance has settled in 2026, the methods that work in production, the operational disciplines that distinguish productive forecasting programs from sprawling ones, and the use cases that consistently deliver value.
The classical methods are still in production
ARIMA, exponential smoothing, and structural time-series methods are still in production at U.S. financial institutions because they work, are well-understood, and are inexpensive to deploy. The institutions that adopted modern machine learning methods without retiring their classical methods usually find that the classical methods continue to handle most of the forecasting workload. The newer methods earn their keep on specific use cases where they meaningfully outperform.
The discipline here is honest evaluation. Many use cases do not need modern machine learning. The institutions that respect this evaluation deploy the right tool for each use case. The institutions that adopt modern methods universally usually have higher infrastructure costs without proportional accuracy gains.
The biggest single forecasting metric in U.S. finance
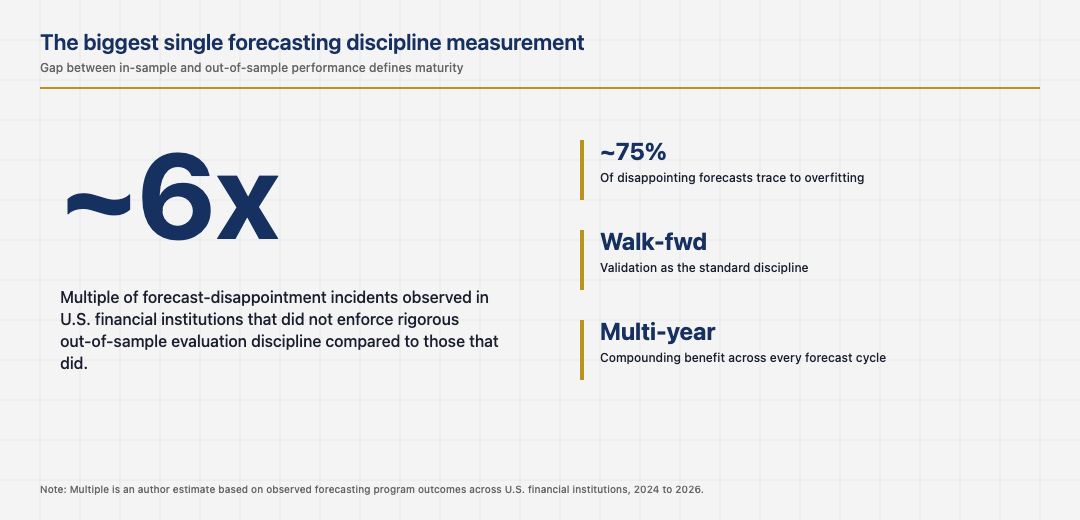
The single most important measurement in U.S. financial forecasting is the gap between in-sample and out-of-sample performance. Models that look strong in-sample and weak out-of-sample have overfit to historical patterns that will not repeat. The institutions that built rigorous out-of-sample evaluation discipline produce forecasts that hold up in production. The institutions that did not produce forecasts that work in backtesting and disappoint in operation. The reduction in production-disappointment incidents after rigorous out-of-sample discipline lands is consistently large across institutions that have measured it. The walk-forward evaluation pattern, where the model is repeatedly tested on data it has not seen, is now the standard discipline at the strongest forecasting teams.
Modern machine learning and the structured tabular case
Modern machine learning methods, particularly gradient boosting adapted for time-series, have proven productive in U.S. financial forecasting where the data has rich structured features alongside the time-series component. Forecasting transaction volumes by merchant category, predicting branch traffic by hour and day of week, and modelling cash demand at ATM locations all benefit from gradient boosting models that incorporate the seasonal and event-driven features that classical methods handle less naturally.
The institutions that adopted these methods for the right use cases improved their forecasting accuracy meaningfully. The institutions that adopted them for use cases where simpler classical methods would have sufficed paid the additional infrastructure cost without capturing the accuracy benefit. The discipline of matching the method to the use case is unglamorous and consequential.
Probabilistic forecasting and the decision-support use case
Probabilistic forecasting, which produces a distribution over future outcomes rather than a single point estimate, has become increasingly important in U.S. financial decision support. Capacity planning, liquidity management, and stress testing all benefit from understanding the range of possible outcomes rather than only the central estimate. The institutions that adopted probabilistic forecasting methods deliver forecasts that decision-makers can use to size buffers and tolerances appropriately.
The institutions that continued to deliver only point forecasts usually have decision-makers who request additional context that the forecasting team has to assemble manually. The investment in probabilistic methods is modest. The benefit, in the quality of decisions that depend on the forecasts, is substantial. The institutions that internalised this early are now ahead.
The next phase of forecasting in U.S. finance
The next phase is shaped by the integration of foundation models for time-series forecasting, the maturation of probabilistic methods, and the continuing pressure on institutions to extract operational value from their forecasting investments. The institutions that built strong foundations in classical methods, modern machine learning, and probabilistic forecasting will absorb the changes cleanly. The institutions still relying on a single method will continue to face the choice between accepting the method’s limitations and undertaking a costly modernisation.
Read across the full picture, time series forecasting for U.S. finance in 2026 is a mature discipline with specific patterns: classical methods retained where they work, modern methods deployed where they outperform, rigorous out-of-sample evaluation, and probabilistic forecasting where decision-makers need range information. The institutions that respect them deliver forecasts that drive better operational decisions. The institutions that miss any one usually have forecasting portfolios with mixed reliability that decision-makers learn to discount.
Looking back across the full sweep makes one final point clear. The American financial system has accumulated its strength through the patient layering of standards, institutions, and supervisory expectations on top of an active commercial layer. The application layer captures attention because it is visible and fast-moving. The institutional layer captures durability because it is invisible and slow-moving. Operators who learn to read both layers at once tend to outlast operators who only read the visible one, and the discipline of doing so is not glamorous but it is the discipline that consistently shows up in the firms that compound through multiple cycles instead of just the one they happened to start in.
The same lesson shows up in the founders who quietly build through down cycles that catch the louder ones flat-footed. Reading the institutional rebuild as carefully as the product roadmap is what separates the long-lived operators in 2026 from the ones whose names appear only in retrospectives. The competitive position of the next decade will turn less on the surface features that draw press attention and more on the structural features that draw supervisory attention. The two are increasingly the same set of features, and the operators who recognise that early are the ones who position correctly while the rest are still arguing about whether the rules apply to them.
One last consideration is worth carrying forward. Cross-cycle perspective sharpens any single decision. Looking at how peer ecosystems have handled the same question, what they got right and where they stumbled, almost always reveals something about the decisions that the U.S. system is in the middle of making right now. The operators who travel intellectually as well as commercially tend to make better forecasts about which infrastructure layer will matter most in the next phase, and which segment is being quietly reset under the noise of the daily news. The disciplined version of that practice is what the next ten years of American FinTech will reward most consistently.