You may know Gremlin as the company built by ex Netflix and Amazon engineers to make chaos engineering a standardized practice. Their fun mascot and taglines like “break things on purpose” generated a ton of buzz and also made teams worldwide re-think how they approach reliability.
Mainly – that teams who care about reliability deeply should take time to find potential weaknesses before they impact customers, not just get better at responding to problems after they’ve already happened. Put another way: if a good incident response solution is like having a good doctor on call, then Gremlin’s reliability testing platform is like having a good diet…why wait until problems are so bad that you need a doctor in the first place?
This is especially true in the AI era. More and more teams are vibe coding applications full of vulnerabilities and performance issues. And when things get really bad – like an entire datacenter region shuts down – how can you verify that your system is resilient enough to handle it? If you wait until it’s too late, you and your customers are in for a world of pain (and lost revenue).
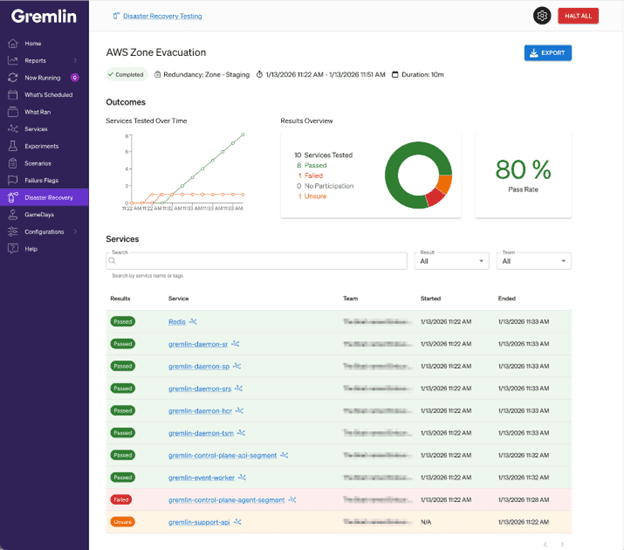
That’s why today Gremlin is launching Disaster Recovery Testing: a new product built to safely and efficiently test zone, region, and datacenter evacuations and failovers. These large-scale tests ensure businesses maintain digital resilience and business continuity when faced with cloud migrations, compliance concerns, and catastrophic events.
There were multiple high-profile cloud outages in 2025, such as the AWS and Azure outages late last year impacting over 100,00 companies and exposing why business leaders relying on single clouds or regions must rethink their business continuity strategy.
“Enterprises can leverage Disaster Recovery Testing to conduct datacenter-scale tests
across their digital infrastructure that traditionally require thousands of engineering
hours,” stated Kolton Andrus, Founder and CEO of Gremlin. “With just a few clicks
within Gremlin, teams can simulate complex disaster scenarios, validate their failover
systems, and ensure compliance with rigorous standards.”
Key features of Gremlin Disaster Recovery include:
- Company-Wide Testing: Organizations can simulate the impact of major failures
such as zone and region outages across the entire organization from a central
command center.
- Enhanced Safety Measures: Health Checks automatically halt tests and return
services to a healthy state to guarantee system integrity during testing.
- Reliability Reports: The Gremlin platform produces detailed reports on service
performance that identify weaknesses and prioritize remediation efforts. As scaling companies prepare to IPO, Gremlin’s reporting capabilities can assist in proving digital resilience for S-1 filings for the SEC.
Gremlin has collaborated with dozens of Fortune 1000 companies, including four out of
the top five U.S. banks, to facilitate effective zone and region-level failover tests. Sreekanth Rajagopal, Head of Non-Functional Testing at Visa Cross-Border Solutions, writes that “businesses and consumers worldwide expect Visa’s applications to be continuously available and deliver strong performance, even during major outages or provider failures. Disaster Recovery Testing gives us a fast, centralized way to continuously validate and demonstrate our resilience to catastrophic events so we can stay prepared and keep services online.”
With teams unleashing AI across the globe, it’s hard to say exactly what the impact of all that code velocity will be in 2026. It’s safe to say that keeping all of that code secure and performant will be a major challenge, and that more major outages are inevitable. So the real question is: will you be ready.