A subscription-based meal kit delivery company processing 2.8 million orders monthly across North America discovers that its marketing technology stack has created an increasingly unsustainable data architecture. Customer data lives in six different systems: a CDP that holds behavioural profiles, a marketing automation platform managing email engagement, a customer service system tracking support interactions, a billing platform recording subscription changes, a mobile app analytics tool capturing in-app behaviour, and a product analytics platform monitoring recipe selection patterns. Each system maintains its own copy of customer data, synchronised through a brittle network of API integrations and scheduled batch transfers that introduce latency ranging from 15 minutes to 24 hours. When the data engineering team audits the synchronisation pipeline, they discover that 12 percent of customer profiles have conflicting attribute values across systems, the total cost of maintaining integration infrastructure exceeds $340,000 annually, and the marketing team cannot execute campaigns requiring data from more than two systems without a three-week engineering sprint to build custom data pipelines. The company migrates to a data warehouse-native marketing architecture built on Snowflake, where all customer data converges into a single, governed repository and marketing tools access data directly through reverse ETL pipelines rather than maintaining independent copies. Within six months, campaign setup time decreases from weeks to hours, data consistency reaches 99.7 percent across all activation channels, and the company eliminates $280,000 in annual integration maintenance costs while enabling marketing use cases that were previously impossible due to data fragmentation.
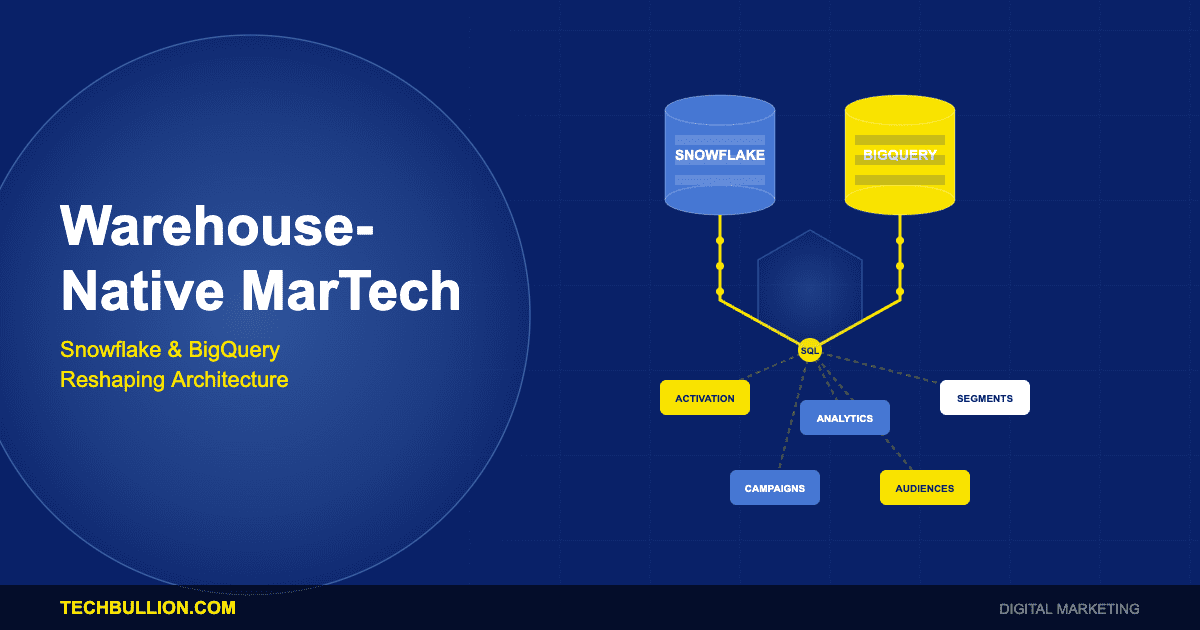
The Shift to Warehouse-Native Architecture
The global cloud data warehouse market reached $26.8 billion in 2024, according to Mordor Intelligence, with marketing emerging as one of the fastest-growing use cases for warehouse-native data activation. Snowflake, Google BigQuery, Amazon Redshift, and Databricks have collectively created an ecosystem where organisations can consolidate all business data into governed, scalable repositories that serve as the single source of truth for both analytics and operational activation.
The traditional MarTech architecture, where each marketing tool maintains its own data store synchronised through point-to-point integrations, is approaching a breaking point for organisations managing complex customer relationships across multiple channels. Each new tool added to the stack multiplies integration complexity, introduces additional points of data inconsistency, and increases the engineering burden required to maintain synchronisation. The warehouse-native approach inverts this architecture by establishing the data warehouse as the central hub from which all tools receive data, eliminating the need for tool-to-tool integration.
The convergence of warehouse-native marketing with data clean room technology is creating particularly powerful capabilities where first-party data stored in warehouses can be activated for audience collaboration and measurement without moving sensitive data outside governed environments.
| Metric | Value | Source |
|---|---|---|
| Cloud Data Warehouse Market (2024) | $26.8 billion | Mordor Intelligence |
| Reverse ETL Market Growth | 45%+ CAGR | Gartner |
| Average MarTech Integration Points | 15-25 per enterprise | Chiefmartec |
| Data Quality Issues from Multi-System Sync | 10-15% of records | Forrester |
| Cost Reduction from Warehouse-Native Approach | 30-60% | Hightouch |
| Snowflake Marketing Data Cloud Users | 1,000+ | Snowflake |
Reverse ETL and Data Activation
Reverse ETL represents the critical technology layer that makes warehouse-native marketing operationally viable. While traditional ETL (extract, transform, load) moves data from operational systems into warehouses for analysis, reverse ETL moves modelled data from warehouses back into operational tools where it can be acted upon. This bidirectional data flow enables marketing teams to build sophisticated audience segments, predictive models, and attribution analyses within the warehouse using SQL and data science tools, then push the results directly to advertising platforms, email systems, CRMs, and personalisation engines.
The technical architecture of reverse ETL platforms monitors warehouse tables and views for changes, then synchronises updated records to connected destinations on configurable schedules ranging from real-time streaming to daily batch updates. Leading reverse ETL platforms including Hightouch, Census, and RudderStack provide pre-built connectors to hundreds of marketing and advertising platforms, enabling data teams to activate warehouse data without building custom integration code.
Composable CDPs represent the architectural evolution of customer data platforms toward warehouse-native operation. Rather than ingesting and storing customer data in a separate CDP system, composable CDPs operate directly on data that remains in the warehouse, applying identity resolution, audience segmentation, and activation logic through a thin application layer that leverages the warehouse’s compute and storage resources. This approach eliminates the data duplication and synchronisation overhead of traditional CDPs while providing the same marketing functionality.
Key Warehouse-Native Marketing Platforms
| Platform | Category | Key Differentiator |
|---|---|---|
| Hightouch | Reverse ETL / Composable CDP | Leading reverse ETL with visual audience builder and 200+ destination connectors |
| Census | Reverse ETL / Data Activation | Operational analytics platform with warehouse-native audience syncing |
| Snowflake Marketing Data Cloud | Data Cloud | Native data sharing, clean rooms, and partner data marketplace |
| Google BigQuery + Ads Data Hub | Analytics + Activation | Direct integration with Google advertising ecosystem and privacy-safe analytics |
| dbt (data build tool) | Data Transformation | SQL-based transformation layer enabling marketing data modelling in-warehouse |
| RudderStack | Warehouse-Native CDP | Event streaming and reverse ETL with warehouse as the core data store |
Marketing Use Cases Enabled by Warehouse-Native Architecture
The warehouse-native approach enables marketing use cases that are impractical or impossible within traditional architectures where data is siloed across multiple tools. Unified customer scoring models that incorporate behavioural data, transaction history, support interactions, and product usage into a single propensity score can be built using SQL and machine learning within the warehouse, then activated across all marketing channels simultaneously through reverse ETL. Cross-channel attribution models that connect advertising exposure data, website behaviour, email engagement, and offline conversions can operate on complete datasets rather than the partial views available to individual marketing tools.
Real-time personalisation powered by warehouse-native architecture delivers consistent customer experiences across channels because every touchpoint draws from the same data source. When a customer contacts support about a billing issue, the marketing automation system immediately reflects this interaction in its next communication decision because both systems read from the same warehouse rather than waiting for asynchronous data synchronisation. The integration with cross-channel orchestration platforms enables warehouse-native audience definitions to drive coordinated campaigns across email, advertising, mobile, and web channels from a single data foundation.
Data Governance and Privacy in Warehouse-Native Marketing
Warehouse-native marketing architectures provide significant advantages for data governance and privacy compliance because data remains in a single, centrally governed environment rather than being replicated across dozens of marketing tools with varying security postures and access controls. Column-level access policies within modern data warehouses enable fine-grained control over which teams and applications can access specific data attributes, ensuring that personally identifiable information is only exposed to systems and users with explicit authorisation.
Data lineage tracking within the warehouse provides complete visibility into how customer data flows from ingestion through transformation to activation, creating the audit trails that privacy regulations like GDPR and CCPA require. When a customer exercises their right to data deletion, the warehouse-native approach simplifies compliance because data exists in a single location rather than requiring deletion across every tool that holds a copy. Row-level security policies can enforce geographic data residency requirements, ensuring that customer data from specific regions is only processed within compliant jurisdictions without requiring separate infrastructure for each market.
The combination of warehouse-native architecture with privacy-enhancing computation techniques enables organisations to build and activate marketing models on sensitive data without exposing individual records. Differential privacy applied at the query level ensures that audience segments and analytics outputs do not reveal information about specific customers, while secure computation capabilities within warehouses enable collaborative analytics between organisations without sharing raw data. These privacy capabilities position warehouse-native architectures as the preferred infrastructure for marketing organisations that must balance personalisation effectiveness with increasingly stringent privacy requirements.
The Future of Warehouse-Native Marketing
The trajectory of warehouse-native marketing through 2029 will be defined by the convergence of data warehouses with AI/ML platforms that enable marketers to build, deploy, and operationalise predictive models directly within warehouse environments. The integration of generative AI with warehouse-native architectures will enable natural language interfaces where marketers query and activate data through conversational prompts rather than SQL, democratising access to sophisticated data operations. The evolution toward real-time warehouse capabilities will narrow the latency gap between batch-oriented warehouse processing and the streaming data requirements of real-time personalisation and bidding applications. Organisations that invest in warehouse-native marketing architecture today are building the data foundation that enables their teams to operate with complete, consistent, and governed customer data across every marketing application.
Data from Statista’s digital market outlook shows that global digital spending continues to grow at double-digit rates, with mobile channels accounting for an increasingly dominant share of total transactions.
PwC’s analysis of financial services trends through 2025 highlights the convergence of technology and media as a defining dynamic, with data-driven personalisation becoming the primary competitive differentiator.