Drawing on enterprise data platform design experience, Gayatri Tavva, Distinguished Lead Data Engineering Architect specializing in AI-ready data infrastructure, explores the architectural patterns required to build scalable data systems capable of supporting analytics, machine learning, and generative AI workloads.
AI workloads and exponential data growth have raised the cost of architectural shortcuts. This article examines the design decisions that separate data platforms scaling gracefully from those requiring re-engineering every eighteen months: layered storage contracts, event-driven ingestion, AI-native serving, and automated governance. These are production-validated patterns running at scale in regulated industries today.
1. Why Architectural Shortcuts Now Appear on Your AWS Bill
Architectural shortcuts used to be slow-burn problems. An over-provisioned warehouse or a poorly partitioned S3 bucket might waste money quietly, but the blast radius was contained. That is no longer true. In the AI era, every shortcut appears as a measurable cost anomaly on the monthly AWS bill: a vector index built on the wrong storage primitive degrades RAG retrieval precision; a training pipeline unable to replay historical feature state ships a biased model; a Redshift cluster sized for peak BI load surfaces as a six-figure line item after running at 8 percent utilization every weeknight.
The stakes have shifted because the consumers of data infrastructure have changed. Three years ago, the primary consumer was a BI analyst querying a warehouse. Today, that same data estate feeds inference endpoints serving millions of users, nightly model retraining jobs, and autonomous agents reading and writing back to operational stores. Each consumer has different latency, freshness, and consistency requirements. A single monolithic architecture cannot satisfy all of them without expensive compromises.
This article covers the high-leverage architectural decisions separating platforms that scale gracefully from those requiring re-engineering every eighteen months: storage contracts, ingestion topology, open table formats, AI-native serving, governance automation, and the cost patterns determining whether the system remains economically viable at ten times current data volume.
2. Foundational Design Principles
Before examining specific services, it is worth anchoring the architecture in principles that remain stable even as AWS releases new capabilities.
2.1 Decouple Storage from Compute
The single most impactful architectural decision is ensuring that your storage layer (Amazon S3) operates independently of any compute engine. This separation means you can swap Spark on Amazon EMR for Amazon Managed Service for Apache Flink, or query the same S3 prefix with both Amazon Athena for ad-hoc analysis and Amazon Redshift Spectrum for BI workloads, without rewriting pipelines.
2.2 Design for Eventual Consistency at Scale
Distributed systems on AWS, particularly those spanning multiple Availability Zones, are eventually consistent by design. Architects must embrace this reality rather than fight it. Idempotent writes, checkpointed Kinesis consumers, and DynamoDB conditional expressions are not optional hardening steps; they are first-class design patterns for any system expecting millions of events per day.
2.3 Make Cost a First-Class Architectural Concern
AWS tagging taxonomies, AWS Cost Explorer anomaly detection, and per-service billing dashboards should be wired into architecture reviews from day one. A Redshift RA3 cluster left running at 5% utilization during off-peak hours is a governance failure, not a technical one.
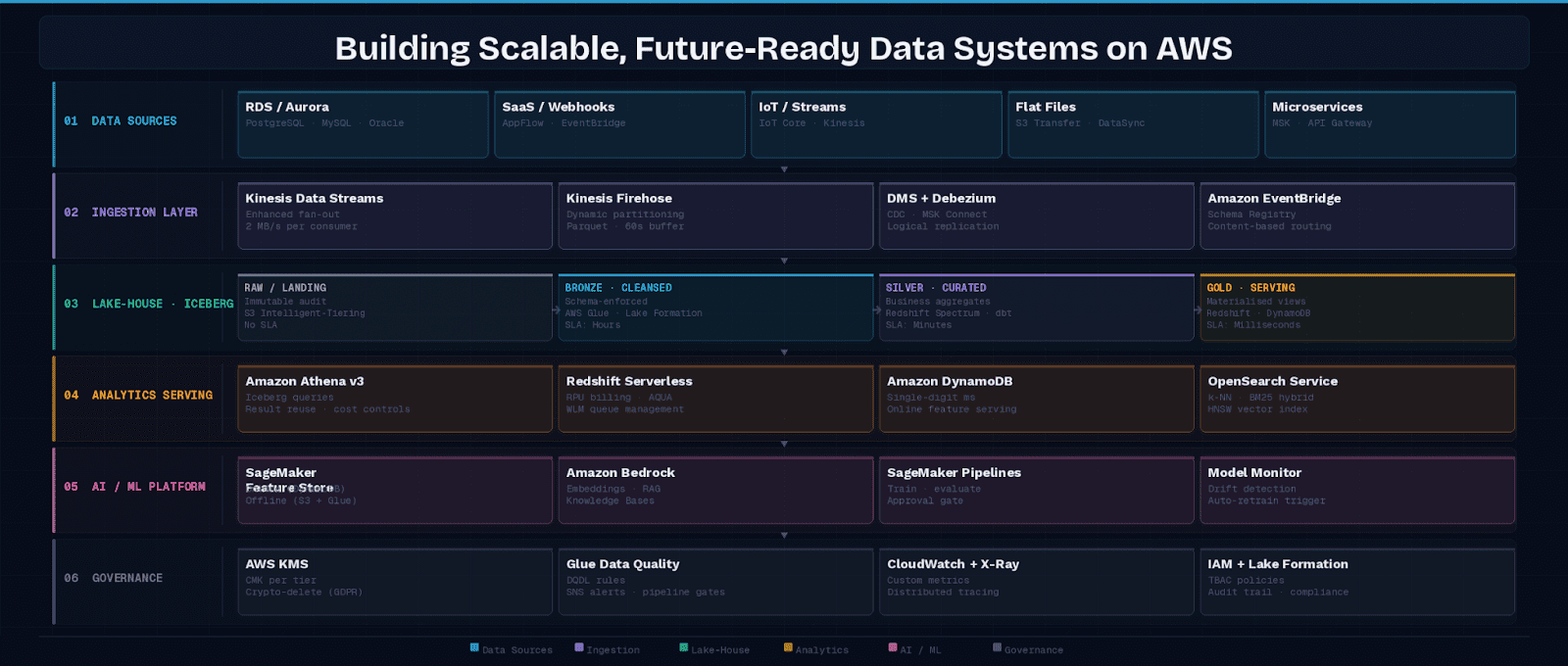
3. The Layered Lake-House Architecture
The lake-house pattern reconciles the flexibility of a data lake with the performance guarantees of a data warehouse. On AWS, the canonical implementation uses four logical zones, each backed by S3. The table below maps each zone to its purpose, primary services, and a concrete data example:
| Zone | Purpose | AWS Services | Latency SLA | Example Data |
|---|---|---|---|---|
| Raw / Landing | Unmodified ingested data; immutable audit trail | S3 Intelligent-Tiering, Kinesis Firehose | No SLA; archive only | Clickstream JSON from Firehose |
| Cleansed / Bronze | Validated, de-duplicated, schema-enforced records | AWS Glue, Lake Formation, Iceberg on S3 | Hours | Parsed page-view events, nulls removed |
| Curated / Silver | Business-domain aggregates ready for consumption | Redshift Spectrum, dbt on Glue, EMR Serverless | Minutes | Daily active user counts per region |
| Serving / Gold | Materialized views optimized for specific query patterns | Redshift, DynamoDB, ElastiCache, OpenSearch | Milliseconds | Real-time product recommendation scores |
3.1 Apache Iceberg as the Unifying Table Format
One of the most consequential recent shifts in cloud data architecture is the adoption of open table formats. Apache Iceberg, now natively supported by Amazon Athena, Amazon EMR, and AWS Glue Data Catalog, provides ACID transactions, schema evolution, and time-travel queries directly on S3, capabilities previously requiring a full warehouse engine.
Organizations standardizing on Iceberg gain engine independence: the same table can be queried by Athena for cost-sensitive ad-hoc work, Spark on EMR for heavy transformation, and Flink for streaming CDC updates, all without data duplication.
3.2 Streaming vs. Batch: Choosing the Right Ingestion Path
A common architectural mistake is treating real-time streaming as universally superior to batch ingestion. The correct answer depends on downstream latency requirements and cost tolerance:
- Use streaming — Kinesis Data Streams: for sub-second delivery to real-time dashboards, fraud detection models, or session personalization engines.
- Use Firehose — Kinesis Firehose: for micro-batch delivery (60-second windows) to S3, Redshift, or OpenSearch with built-in format conversion.
- Use batch — AWS Glue / EMR Serverless: for large historical loads, complex joins, or ML feature engineering where latency tolerance exceeds five minutes.
4. Ingestion Topology: Choosing the Right Pattern Before Writing Code
The most expensive ingestion mistakes are not bugs; they are topology mismatches discovered six months after go-live. Teams defaulting to Kinesis for everything end up with 60-second Firehose buffers when they needed sub-second delivery, or Lambda-per-record costs ballooning as volume scales. The right entry point is a structured decision about what drives the ingestion requirement.
Start with three diagnostic questions: What is the maximum tolerable lag between source event and query availability? What happens if a record is delivered twice? And does the downstream consumer need to replay history? The answers map directly to a topology:
4.1 Sub-Second Latency with Fan-Out Requirements
When a fraud scoring model, session personalization engine, or real-time bidding system needs data within milliseconds of the source event, Kinesis Data Streams with enhanced fan-out consumers is the correct primitive.
Enhanced fan-out allocates dedicated throughput of 2 MB/second per consumer regardless of how many other consumers share the shard. This eliminates the head-of-line blocking that plagues standard GetRecords polling. Shard capacity planning is critical: under-sharded streams throttle producers silently, degrading latency without surfacing obvious errors.
4.2 Near-Real-Time with Guaranteed Delivery
The majority of enterprise event streams (clickstream, application logs, IoT telemetry, SaaS webhooks) do not need sub-second delivery. They need reliable, ordered, cost-efficient delivery with format normalization.
Amazon Kinesis Data Firehose with dynamic partitioning is purpose-built for this band. Dynamic partitioning allows Firehose to extract a partition key from the payload (such as customer_id, event_type, or region) and route records into S3 key prefixes matching Athena and Iceberg partition layouts. This eliminates a post-ingest repartition step that typically adds 30 to 90 minutes of pipeline latency.
4.3 CDC Streams from Relational Sources
Replicating operational databases into the lake without full-table exports requires change data capture (CDC). AWS Database Migration Service covers the common cases: RDS PostgreSQL, Aurora MySQL, and Oracle, with managed replication instances and a familiar console workflow.
The underappreciated configuration detail is supplemental logging on the source. Without row-level supplemental logging enabled on Oracle, or logical replication slots on PostgreSQL, DMS cannot capture before/after values for UPDATE operations, producing incomplete change records that corrupt downstream aggregations.
For organizations running multi-tenant databases or sources outside AWS entirely, Debezium on Amazon MSK Connect provides CDC with greater configurability. MSK Connect manages the Kafka Connect worker fleet, auto-scales connector tasks, and integrates with AWS Secrets Manager for credential rotation, removing the operational overhead that previously made self-managed Debezium a significant maintenance burden.
4.4 EventBridge as the Cross-Service Integration Backbone
The patterns above assume you control the producer. For SaaS sources, cross-account events, and microservice-to-data-lake flows, Amazon EventBridge acts as the schema-aware routing layer decoupling producers from consumers entirely. EventBridge Schema Registry enforces data contracts at the integration boundary, catching payload shape regressions before they propagate into the lake. Its content-based routing rules allow a single event source to simultaneously populate a Kinesis stream, an SQS queue, and a Firehose delivery stream with zero coupling between them.
5. AI-Ready Infrastructure: Beyond “Connect SageMaker to S3”
The most common AI infrastructure mistake is treating the data platform and the ML platform as separate concerns meeting at a handoff boundary. A data engineer writes a Glue job producing a training dataset; an ML engineer reads it into SageMaker. This works for a proof of concept. It breaks in production because there is no contractual guarantee that features consumed at inference time are computed identically to features used during training.
That gap, known as training-serving skew (TSS), is responsible for the majority of silent model degradation incidents that organizations attribute to data drift. The actual root cause is architectural: two separate code paths computing what is nominally the same feature.
5.1 Feature Pipelines as Shared Contracts
SageMaker Feature Store solves training-serving skew by making the feature transformation logic the shared contract rather than a dataset snapshot. The online store (backed by DynamoDB, with sub-millisecond reads) and offline store (backed by S3 and Glue Catalog) are populated by the same feature pipeline code, version-controlled and registered as a Feature Group.
When the inference Lambda calls GetRecord on the online store, it receives the identical feature vector the training job would produce for that entity. Feature Groups should carry lineage metadata linking each definition back to its upstream S3 source table, so when a source schema changes, the impact on downstream feature vectors is visible in the lineage graph rather than discovered two weeks later when model performance degrades.
5.2 Vector Infrastructure for Retrieval-Augmented Generation
RAG architectures ground large language model responses in enterprise knowledge, but retrieval quality depends on the vector infrastructure choice. The two primary AWS options serve different optimization targets. Use the decision matrix below to choose:
| Criterion | Amazon OpenSearch k-NN | pgvector on Aurora PostgreSQL |
|---|---|---|
| Data type | Mixed: unstructured text + structured metadata | Primarily relational; retrieval needs SQL JOINs |
| Search style | Hybrid BM25 keyword + HNSW semantic scoring | Approximate vector similarity with SQL filters |
| Scale | Millions of docs; horizontal scale-out supported | Hundreds of thousands; co-located with source DB |
| Write throughput | High: thousands of embedding updates/second | Moderate: matches relational DB capacity |
| Access control | Index-level via IAM + fine-grained access | Row-level via PostgreSQL RLS policies |
| Key trade-off | HNSW index is memory-resident (~60 GB per 10M docs at 1,536 dims) | Throughput ceiling; no horizontal scale for embeddings |
Both options are production-viable. Neither is universally superior; the matrix above encodes the trade-offs rather than a default recommendation. The operational consideration for OpenSearch is index memory: HNSW (Hierarchical Navigable Small World) indexes are memory-resident, so large corpora require careful instance family selection. For pgvector, the constraint is throughput ceiling: Aurora does not match OpenSearch’s horizontal scaling for write-heavy embedding pipelines.
5.3 Closing the MLOps Loop: From Drift Detection to Redeployment
An AI data system unable to respond to model degradation automatically is a liability, not an asset. SageMaker Model Monitor continuously evaluates deployed endpoints against a baseline statistical profile captured at training time. It detects three drift types: data quality drift (input distribution shift), model quality drift (prediction accuracy degradation against ground truth labels), and bias drift (demographic fairness metric changes).
The critical governance step most teams skip is the approval gate between automated retraining and automated deployment. SageMaker Pipelines supports a conditional step routing a newly trained model to a human approval workflow if evaluation metrics fall within a defined variance band, and to automatic deployment if they exceed a higher confidence threshold. This reduces mean time to recovery from drift events without sacrificing the audit trail that regulated industries require.
6. Governance, Security, and Compliance at Scale
The most expensive governance failures in cloud data platforms are not breaches. They are the slow accumulation of inconsistent access controls, unvalidated pipelines, and unrotated keys that make compliance audits a months-long exercise in archaeology. The following controls are non-negotiable for enterprise data platforms on AWS.
6.1 AWS Lake Formation for Unified Access Control
Lake Formation’s column- and row-level security policies centralize permissions across Athena, Redshift Spectrum, and EMR, eliminating the anti-pattern of managing IAM policies per service. Tag-based access control (TBAC) is particularly powerful: tagging a column as PII:true and attaching a Lake Formation policy to that tag automatically restricts access across all query engines, even as new tables are added to the catalog.
6.2 Data Encryption and Key Management
All S3 buckets housing sensitive data should use SSE-KMS with customer-managed keys (CMKs) in AWS Key Management Service (KMS). Separate CMKs per data classification tier (raw, curated, serving) allow granular key rotation policies and enable cryptographic deletion: revoking a CMK renders the associated data unrecoverable, a critical capability for GDPR right-to-erasure compliance.
6.3 Automated Data Quality with AWS Glue Data Quality
AWS Glue Data Quality allows teams to define DQDL (Data Quality Definition Language) rules running inline with Glue ETL jobs. Rules fire alerts to Amazon SNS and can halt pipeline progression when critical thresholds are breached, preventing corrupt data from propagating to downstream models or dashboards.
6.4 Disaster Recovery and Cross-Region Resilience
Enterprise data platforms require documented recovery objectives. S3 Cross-Region Replication (CRR) with rules scoped to specific Iceberg table prefixes provides near-zero RPO for critical datasets. For Redshift, automated snapshots with cross-region copy enabled provide RTO measured in hours.
Lake Formation permissions are not copied automatically with snapshot restores and must be replicated separately using the AWS CLI or CDK. Define recovery tiers explicitly: Tier 1 (inference serving data) warrants active-active replication; Tier 2 (training datasets) warrants daily cross-region backup.
7. Cost Optimization Strategies
AWS data platforms can become significant cost centers if architectural decisions are not revisited as data volumes grow. The following strategies consistently deliver the highest return on investment:
7.1 S3 Storage Tiering
S3 Intelligent-Tiering automatically moves objects between frequent-access and infrequent-access tiers based on observed access patterns, with no retrieval fees. For the raw zone, where most objects are written once and rarely queried again, this can reduce storage costs by 40 to 60 percent compared to S3 Standard. Note that this range assumes genuinely infrequent access: datasets accessed regularly for model retraining will see lower savings. Enable Intelligent-Tiering at the bucket level and monitor the access tier distribution in S3 Storage Lens before projecting savings for your specific workload.
7.2 Redshift Serverless for Workload Variability
Traditional Redshift provisioned clusters are optimized for steady-state workloads. Organizations with highly variable query demand (sprint-based analytics teams, end-of-month reporting peaks) should evaluate Redshift Serverless, which bills per Redshift Processing Unit (RPU) second and scales to zero during inactivity. Workload Management (WLM) queue configuration ensures mission-critical dashboard queries receive priority during contention.
7.3 Athena and S3 Select for Cost-Efficient Querying
Athena charges per terabyte of data scanned. Partitioning Iceberg tables by date and region, and converting JSON to Apache Parquet with Snappy compression, can reduce per-query scan costs by 80 to 95 percent on real-world event datasets. S3 Select pushes predicate filtering into the storage layer for single-object queries, reducing data transfer before Athena even evaluates the query plan.
8. Reference Architecture: End-to-End Blueprint
The following table consolidates a production-grade reference architecture mapping each platform capability to its AWS implementation:
| Capability | AWS Service | Key Configuration |
|---|---|---|
| Streaming ingestion | Kinesis Data Streams + Firehose | Enhanced fan-out consumers; Parquet + Snappy format conversion |
| Batch ETL | AWS Glue 4.0 / EMR Serverless | G.2X workers; Iceberg connector; job bookmarks enabled |
| Data catalog | AWS Glue Data Catalog + Lake Formation | TBAC policies; automated crawlers on S3 event triggers |
| Interactive analytics | Amazon Athena v3 | Iceberg table spec v2 (row-level deletes enabled); query result reuse; workgroup cost controls |
| BI warehouse | Amazon Redshift RA3 / Serverless | Redshift Spectrum for lake federation; AQUA query acceleration |
| Feature store | SageMaker Feature Store | Online (DynamoDB) + offline (S3) modes; feature versioning |
| Vector search | Amazon OpenSearch k-NN or pgvector on Aurora | HNSW + hybrid BM25 scoring (OpenSearch); SQL-native filtering (pgvector) |
| Model orchestration | SageMaker Pipelines + Step Functions | Drift detection triggers; human approval gates before deployment |
| Access governance | Lake Formation + AWS KMS | Column/row-level TBAC; CMK per classification tier |
| Observability | Amazon CloudWatch + AWS X-Ray | Custom metrics dashboards; distributed trace sampling |
| Disaster recovery | S3 CRR + Redshift cross-region snapshots | Tier 1: active-active CRR; Tier 2: daily snapshot copy |
9. Migrating from Legacy Architectures
Most organizations reading this article are not building greenfield. They are evolving existing platforms built on provisioned Redshift clusters, manually partitioned S3 buckets, and bespoke ETL scripts. A full-platform migration is neither necessary nor advisable. The highest-ROI migration sequence is:
- Step 1 — Adopt Apache Iceberg for new tables only. Do not migrate existing tables immediately. Demonstrate query performance and schema evolution benefits on a bounded scope before committing to a full migration.
- Step 2 — Introduce Lake Formation TBAC on net-new data assets. Retrofitting TBAC to existing IAM-managed data is high-risk; build governance discipline on new assets where mistakes have limited blast radius.
- Step 3 — Migrate one high-value ingestion pipeline to the topology-first pattern. Pick a pipeline with a documented latency SLA, apply the three diagnostic questions, instrument with CloudWatch, and capture before/after metrics.
- Step 4 — Extract one feature computation from an ad-hoc Glue script into a versioned SageMaker Feature Group. Validate that online and offline stores produce identical outputs. Use this as the template for subsequent feature migrations.
- Step 5 — Enable Redshift Serverless for variable workloads. Migrate one analytics workgroup at a time, monitoring RPU consumption before decommissioning provisioned nodes.
Each step delivers independent value and can be paused without rolling back previous steps. This incremental approach avoids the big-bang migration pattern that has derailed multi-year data platform programs across regulated industries.
10. Remaining Anti-Patterns
The following architectural mistakes surface consistently and are not tied to a single section above. Each is paired with its correct counterpoint:
- Skipping S3 as the source of truth: Wrong pattern: Storing enriched business metrics only in Redshift or DynamoDB without writing back to S3. Correct approach: All compute outputs must write back to S3 Iceberg tables. Compute engines fail; the lake is the authoritative record.
- Training-serving skew (TSS): Wrong pattern: Defining feature transformations differently in the training pipeline versus the inference Lambda. Correct approach: Share a single versioned transformation library between both paths, registered in SageMaker Feature Store.
- Wrong storage primitive for vectors: Wrong pattern: Storing embedding vectors in a relational table as JSON arrays. Correct approach: Use OpenSearch k-NN or pgvector. JSON array storage prevents vector index construction and degrades similarity search to O(n) full-table scans, where n is the number of documents in the corpus.
Glossary of Key Terms
CDC (Change Data Capture): A technique for tracking row-level changes in a source database and propagating them downstream in near real time, without requiring full-table exports.
DQDL (Data Quality Definition Language): A domain-specific language used by AWS Glue Data Quality to define data validation rules.
HNSW (Hierarchical Navigable Small World): A graph-based algorithm for approximate nearest-neighbour search in vector databases. Used by Amazon OpenSearch k-NN for high-performance semantic similarity retrieval.
RAG (Retrieval-Augmented Generation): An architecture pattern that grounds large language model responses in enterprise knowledge by retrieving relevant documents from a vector index before generating a response.
RPU (Redshift Processing Unit): The compute unit used by Amazon Redshift Serverless. Billing is per RPU-second, enabling pay-per-use pricing for variable workloads.
TBAC (Tag-Based Access Control): A Lake Formation access control model where permissions are attached to metadata tags on columns or tables, rather than to specific resources. Enables scalable, policy-as-code governance.
TSS (Training-Serving Skew): The divergence between feature computation logic at training time versus inference time. The primary cause of silent model degradation in production ML systems.
11. The Compounding Return on Architecture Investment
The organizations leading in AI-driven business are not necessarily those with the largest model budgets. They are the ones whose data platforms make each new AI initiative incrementally cheaper and faster to deploy than the last. That compounding effect is the real return on architectural investment.
A well-governed Iceberg table schema becomes a reusable input to five different models. A feature group defined for fraud detection also serves the customer churn model. A Lake Formation TBAC policy written once enforces access control across every new query engine added to the platform.
The patterns described in this article are production-validated architectures running at scale in regulated industries today. The layered lake-house with Iceberg provides the storage contract making engine swaps risk-free. The topology-first ingestion framework locks in latency and cost characteristics at design time. Feature Store contracts eliminate training-serving skew. Lake Formation governance means compliance controls propagate automatically to every downstream derivative.
The hardest part of this journey is not the technology. AWS provides all the necessary primitives. The hardest part is the organizational discipline to resist short-term convenience: bespoke pipelines, undocumented schemas, and siloed access controls. Every exception to the architectural standards described here is a future re-engineering project deferred, not avoided. Teams that internalize this discipline early will find that building a new AI capability becomes a configuration decision rather than a re-architecture project, and that velocity advantage compounds quarter over quarter.
These patterns reflect practical lessons learned while designing enterprise-scale data platforms supporting advanced analytics and AI-driven decision systems. Gayatri Tavva is a Distinguished Lead Data Engineering Architect specializing in large-scale cloud data platforms, AI-ready data infrastructure, and enterprise analytics systems.