
Distributed systems in finance carry an unusually heavy burden. Most distributed-systems writing is permissive about eventual consistency, retry strategies, and the trade-offs that come with horizontal scale. In financial systems the same trade-offs are constrained by the unforgiving requirement that money cannot be created or destroyed by an architectural mistake. Designing a distributed financial system means navigating that constraint without sacrificing the operational benefits of horizontal scale.
This piece sets out the design patterns that work in distributed financial systems, the specific places where the standard distributed-systems toolkit needs careful adaptation, and the failure modes that distinguish strong U.S. financial engineering teams from those still learning these lessons in production.
The CAP theorem still applies, but the choice is constrained
Brewer’s CAP theorem states that a distributed system cannot simultaneously guarantee consistency, availability, and partition tolerance. In financial systems the choice between consistency and availability is constrained: the ledger of record almost always has to choose consistency. The downstream systems that depend on the ledger can choose availability and tolerate eventual consistency, but the ledger itself cannot.
This is the single most important design constraint that distinguishes financial distributed systems from generic ones. The teams that respect this constraint design their architecture around a strongly consistent core with eventually consistent peripheries. The teams that try to weaken consistency at the core to gain availability usually rediscover, painfully, why the constraint exists. The cost of that rediscovery is paid in customer-visible incidents that take weeks to resolve cleanly.
Saga patterns and the long-running transaction problem
Many financial workflows span multiple services and cannot be wrapped in a single database transaction. A funds transfer that touches an originating account, a destination account, and a fee account belongs to this category. The saga pattern, in which the workflow is decomposed into a sequence of local transactions with compensating transactions for rollback, is the standard answer.
The pattern works in finance, with caveats. Compensating transactions in financial systems must themselves be auditable and idempotent. The saga state must be persisted in a way that allows recovery from any failure point. The user-facing behaviour during a long-running saga must be designed carefully so the customer is not exposed to inconsistent intermediate states. The teams who design sagas with these caveats handle multi-service workflows reliably. The teams who treat sagas as a generic pattern without the financial-specific discipline produce workflows that work in the happy path and fail unexpectedly in the edge cases.
Event sourcing and the audit trail benefit
Event sourcing, in which state is reconstructed from an immutable log of events rather than maintained as a mutable record, has a particular fit with financial systems. The immutable event log is essentially a built-in audit trail, which aligns with supervisory expectations about evidence preservation. The ability to reconstruct any state at any historical point makes investigations, disputes, and regulatory inquiries dramatically easier.
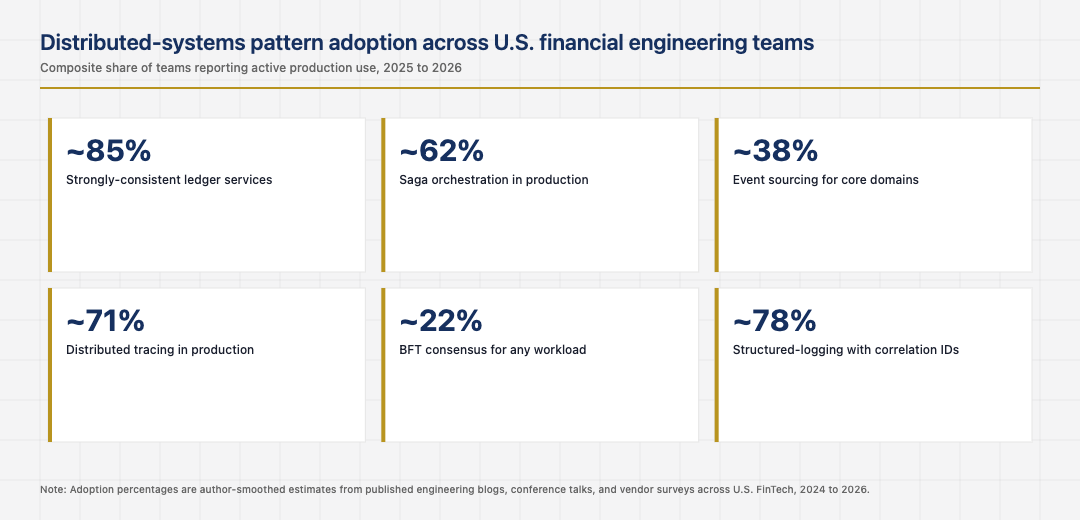
Event sourcing has implementation costs. Event schema versioning becomes a first-class concern, since old events must remain interpretable indefinitely. Event store performance becomes a critical operational concern. The mental model shift from mutable state to event-driven state is significant for teams new to the pattern. The U.S. financial operators who invested in event sourcing early have benefited from cleaner audit trails and faster investigations. The ones who tried to retrofit it onto existing systems have struggled, and the retrofit cost is high enough that most operators end up living with their original architecture rather than completing the transition.
Distributed consensus and the Byzantine question
Most U.S. financial distributed systems do not need Byzantine fault-tolerant consensus. The participants in the system are trusted, the network is internally controlled, and crash-fault tolerance through patterns like Raft or Paxos is sufficient. The Byzantine question becomes relevant primarily for blockchain-adjacent systems, cross-institutional settlement, and systems where the participants do not trust each other.
The mistake some teams make is over-engineering for Byzantine resilience when crash-fault tolerance would suffice. The cost of the over-engineering is operational complexity that the team did not need to take on. The opposite mistake, under-engineering for crash-fault tolerance when the system actually needs it, shows up as data inconsistency under partial failure. The teams who match the consensus pattern to the actual trust model of the system end up with cleaner architectures.
Operational discipline as the multiplier
The fifth pattern is the meta-pattern. The architectural choices in distributed financial systems matter much less than the operational discipline that backs them. Distributed tracing across service boundaries, structured logging with consistent correlation IDs, monitoring that surfaces partial failures rather than only complete outages, and runbooks that have been exercised under realistic failure scenarios all multiply the value of the underlying architecture.
The U.S. financial engineering teams who invested in operational discipline alongside their architectural choices ship distributed systems that hold up over years. The teams who treated operational discipline as something to add later usually find that the systems work in normal operation and fall over in failure modes that nobody tested. The architecture and the operations are not separate disciplines. They compound each other, and the compounding is what separates the strongest U.S. financial distributed systems from the weakest ones.
Read across the full picture, distributed systems in U.S. finance work when the architects respect the consistency constraint at the ledger boundary, design sagas with financial-specific discipline, choose event sourcing where the audit-trail benefit pays back its cost, match consensus patterns to actual trust models, and invest in operational discipline as a multiplier. The patterns are not exotic. The discipline of applying them consistently across years is what separates durable systems from rewrites.
Looking back across the full sweep makes one final point clear. The American financial system has accumulated its strength through the patient layering of standards, institutions, and supervisory expectations on top of an active commercial layer. The application layer captures attention because it is visible and fast-moving. The institutional layer captures durability because it is invisible and slow-moving. Operators who learn to read both layers at once tend to outlast operators who only read the visible one, and the discipline of doing so is not glamorous but it is the discipline that consistently shows up in the firms that compound through multiple cycles instead of just the one they happened to start in.
The same lesson shows up in the founders who quietly build through down cycles that catch the louder ones flat-footed. Reading the institutional rebuild as carefully as the product roadmap is what separates the long-lived operators in 2026 from the ones whose names appear only in retrospectives. The competitive position of the next decade will turn less on the surface features that draw press attention and more on the structural features that draw supervisory attention. The two are increasingly the same set of features, and the operators who recognise that early are the ones who position correctly while the rest are still arguing about whether the rules apply to them.
One last consideration is worth carrying forward. Cross-cycle perspective sharpens any single decision. Looking at how peer ecosystems have handled the same question, what they got right and where they stumbled, almost always reveals something about the decisions that the U.S. system is in the middle of making right now. The operators who travel intellectually as well as commercially tend to make better forecasts about which infrastructure layer will matter most in the next phase, and which segment is being quietly reset under the noise of the daily news. The disciplined version of that practice is what the next ten years of American FinTech will reward most consistently.






































