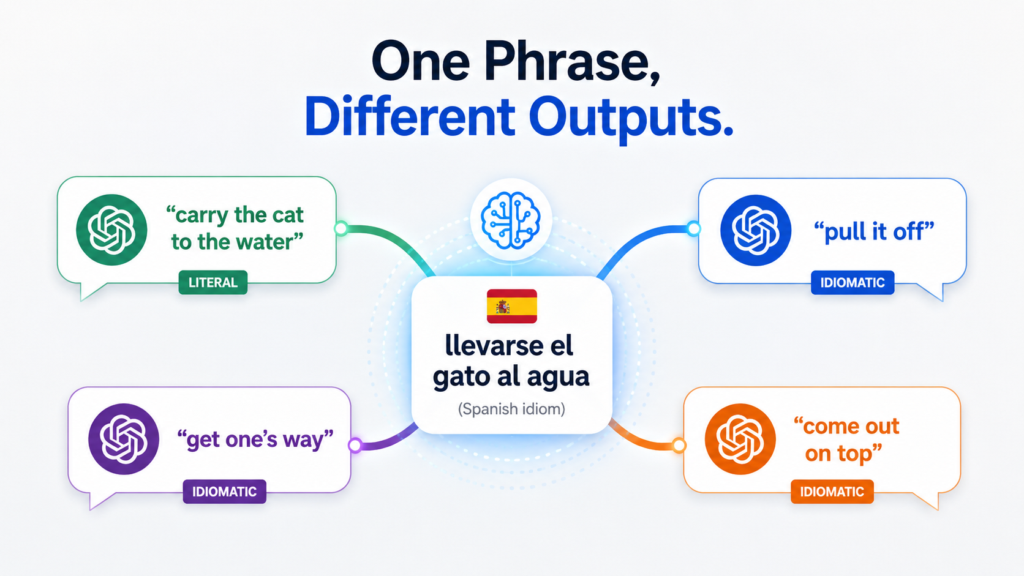
The Spanish idiom llevarse el gato al agua, literally “to carry the cat to the water,” has no equivalent meaning in English. It means to pull off something difficult, to succeed against the odds. To a native speaker, it is immediately understood. To an AI model trained primarily on literal text, it is a puzzle with at least four different solutions.
Run it through GPT-4.1-mini and you get: “to carry the cat to the water.” Run it through GPT-4.1-nano and you get the same. Switch to GPT-4.1-MINI and the output shifts to “to pull it off successfully.” Try GPT-5.4-mini and the model produces “to get one’s way.” GPT-5.4 renders it as “to come out on top.”
Five outputs. Three distinct semantic interpretations. One source phrase.
This kind of divergence is not a glitch. It is a structural property of how large language models handle translation, and understanding why it happens has practical implications for anyone deploying AI translation in a professional context.
Why Models Diverge on the Same Input
Large language models are trained on different corpora, with different architecture decisions, different fine-tuning approaches, and different optimization targets. When the input is unambiguous (a technical term, a product name, a date) these differences rarely surface. But as soon as the source text involves pragmatic meaning, cultural reference, idiomatic structure, or tone-dependent register, the training differences between models produce meaningfully different outputs.
This is not a problem that better prompt engineering resolves. It is a consequence of the probabilistic nature of language models. The same token sequence can be legally decoded in multiple ways, and the model’s learned distribution determines which rendering it favors. A model trained with more Spanish-language data from Latin American editorial contexts will weight idiomatic meaning differently than one trained on European corpus data. A model fine-tuned for fluency will make different trade-offs than one fine-tuned for adequacy.
The divergence documented above, where two GPT variants produce an identical literal rendering while three others produce different idiomatic interpretations, reflects exactly this phenomenon. It is also why, as TechBullion’s coverage of how neural machine translation models are built illustrates, model architecture choices shape translation behavior in ways that cannot be evaluated from a single output.
An industry-wide study by Slator confirmed that quality and accuracy concerns remained the top worries for organizations adopting AI translation workflows in 2025, with accuracy cited by 72% of respondents and quality concerns flagged by 68%, even as adoption accelerated. The problem is not that AI translation is bad. The problem is that it is inconsistently good, and that inconsistency is invisible when you only run one model.
The Idiomatic Translation Problem as a Test Case
Idioms are a particularly revealing test case because they cannot be resolved through pattern-matching alone. The correct translation of “llevarse el gato al agua” is not recoverable from the constituent words. It requires the model to identify the expression as idiomatic, retrieve the culturally appropriate equivalent, and make a judgment about whether the target language requires a paraphrase, an equivalent idiom, or a descriptive rendering.
Research has documented this challenge extensively. Idiomatic expressions have been consistently mistranslated literally by commercial machine translation systems across documented test cases. One study, Crossing the Threshold: Idiomatic Machine Translation through Retrieval Augmentation, found that retrieval-augmented approaches improved idiomatic translation accuracy by up to 13 percentage points over standard pre-trained models, but only when the idiom was explicitly flagged during training.
The complication is that most real-world translation tasks do not arrive with idioms pre-labelled. The model must detect idiomaticity on its own, and different models have different sensitivities to this. The models that produce idiomatic interpretations are drawing on different learned associations than the models that default to literalism.
This is consistent with what the known limitations of single-system translation tools have long documented: accuracy breakdowns tend to cluster at precisely the points where cultural and contextual reasoning is required, not at straightforward syntactic rendering.
What Divergence Scores Actually Reveal
When multiple models diverge on the same input, that divergence is itself informative. It signals that the translation task is non-trivial, meaning there is genuine ambiguity in how the source text should be rendered. A phrase that produces identical outputs across five models is a phrase where the translation is likely straightforward. A phrase that produces five different outputs is a phrase where any single model’s confidence should be questioned.
This reframing has research support. In multi-agent AI evaluation studies, inter-model disagreement has been used as a proxy for task difficulty, with high disagreement rates flagging items that require additional review or alternative methods. In translation quality estimation research, model uncertainty is a well-established signal for downstream human review prioritization.
The practical implication is direct: divergence is not just a quality problem: it is a quality signal. A system that shows you where models disagree gives you more information than a system that shows you only one model’s output with high apparent confidence.
The Research Case for Multi-Model Architecture
The idea that ensemble methods outperform individual models is not new in machine learning. In classification tasks, random forests and boosted ensembles consistently outperform single decision trees by aggregating diverse weak learners. In translation, the equivalent approach has been explored in MBR (Minimum Bayes Risk) decoding, where multiple candidate translations are generated and the one with the highest expected utility relative to the set is selected.
What the divergence above illustrates is that this problem exists at the commercial model level, not just within a single model’s output distribution. GPT-4.1-mini and GPT-5.4 are not sampling variation from the same model; they are architecturally distinct systems with different training runs, and they disagree. The argument for running multiple architectures simultaneously, rather than sampling multiple outputs from one, is that it captures a wider range of translation hypotheses and is more likely to include the correct rendering in the candidate set.
A 2025 research survey on AI in language translation: accuracy and limitations noted that accuracy breakdowns in AI translation tend to cluster around exactly the scenarios (idioms, domain-specific register, morphologically complex languages) where single-model performance degrades unpredictably and where multi-system approaches show the clearest quality improvements.
Tomedes has tested this at scale through MachineTranslation.com, a AI translator built around the premise that AI models disagree too often to trust any single one. In internal error benchmarks, individual top-tier LLMs produced critical translation errors at rates ranging from 10% to 18% across mixed professional content. When the same content was processed through an architecture that runs 22 models simultaneously and selects the output the majority agree on, the critical error rate dropped to under 2%. The reduction is not achieved by selecting a better single model. It is achieved by treating inter-model agreement as a reliability signal.
How Majority Agreement Changes the Selection Problem
That premise is exactly what drives the design of the SMART mechanism on MachineTranslation.com. Rather than routing a source text through one model and delivering whatever comes out, SMART runs it through 22 AI models simultaneously, including ChatGPT, Claude, Gemini, DeepL, DeepSeek, Grok, Llama, Mistral, and 14 others, then selects the translation that the majority of them agree on.
The logic is direct. When most models converge on the same rendering, that convergence is a reliability signal. When they diverge, the platform surfaces that divergence rather than hiding it. In the case of “llevarse el gato al agua,” a majority vote across 22 models would likely surface the idiomatic interpretations over the literal rendering, because more sophisticated models trained on broader idiomatic data tend to agree on pragmatic meaning.
What this also means is that the outliers, the models that defaulted to literal rendering, are not discarded silently. Their disagreement is visible, which is precisely the information a professional translator or editor needs to flag a phrase for review.
At the platform level, this architecture produces a 90% reduction in critical translation errors compared to single-model workflows, according to Tomedes internal benchmarks. For organizations that need translation outputs they can act on without manual verification of every sentence, that reduction represents a meaningful shift in the risk profile of AI-assisted localization.
Conclusion
The screenshot of four different translations of one Spanish idiom is not an argument against AI translation. It is an argument for understanding what AI translation actually does, and for building workflows that account for the structural variability between models rather than ignoring it.
When models disagree, they are telling you something. The research question, and the applied design question, is whether your translation infrastructure is built to hear it.


























