Sales teams face a persistent challenge in the modern business environment: how to allocate limited time and resources towards leads most likely to convert into customers. This challenge has grown more acute as inbound marketing and content strategies have expanded pipeline volume significantly. The predictive lead scoring market was valued at $1.9 billion in 2025, reflecting the critical importance organisations place on this capability. Predictive lead scoring delivers approximately 4 times better conversion rates than traditional rule-based approaches, fundamentally changing how sales teams prioritise their efforts.
Traditional rule-based lead scoring relies on fixed criteria established by marketing and sales leadership. A prospect might receive points for downloading a whitepaper, attending a webinar, or opening marketing emails. Once a lead accumulates a certain threshold of points, it is automatically escalated to the sales team. This approach, whilst systematic, suffers from significant limitations. It cannot account for the complex interactions between different behaviours, cannot adapt to changing market conditions, and often relies on assumptions that may not reflect actual conversion patterns.
How Predictive Lead Scoring Differs from Rule-Based Approaches
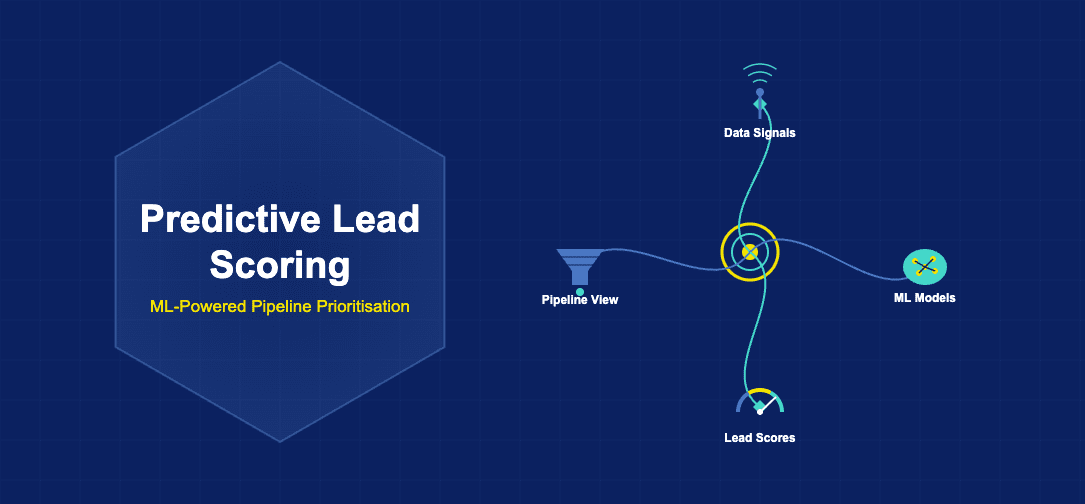
Predictive lead scoring represents a fundamentally different paradigm. Rather than relying on human-defined rules, predictive models learn directly from historical data about which leads converted and which did not. Machine learning algorithms identify patterns in the characteristics and behaviours of converted customers, then score new leads based on their similarity to those historical winners. This data-driven approach eliminates reliance on intuition and allows organisations to uncover non-obvious patterns that human analysts might miss.
The practical implications of this difference are substantial. A rule-based system might assign a flat point value to a website visit, regardless of what page was visited, how long the visitor spent, or what they did after leaving. A predictive model, by contrast, can recognise that certain page visits in combination with specific email engagement patterns are far more predictive of eventual conversion than others. This granular understanding of lead quality enables dramatically more precise sales prioritisation.
Rule-based systems also suffer from a recency bias embedded in their design. An established scoring rule remains in effect until someone manually updates it, meaning the system continues using outdated assumptions even after market conditions change. Predictive models, particularly those using continuous learning approaches, naturally adapt as new conversion data becomes available. A model trained last month understands conversion patterns better than a model trained a year ago, enabling real-time optimisation.
Machine Learning Models Used in Predictive Lead Scoring
Several distinct machine learning model architectures serve the predictive lead scoring use case, each with particular strengths. Logistic regression models provide a strong baseline for lead scoring, establishing a probabilistic framework where a model outputs the likelihood that a lead will convert. Logistic regression is particularly valuable for organisations new to predictive scoring because it is relatively transparent, allowing stakeholders to understand which factors most heavily influence scoring decisions.
Gradient boosting algorithms, including implementations like XGBoost, represent the current state of the art for many organisations. These models work by training a series of decision trees sequentially, with each new tree correcting errors made by previous trees. The result is a highly accurate, ensemble model that captures complex non-linear relationships between features. Gradient boosting typically outperforms simpler approaches, achieving conversion rate improvements of 30 to 50 percent over rule-based systems.
Neural networks and deep learning approaches are increasingly employed for organisations with large volumes of training data. These models excel at discovering patterns in high-dimensional datasets and can incorporate multiple data types including text, time series, and categorical information. However, neural networks require substantial training data and computational resources, making them more suitable for larger enterprises than smaller organisations.
Random forest models provide a middle ground, offering strong predictive performance with greater interpretability than neural networks. They naturally handle both numerical and categorical data, require less tuning than gradient boosting, and tend to be more robust to unusual data patterns. For many mid-market organisations, random forest models represent an optimal balance between predictive power and practical implementation considerations.
Data Inputs for Predictive Scoring Models
The quality and breadth of input data directly determines the quality of predictive lead scoring models. Behavioural data captures how prospects interact with a company, including website visits, content downloads, email opens and clicks, webinar attendance, and social media engagement. This data reveals prospect intent and level of interest in the organisation and its offerings. High-quality behavioural data, collected through website analytics and marketing automation platforms, forms the foundation of effective predictive models.
Firmographic data describes the characteristics of a prospect’s company, including industry, company size, revenue, location, and growth trajectory. This data, often sourced from third-party data providers or company databases, helps identify whether a prospect works in a target market segment. A software company might find that prospects from companies with 50 to 500 employees convert at substantially higher rates than very small or very large enterprises, making employee count an important predictive feature.
Technographic data reveals what technology a prospect’s company uses, including software platforms, infrastructure choices, and technology vendors. This data proves particularly valuable for enterprise software companies, where technographic fit often predicts buying readiness. A prospect working at a company that uses Salesforce, for instance, might be more likely to purchase Salesforce-compatible solutions than companies using alternative CRM systems.
Intent data has emerged as one of the highest-value input categories. Intent data, sourced from third-party providers like 6sense, captures indicators that a prospect is actively researching solutions, including search queries, website visits to relevant sites, and content consumption patterns. Organisations that integrate intent data into predictive models often see dramatic improvements in model accuracy, as intent data directly reflects a prospect’s current buying readiness.
Leading Predictive Lead Scoring Platforms
The platform landscape for predictive lead scoring has matured considerably, with several vendors dominating the market space. 6sense focuses specifically on account-based marketing and provides sophisticated predictive models powered by intent data and extensive third-party integrations. The platform excels at identifying accounts in market and the right time to engage them, making it particularly valuable for B2B organisations pursuing account-based marketing strategies.
Lattice Engines, now part of Salesforce, provided foundational predictive scoring technology and continues to be integrated throughout the Salesforce ecosystem. This integration advantage makes Salesforce Predictive Lead Scoring particularly attractive for organisations already invested in the Salesforce platform, as data flows seamlessly between systems.
MadKudu specialises in predictive lead scoring for SaaS companies, bringing particular expertise in the specific patterns and signals most predictive of SaaS customer conversion. The platform integrates directly with marketing automation and CRM systems popular in the SaaS ecosystem, reducing implementation friction. Infer similarly focuses on enterprise sales organisations, bringing detailed behavioural analysis and sophisticated data science approaches to lead prioritisation.
Model Training, Validation, and Governance
Building an effective predictive lead scoring model requires thoughtful attention to training methodology and validation practices. Organisations must divide historical data into training and testing sets, using the training set to develop the model and reserving the testing set to evaluate whether the trained model performs well on unseen data. This validation process prevents overfitting, where models learn peculiarities of the training data rather than broader patterns applicable to new leads.
Proper train-test splitting is particularly important for lead scoring, because an overfit model might perform excellently during validation but fail catastrophically when scoring real leads. Cross validation, where data is split multiple times and model performance is averaged across all splits, provides additional assurance that model performance is robust and reliable.
Model governance becomes increasingly important as predictive lead scoring becomes integral to sales operations. Organisations should establish clear protocols for monitoring model performance over time, setting thresholds for when model retraining is required, and defining processes for identifying and addressing model degradation. A model trained on conversion data from 2024 may not reflect 2025 buying patterns as accurately, necessitating periodic retraining with fresh data.
Documentation of the training data, model architecture, key features, and performance metrics is critical for organisational knowledge retention and regulatory compliance. Detailed documentation enables new team members to understand the model, allows for appropriate interpretation of model predictions, and supports audit requirements in regulated industries.
Lead Scoring Decay and Engagement Recency
A sophisticated consideration in predictive lead scoring is the appropriate treatment of temporal dynamics. Lead scores should decay over time if engagement does not continue, reflecting the reality that a prospect who engaged heavily six months ago but has shown no recent activity is less likely to be ready to buy than a prospect with recent engagement. Recency weighting within predictive models captures this temporal dimension.
Different model architectures handle temporal dynamics differently. Some predictive platforms use explicit time-decay functions that gradually reduce historical engagement signals’ importance. Others incorporate time-aware features that encode how recently key events occurred, allowing the model itself to learn appropriate temporal weighting. The optimal approach depends on sales cycle length, market dynamics, and other contextual factors specific to each organisation.
Seasonal considerations also matter in many industries. B2B software companies often see higher buying propensity in the fourth calendar quarter as organisations allocate remaining budget. Hospitality and travel companies see seasonal patterns that should inform lead scoring. Effective predictive models incorporate seasonal factors, either through explicit seasonal features or by training models separately on data from equivalent seasons in different years.
Integration with CRM and Marketing Automation
Predictive lead scoring technology delivers value only when integrated seamlessly into sales and marketing workflows. Modern predictive scoring platforms provide native integrations with leading CRM systems including Salesforce, HubSpot, and Microsoft Dynamics, allowing lead scores to flow directly into sales tools without manual work. This integration ensures that sales representatives see lead scores automatically within their CRM interface, supporting lead prioritisation without requiring them to access a separate system.
Integration with marketing automation platforms enables sophisticated nurture strategies based on predicted likelihood to convert. A lead predicted to be highly likely to convert might receive accelerated nurture content designed to move them toward a buying decision. A lead predicted to be in early-stage exploration might receive more educational content that builds awareness and establishes thought leadership. This precision targeting in nurture campaigns improves conversion efficiency significantly.
Two-way integrations create continuous feedback loops. As sales representatives update CRM records with notes about why leads were won or lost, this feedback data can be fed back into the predictive model to improve future predictions. Organisations that establish these feedback loops see continuous model improvement over time, with each quarter bringing higher model accuracy and better conversion performance.
Measuring Predictive Scoring Model Performance
Evaluating whether a predictive lead scoring model is delivering value requires establishing clear performance metrics. The receiver operating characteristic (ROC) curve illustrates the tradeoff between sensitivity and specificity, showing how many true positives a model identifies at various score thresholds. A model that perfectly separates leads that convert from those that do not produces an ROC curve that reaches the top-left corner of the graph. Most real-world models fall somewhere between random chance and perfection.
Area under the ROC curve (AUC) summarises overall model discrimination ability with a single metric ranging from 0.5 (random guessing) to 1.0 (perfect classification). In practice, an AUC of 0.75 or higher indicates a model with strong discriminative ability, whilst an AUC below 0.65 suggests the model may not be outperforming simpler baselines.
Beyond statistical metrics, organisations should measure business outcomes. Organisations adopting predictive lead scoring should see improvements in sales productivity, measured by revenue per sales representative. They should also see higher win rates on leads predicted to be high scoring, and lower wasted effort on leads predicted to be low scoring. These business metrics ultimately matter more than statistical model performance.
| Dimension | Rule-Based Scoring | Predictive Scoring |
|---|---|---|
| Conversion Rate Improvement | Baseline | 4x Higher |
| Model Adaptability | Manual Updates Required | Continuous Learning |
| Pattern Detection | Explicit Rules Only | Complex Interactions |
| Data Utilisation | Limited Features | Comprehensive Features |
| Time Decay Handling | Difficult to Implement | Built In |
| Lead Quality Insights | Limited | Detailed Probability Scores |
| Data Category | Examples | Predictive Value |
|---|---|---|
| Behavioural Data | Website visits, email engagement, content downloads, webinar attendance | Very High |
| Intent Signals | Search queries, competitor research, third-party tracking | Extremely High |
| Firmographic Data | Company size, industry, revenue, location | High |
| Technographic Data | Technology platforms used, infrastructure choices | High |
| Demographic Data | Job title, seniority, department, location | Medium |
| Social Data | LinkedIn profile, social engagement, network activity | Medium |
Implementation Best Practices
Organisations planning to implement predictive lead scoring should prioritise data quality above all else. Machine learning models are only as good as the data they learn from. Inconsistent data entry, missing values, and duplicate records in source systems will propagate through predictive models, reducing their reliability. Before implementing predictive scoring, conduct a comprehensive data audit and establish data governance practices that ensure ongoing data quality.
Start with a pilot implementation focused on a single sales segment or product line rather than attempting to deploy predictive scoring across an entire organisation simultaneously. This focused approach allows teams to validate model performance, establish operational processes, and build organisational confidence before scaling. Lessons learned in pilot phases prevent mistakes and rework at the enterprise scale.
Invest in change management and training for sales teams. Sales representatives accustomed to traditional lead assignment processes may initially resist relying on algorithmic prioritisation. Demonstrating improved productivity and higher win rates on high-scoring leads builds confidence and encourages adoption. Providing sales representatives with access to model transparency information, showing which factors most heavily influenced a particular lead score, helps them understand and trust model decisions.
Conclusion
Predictive lead scoring technology represents a quantum leap in sales productivity and effectiveness. The 4x improvement in conversion rates compared to rule-based approaches, combined with continuous model adaptation and sophisticated pattern detection, makes predictive scoring an essential capability for sales-driven organisations. As machine learning maturity increases and implementation becomes simpler, adoption of predictive lead scoring will accelerate across all industries. Organisations that embrace this technology today position themselves to dramatically improve sales efficiency, accelerate revenue growth, and make substantially better use of limited sales resources.
Related reading: Marketing Automation: How Platforms Are Reshaping Campaign Management
Research from McKinsey’s 2024 analysis indicates that organisations deploying AI at scale report efficiency improvements of 15 to 25 percent within the first 18 months of production implementation.
According to Mordor Intelligence, the AI in fintech market is projected to grow at a compound annual growth rate exceeding 20 percent through 2029, driven by demand for automated fraud detection, credit scoring, and customer service applications.
For more coverage on related topics, explore our dedicated section on artificial intelligence.