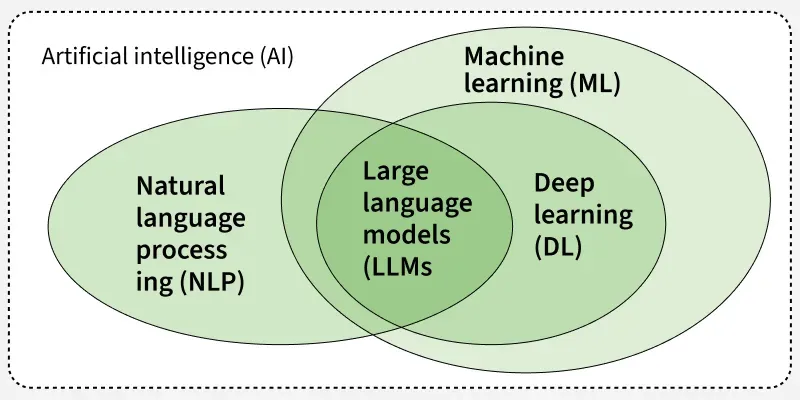
Language-driven data products are among the most complex systems being built in the technology industry today. According to Fortune Business Insights, the global NLP market was valued at USD 36.8 billion in 2025 and is projected to reach USD 193.4 billion by 2034, reflecting the scale of investment organizations are making in language-driven AI systems and the growing pressure on teams to build them reliably. They combine the ability to understand, process, and generate human language with the infrastructure required to move, store, and transform data at scale. The result, when built well, is a product that can extract meaning from unstructured text, respond to natural language queries, surface relevant information from large document collections, or power intelligent automation across business workflows.
Building these products requires two distinct specializations working in close coordination. NLP developers bring the language intelligence. Data engineers build and maintain the infrastructure that makes that intelligence operational at scale. Neither role is sufficient without the other, and the teams that understand this from the start consistently produce better outcomes than those that discover it midway through delivery.
What a Language-Driven Data Product Actually Is
Where NLP and Data Engineering Meet
A language-driven data product is any system where the primary value comes from the ability to process, understand, or generate human language at scale, using structured data pipelines to feed that capability. Examples include enterprise search systems that retrieve relevant documents in response to natural-language queries, customer support platforms that automatically classify and route incoming messages, sentiment analysis tools that process large volumes of customer feedback in real time, and document intelligence systems that extract structured information from contracts, invoices, or regulatory filings.
What distinguishes these products from simpler AI applications is the volume and variety of the data they depend on. A language model that works well in a research environment often breaks down when exposed to the messy, inconsistent, high-volume text data produced by real business operations. The data engineering layer mediates between raw data and the NLP system, ensuring that inputs are clean, consistent, and delivered at the right cadence for the model to perform reliably.
Why These Products Are Harder to Build Than They Look
The difficulty is not primarily in the NLP models themselves. Pre-trained language models, fine-tuning frameworks, and evaluation tooling have all matured considerably over the past several years. The challenge is integrating those models into production systems that handle real data, real traffic, and real edge cases reliably.
Text data in production environments is rarely clean. It arrives in multiple formats, contains encoding errors, uses domain-specific terminology that general models struggle with and often requires significant preprocessing before it is fit for model input. The pipeline that handles this preprocessing, routes data to the right model, manages model versioning and delivers outputs to downstream systems is a data engineering problem, not an NLP problem. Teams that treat it as an afterthought consistently find themselves rebuilding it from scratch after the first production failure.
The Role of NLP Developers in an AI Team
What NLP Developers Actually Do
NLP developers design, build, and maintain the systems that allow machines to process and understand human language. In a production AI team, this means working across the full lifecycle of a language model, from selecting the right pre-trained model for a given task to fine-tuning it on domain-specific data, evaluating its performance against defined benchmarks, and deploying it into a system where it receives real inputs and produces outputs that other parts of the product depend on.
In practice, NLP developers spend a significant portion of their time on tasks that sit between research and engineering. They experiment with different model architectures and fine-tuning approaches, analyze failure cases where the model produces incorrect or unexpected outputs, and iterate on data preprocessing logic that affects model performance. They also work closely with data engineers to define the format and quality requirements for incoming data, and with product teams to translate business requirements into measurable model objectives.
The Skills That Define a Strong NLP Engineer in 2026
The NLP engineering role has become considerably more specific as the field has matured. Strong NLP engineers in 2026 are expected to bring a combination of the following capabilities:
- Large language model expertise: Familiarity with transformer architectures, pre-trained models such as BERT, GPT, and LLaMA, and fine-tuning techniques including LoRA and RLHF
- NLP libraries and frameworks: Hands-on experience with Hugging Face Transformers, SpaCy, NLTK, and LangChain for building and deploying language pipelines
- Evaluation and benchmarking: Ability to design evaluation frameworks, interpret metrics such as BLEU, ROUGE, and F1, and distinguish between benchmark performance and real-world performance
- Python proficiency: Strong Python skills across data manipulation, model training and API development
- MLOps awareness: Understanding of how models are versioned, monitored, and updated in production environments, including familiarity with tools such as MLflow and Weights and Biases
- Domain adaptation: Experience adapting general-purpose models to specific domains such as legal, medical, or financial text, where out-of-the-box performance is rarely sufficient
When organizations decide to hire NLP developers with production experience, they are looking for engineers who have moved beyond academic or research contexts and can operate effectively within the constraints of a real product team, including deadlines, existing infrastructure, and non-technical stakeholders.
The Role of Data Engineers in an AI Team
Data engineers design and maintain the infrastructure that moves, transforms and stores data across an organisation’s systems. In an AI team building a language-driven product, this means constructing the pipelines that collect raw text data from source systems, clean and transform it into a format that NLP models can consume, and deliver outputs to the downstream applications and databases that the product depends on.
The scope of this work is broader than it appears from the outside. A data engineer on an NLP product team might be responsible for:
- Ingestion pipelines: Building connectors that pull data from APIs, databases, document stores, messaging platforms, and third-party services into a centralized processing environment
- Data transformation: Writing transformation logic that standardizes text encoding, removes noise, handles missing values, and structures incoming data according to the schema the NLP layer expects
- Storage architecture: Designing the storage layer, including data lakes, data warehouses, and vector databases, that hold both raw and processed data at different stages of the pipeline
- Orchestration: Managing pipeline scheduling, dependency resolution, and failure handling using tools such as Apache Airflow, Prefect, or Dagster
- Monitoring and observability: Tracking pipeline health, data quality metrics, and throughput to ensure that the NLP system always receives inputs that meet its operating requirements
Why Data Engineering Is the Foundation NLP Depends On
An NLP model is only as reliable as the data it receives. A model that performs well on clean, well-structured text will produce inconsistent or incorrect outputs when the pipeline feeding it delivers duplicated records, malformed strings, or data from a source that changed its schema without notice. These are not model failures. They are infrastructure failures, and they are the data engineer’s domain to prevent and resolve.
For organizations looking to engage a data engineer for hire with AI pipeline experience, the most important signal is not familiarity with a specific tool but the ability to design systems that are observable, recoverable, and adaptable as the data environment changes. The best data engineers build pipelines that fail gracefully, alert clearly, and can be modified without rebuilding from scratch every time a new data source is added or an existing one changes format.
How NLP Developers and Data Engineers Work Together
Where the Two Roles Intersect in Practice
NLP developers and data engineers share a boundary that, when managed well, produces the most reliable language-driven systems. That boundary sits at the point where raw data becomes model input. Everything upstream of that point, collection, storage, transformation and delivery, is primarily the data engineer’s responsibility. Everything downstream, model selection, fine-tuning, evaluation, and inference, is primarily the NLP developer’s responsibility. In practice, both roles need to understand enough of the other’s domain to communicate effectively and make decisions that do not create problems on the other side of the boundary.
The clearest example of this intersection is data schema design. An NLP developer who understands which preprocessing steps their model requires can give the data engineer precise specifications for the format, encoding, and structure of the incoming data. A data engineer who understands how NLP models consume input can anticipate downstream requirements when designing transformation logic. When this communication works well, the pipeline produces consistent, high-quality inputs and the model performs predictably. When it breaks down, teams spend weeks debugging failures that originate in mismatched assumptions between the two roles.
Common Points of Friction and How Strong Teams Resolve Them
Several recurring friction points appear in teams where NLP developers and data engineers work together for the first time:
- Schema mismatches: The NLP developer expects data in one format; the pipeline delivers it in another. Strong teams resolve this by establishing a shared data contract early, documented and version-controlled, that both sides treat as authoritative
- Data quality disagreements: NLP developers often discover data quality issues during model evaluation that data engineers were unaware of. Strong teams build data quality monitoring into the pipeline itself rather than relying on model evaluation to surface these issues
- Model versioning and pipeline coupling: When a model is updated, the pipeline that feeds it may need to change as well. Teams that treat model versioning and pipeline versioning as separate concerns consistently run into deployment problems. Strong teams coordinate these changes explicitly
- Latency expectations: NLP models, particularly large ones, have inference latency that affects pipeline design decisions. Data engineers who understand these constraints can design pipelines that batch inputs appropriately, rather than sending individual records that create unnecessary overhead
Building and Staffing the Team
Why Both Roles Are Hard to Hire Locally
NLP developers and data engineers are among the most in-demand technical profiles in the current market. Both roles sit at the intersection of multiple disciplines, which means the pool of practitioners with genuine production experience is considerably smaller than the pool of candidates who list the relevant technologies on a CV.
For NLP specifically, the gap between theoretical knowledge and production capability is particularly wide. The rapid development of large language models has produced a large number of engineers who have worked with these models in research or experimental contexts but have not yet navigated the full lifecycle of deploying and maintaining a language system in a production environment. That production experience is what most teams actually need, and it is genuinely scarce.
Data engineering faces a different version of the same problem. The tooling landscape changes quickly, and engineers with deep experience across the full stack, ingestion, transformation, orchestration, storage, and observability, are difficult to find. Local hiring in most Western markets involves long lead times, high salary expectations, and significant competition from well-funded technology companies offering attractive packages that smaller organizations cannot easily match.
How to Source NLP and Data Engineering Talent Effectively
Given the scarcity of local talent, many organizations building language-driven AI products have moved toward international and remote sourcing models. Eastern Europe, Latin America, and parts of Southeast Asia have developed strong communities of NLP and data engineering practitioners with production experience in international projects.
Dedicated outstaffing and staff augmentation models work particularly well for these roles because both NLP developers and data engineers produce better outcomes when they work continuously on one product rather than rotating across multiple client engagements. A data engineer who has spent six months building and maintaining a specific pipeline knows its failure modes, edge cases, and operational characteristics in ways that a contractor arriving fresh to each engagement does not. The same depth of knowledge applies to NLP developers who have worked through multiple model iterations on a single product.
For organizations that need to move quickly, engaging specialist staffing partners with experience placing AI and data engineering talent reduces both the search time and the risk of a poor match. Pre-vetted candidates with verified production experience and references from comparable projects start contributing meaningfully in weeks rather than months.
Conclusion
Building the AI team behind a language-driven data product requires clarity on two things: what each role entails and how the two roles depend on each other. NLP developers and data engineers are not interchangeable, nor are they independent. The quality of a language-driven product is determined as much by the reliability of its data infrastructure as by the sophistication of its language models. Teams that understand this from the start build systems that hold up in production. Teams that discover it midway through delivery spend months fixing problems that better planning would have prevented. The hiring challenge is real but manageable. Both roles are scarce in local markets, but experienced practitioners are available through international sourcing channels, which compress hiring timelines and reduce the cost premium associated with local recruitment. What matters most is not where the engineers are located but whether they have the production experience the product requires and whether they can work together effectively within the team structure the organization provides.
Language-driven AI products are among the most technically demanding systems being built today. Getting the team composition right is the most important decision made before a single line of code is written.