Despite the latest AI advancements, Large Language Models (LLMs) continue to face challenges in their integration into the enterprise landscape. While demonstrating significant text manipulation and reasoning results, LLMs are significantly underperforming in complex analytical tasks. Language models must still learn to work with data lakes and provide accurate, actionable insights based on user text prompts. Let’s explore various aspects of this issue, together with Kiryl Bucha, the CTO and Solution Architect at DataMola, a developer of advanced analytics for decision support.
Generative Model Limitations in Data world
As a Solution Architect, I’d like to emphasise that the current level of GenAI is not yet enterprise-ready for adoption to the Data Lake world. We are in the early stages of innovation, akin to the era of steam engines. While GenAI paints a bright tech-powered future for business, we are still far from having a reliable system with a rich toolkit, clear policies, and established processes for integrating it into complex Data Lake Architecture.
Currently, we adopt an engine that has to deal with unpredictable parameters called AI hallucinations around 3% of the working time. This unpredictability poses a major challenge for engineering teams, whose task must be stabilising the technology rather than racing for Business Insights Deliverables.
Why is Retrieval-Augmented Generation (RAG) not a Blue/Red Pill for Data Lake?
Recent advancements in LLMs have led to a reduction in AI hallucination rates from 3% to below 1%, as noted on the Hallucination leaderboard. This achievement has instilled confidence in the effectiveness of reasoning engines. However, BI data engineers remain sceptical that a quality solution could appear so fast. They understand that success isn’t about finding a quick fix; rather, it relies on adhering to established processes and implementing clear LLM-generated data validation plans.
Businesses commonly store data in tabular formats and archived files. However, because LLMs are primarily trained on sequential data, they often encounter challenges processing these structures. To address this, several approaches have been proposed, including:
- representation learning (converting data into vector embeddings)
- programming language representations (encoding data using constructs like Python dictionaries)
- linearisation methods (converting data into natural language).
While representation learning shows promise, the latter two strategies may not effectively bridge the gap between text-based training and the structured nature of data lakes. This is primarily due to the sheer volume of structured data involved.
Software and data engineers have long sought to balance compression and performance in distributed systems, making it unlikely they’ll convert all data into code or natural language formats. Therefore, representation learning still remains the most viable approach, but it also faces insurmountable obstacles and challenges.
1) Balancing between Impoverishing and Overfitting
The major challenge of using RAG is determining how much data to extract from a data lake for accurate responses. Extracting too much raises the risk of overfitting, as the model merely repeats source material or worse, generates incorrect results due to duplicated records. Extracting too little data can lead to impoverished outputs, missing critical information for analysis.
Data lakes are designed to provide data at various granularities and dimensions, but finding the right balance in data retrieval is essential to ensure meaningful and accurate results.
2) Context Handling
A good example would speak for itself. While a monthly bank account balance and debit/credit turnover might share the same scope, these two systems require different aggregation methods. You can’t simply sum monthly balances to derive a quarterly figure; instead, you need the balance at the end of the quarter. Conversely, debit/credit turnover can be summed easily across periods. Such nuances necessitate that LLMs understand the context of retrieved data not just from the content itself, but also from the underlying data extraction logic and what specific measures are being utilised.
3) Hallucinations
Generative models must be safeguarded against “hallucinations,” as enterprise data lakes cannot tolerate inaccuracies, even at rates below 1%. There is no world where 2+2 = 5. The consequences of such hallucinations could cost the company a lot of money.
Why is MAS (Multi-Agent System) not a Magic Bullet for Data Lake, either?
Engineers often use a time-tested methodology: breaking down problems into manageable parts. This has led to development teams actively exploring multi-agent systems (MAS), where several LLMs interact to boost the efficiency of GenAI algorithms in big data analytics and linguistic interpretation.
However, as a person who’s long been within the industry, I comply with the fact that the inherent complexity of MAS makes the development lifecycle and release processes for Data Lake GenAI solutions a considerable challenge.
The newest NVIDIA AI Blueprint for RAG offers a basis for developers, but doesn’t show the interaction between agents in the architecture slide (see Illustration 1).
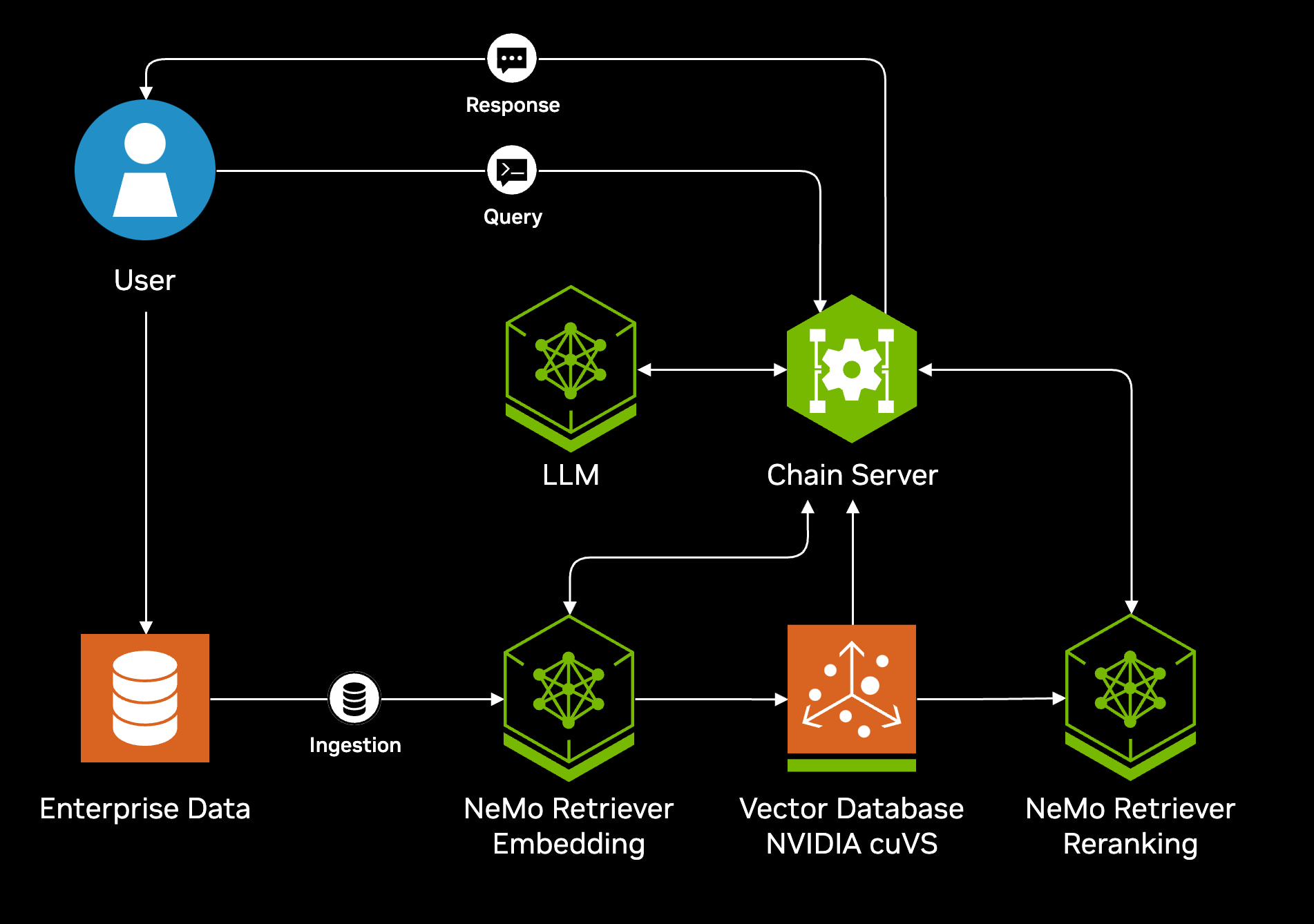
Illustration 1. Architecture Diagram by NVIDIA. Source: https://build.nvidia.com/nvidia/build-an-enterprise-rag-pipeline
The most intriguing part is hidden behind the Chain Server icon. In the simplest scenario you’ll see the multiagent system communication flow as suggested by Meta Blog – building knowledge graph agents with llamaindex workflows (Illustration 2). According to their design, each AI agent makes an independent LLM call, introducing a potential 1% workflows chance of AI hallucination. This communication flow can be implemented using a reactive Actor Modelling strategy. The Actor Model is a reactive programming paradigm that enables the creation of reactive systems adhering to reactive principles. All communication between actors in the Actor Model is based on asynchronous, non-blocking messaging. Consequently, it inherently supports the elastic and resilient aspects of a reactive system.
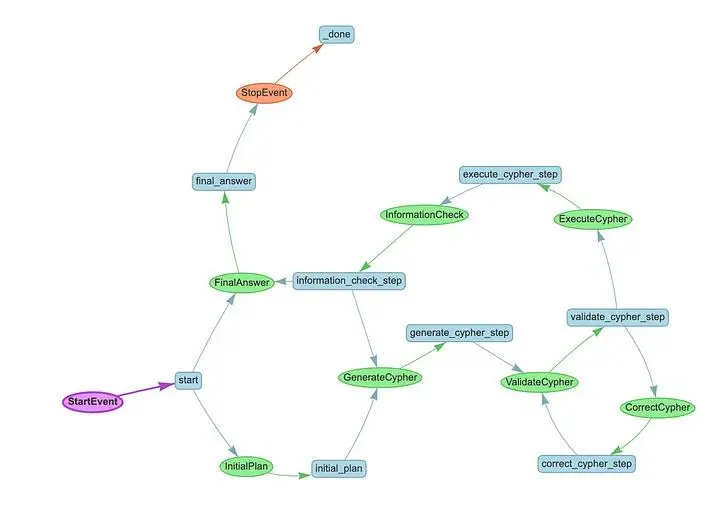
Illustration 2. Architecture of Communication Flow by LlamaIndex. Source: https://www.llamaindex.ai/blog/building-knowledge-graph-agents-with-llamaindex-workflows
Unfortunately, there’s a lack of market-ready products to effectively manage development teams and enforce necessary restrictions and policies for MAS development. As previously stated, we are in an era of innovation, not adoption. Let’s look through the systems AI engineers require to build to control the development lifecycle of such applications:
- Unit Test Framework: Each Agent should guarantee correct Output based on valid Input, providing development teams with a tool to evaluate GenAI LLM responses effectively.
- Integration Tests Framework: Agents are enhanced at different speeds and cadences over time, requiring a CI/CD process to ensure communication between agents with varying release versions through integration tests.
- Profiling and Tracing Framework: Addresses the unpredictable LLM response latency. This framework enables the multi-agent system to trace and react to all events, maintaining acceptable latency.
- Scaling Automation Framework: If response latency is unacceptable, this framework scales up the slow-performing components and scales them down for cost-effectiveness.
- Exception Handling and Feedback Loop: Incorporates incident management and end-user feedback monitoring, enabling the multi-agent system to reevaluate dialogues to identify areas for improvement and instances of AI hallucination.
Security Risks with RAG
LLMs face significant challenges when implementing secure data extraction in RAG architectures. These difficulties can be grouped into three core security requirements: multi-tenant data isolation, column-level security, and row-level access controls.
Multi-tenancy Data Isolation Challenges
Multi-tenant data lakes store information for user groups within shared infrastructure while requiring strict data isolation.
1) Dynamic Access Control. Ensuring tenants only access their data requires real-time policy enforcement. LLMs often lack native integration with RBAC systems, increasing the risk of cross-tenant data leaks. As a result, engineers must develop customised connection pool coordinators to validate tenant calls.
Unfortunately, this technical implementation extends multi-tenancy requirements to profiling and tracing frameworks, exception handling and feedback loops, LLM chat memory management, and other areas, leading to a dramatic increase in operational costs.
2) Logical vs. Physical Separation. Physical separation necessitates a coordinator to redirect query calls, while logical separation depends on precise filtering. Regardless of whether separation is physical or logical, a sophisticated Digital User Identification & Authentication system must be implemented. Furthermore, this system is required for each agent.
Therefore, the engineering team must implement Digital User Identification for every LLM conversation session.
3) Compliance Risks. Regulations such as GDPR mandate strict access controls. Compliance invariably involves adhering to external policies when storing or manipulating data. In the context of GDPR, sharing data subject to GDPR with an agent necessitates implementing all required procedures for that agent. Furthermore, businesses often have numerous similar compliance policies, all of which are typically enforced within the data lake. Therefore, sharing data with agents requires implementing all compliance processes for each agent.
Column-Level Security Limitations
Column-based security restricts access to sensitive fields.
- Policy Awareness. LLMs lack an inherent understanding of column-level permissions and may retrieve restricted columns from LLM Chat Memory without guardrails.
- Metadata Exploitation. Attackers can use LLM-generated queries to probe column names or infer scheme details, exposing sensitive data structures.
Row-Level Security Complexities
Row-based security filters data based on user roles or attributes. However, vector databases, often used to enhance LLM capabilities, typically lack native row-level security (RLS). This forces developers to implement access controls at the application layer, creating a potential vulnerability to prompt injection attacks that could bypass intended security policies and expose sensitive data.
Exploring Development Opportunities
Integrating LLMs with data lakes in multi-agent systems remains a big to-do task for the tech pros. So the question is: what can actually be done about it? What directions should be developed?
Based on our 10 years of experience at DataMola, we introduce dataMill: a new engine for extracting actionable insights from data lakes. It has become possible due to the advancements in metadata management and agile data modelling.
The following outlines a structured methodology for building a data warehouse (DWH) that will calculate KPIs from raw data lake content while leveraging LLMs for semantic enrichment and governance.
1) Metadata-Driven Object Definition. To calculate KPIs like “Average User Profit” or “Subscription Churn Rate”, LLMs analyse metadata to identify required objects (columns, schemas, and transformation rules) for KPIs calculation.
2) RBAC and Data Governance. Role-Based Access Control (RBAC) ensures users only access authorized data. Columns and records will not go through the injection process of the dataMill engine. User limitation and restriction will be added to the Semantic part of produced RAG Documents.
3) Anchor modelling for Scheme Design. Anchor modelling provides a flexible scheme to handle temporal and structural changes in data lakes:
- Immutable data storage: each attribute (e.g., sales figures) and tie (e.g., customer-product relationships) is stored separately, enabling non-destructive schema evolution and creation via LLM JavaScript Object Notation (JSON) response.
4) KPI Calculation Planning. LLMs optimise aggregation logic and resolve scope issues:
- Measure definition: using natural language queries (e.g., “Calculate monthly revenue growth”) from the company documentation library, LLMs generate calculation expressions based on Anchor JSON scheme.
- Custom aggregation: GPU-accelerated engines like Voltron Data: Theseus process large datasets in parallel, reducing latency for complex KPIs. Smaller amount of data could be processed inside the in-memory DuckDB.
5) ETL Processing with Apache Ibis and GPU. The DataMill engine leverages Apache Ibis capabilities for ETL tasks.
- GPU/In-Memory acceleration: Immutable data storage of Anchor modelling provides a way to effectively parallelize injection of the raw data to stage level.
6) RAG Output with Semantic Metadata. Results are returned as RAG documents:
- Semantic layer: LLMs annotate results with usage guidelines (e.g., “KPI-2 excludes test accounts”).
- Dynamic documentation: auto-generated metadata explains data provenance, calculation logic, and refresh schedules (data freshness).
- Anchor Modelling Scheme: JSON scheme definition included in metadata.
Therefore, by leveraging the synergy of Anchor modelling’s flexible scheme, accelerated processing, and LLM-driven automation, it becomes possible to efficiently extract actionable insights from data lakes while maintaining agility, security, and governance. This methodology further facilitates the creation of an isolated Tabular Agent, decoupled from the existing data lake and utilising dynamically provisioned resources that are released upon document generation.