Large language models (LLMs) such as GPT, LLaMA and Claude have captured headlines and imaginations alike. They are described as breakthroughs in artificial intelligence, capable of answering questions, drafting essays, and even writing code. Yet behind this dazzling surface, a quieter, less glamorous technology does much of the heavy lifting: embeddings.
If the LLM is the orchestra, embeddings are the sheet music, providing structure and coherence to what would otherwise be noise. They turn language into mathematics, mapping meaning into vectors so that machines can compare, retrieve, and reason about information. Without them, LLMs would be powerful but unwieldy, forever struggling to recall the right knowledge or maintain context.
What Are Embeddings?
An embedding is a numerical representation of language — a string of numbers that captures the semantic essence of a word, a sentence, or an entire document. Two concepts with similar meanings will sit close together in this high-dimensional space. For instance, “Paris” and “France” cluster nearby, while “Paris” and “Zebra” are far apart.
This simple mathematical trick allows machines to do something profoundly human: recognise relationships between ideas. When you search, translate, or ask a chatbot a question, embeddings are quietly at work, guiding the model toward the most relevant pieces of information.
How They Support Large Language Models
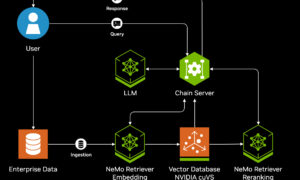
One of the most important uses of embeddings is in retrieval. Modern LLMs are not asked to remember everything. Instead, vast libraries of text are pre-converted into embeddings and stored in databases. When a user asks a question, the query itself is turned into an embedding, compared against the database, and the most relevant results are retrieved and fed into the model’s prompt.
This approach, often called “retrieve-then-generate,” has transformed AI. It allows a chatbot to appear as if it knows everything, while in reality it is supported by an embedding-driven memory system. The LLM generates fluent language, but embeddings decide what information it sees.
Embeddings also underpin semantic search. Unlike traditional keyword systems, which match only exact words, embedding-based search recognises meaning. Ask for “AI tools for small businesses” and it can return results that use different wording but capture the same concept. The same principle drives recommendation systems, clustering similar content or products together based on proximity in embedding space.
Even the process of fine-tuning and prompt engineering leans on embeddings. Instructions and examples can be represented as vectors, helping models adapt more systematically to new tasks. In this way, embeddings are not just supportive but foundational to the LLM ecosystem.
Why Embeddings Matter
The importance of embeddings lies in their efficiency. Training or fine-tuning a large model from scratch is resource-intensive. Updating an embedding database, by contrast, is relatively lightweight. A company can refresh its embeddings daily or weekly, keeping its AI assistant up to date without retraining the underlying model.
They also enable multilingual and multimodal systems. Because embeddings capture meaning at an abstract level, a Japanese sentence and its English translation can occupy nearly the same position in embedding space. This makes it possible to build systems that seamlessly cross languages. Extending the same approach to images, audio, and text opens the door to more holistic forms of AI that can reason across media.
Finally, embeddings offer a measure of transparency. Unlike the opaque processes inside LLMs, embeddings can be visualised. Plotting them shows clusters of concepts, outliers, or unexpected relationships. This gives researchers and practitioners a tool to diagnose bias, detect drift, or refine systems that would otherwise be black boxes.
Applications for Businesses and Consultancies
For consultancies and enterprises, embeddings are more than theory. They are practical tools that make AI usable. Internal documents, product manuals, or customer support logs can all be embedded, creating searchable knowledge bases that fuel custom chatbots. Educational institutions can embed multilingual resources, ensuring that students can learn in their own languages.
At Language Media’s Data Consultancy, embeddings are part of the toolkit that makes advanced AI accessible to organisations of all sizes. They allow small businesses to enjoy capabilities once limited to tech giants: semantic search, intelligent recommendation, and cross-lingual content delivery. The strength of embeddings is not that they replace LLMs, but that they make them practical, affordable, and adaptable.
Looking Ahead
As attention remains fixed on the drama of larger, more capable LLMs, embeddings will continue to do their quiet work in the background. They will power retrieval-augmented generation, make education more inclusive, and enable businesses to deploy AI in targeted, efficient ways.
It is tempting to see LLMs as the stars of the show, but in reality they stand on the shoulders of embeddings. The vectors that map meaning into space are the scaffolding that makes fluent, context-aware language generation possible. As AI matures, it may be embeddings — not ever-larger models — that define how this technology scales and serves society.
The rise of LLMs is real, but embeddings are the reason they can rise at all. They are the hidden architecture, the hard workers in the background, transforming raw text into structured meaning and bringing the promise of AI closer to everyday reality.