Today’s marketplace involves the consumption, organization, and leverage of big data from a wide array of sources. To stay competitive, businesses must take advantage of all these sources to pick up any insights or benefits for improved business performance.
Before this data can be used at the decision-making level, it must first be appropriately managed. A company must use modeling, software, data monitoring, and more to ensure every piece of vital information is accurate and reliable for use down the road.
The Complexity of Data Management
Data management involves creating infrastructure through policies, practices, and procedures to ensure effective architectures of data lifecycles. Without these structures, maintaining accurate, reliable, and consistent data is next to impossible, especially given the complexity of sources and volume of intake.
This complex system involves everything from data governance for planning management systems to data security so that only authorized users can access predetermined information. On top of all of that, metadata is required to make all of this collected data easily accessible for searching.
To oversimplify the concept, data management takes a complex system and makes it easy to use. The point of this is to create faster speed to value for any given business. When all of the competitors in a market niche are leveraging data in real-time to respond to every evolving market and consumer need, the only way to remain at that level is to have the same capabilities.
That requires navigating through multiple decision-making points in the use and infrastructure of your data management functions like :
- Data Source Assimilation: updating architecture and modeling based on new observations while also cleaning, verifying, and ensuring all data is accurate and reliable.
- Data Consolidation: corralling your various data into a single place of access and observation to drive insights and decision-making.
- Data Preparation: structuring and organizing the data into valuable entities that can be used by various tools or processes for insight.
- Data Monetization: using data to grow business revenue by turning it into quantifiable financial benefits.
Each of these functions requires a carefully flushed-out structure, and that is challenging when business owners are faced with so many software solutions designed for each step of each function. Creating a data management system that works for a specific business is overwhelming is a slight overstatement, given the vast number of options available.
What Makes Data Management Unique?
Think of data management as a living ecosystem. Even cookie-cutter software solutions designed for only a few functions have to be adapted to the state of the business implementing the new system. This ever-evolving characteristic makes data management one of the most exciting fields as well as one of the most complex. Every business needs a solution personalized to the unique nature of the enterprise.
There is no “one size fits all” solution in the current SaaS (Software as a Service) vendor landscape. That is because the insights gained through proper data management are unknown until the system is implemented. When a business starts to gain new knowledge, there will be a demand for a change or adaptation in the system being used. If a cookie-cutter product doesn’t allow for this evolution, it is not providing quality solutions for the business.
The need to overcome speed to value and highly relevant data for a business requires a different approach. It only makes sense to focus on service-led solutions that adapt, grow, and expand with the company.
Using Software Enabled Services to Meet Data Challenges
Software-enabled services do benefit a business with data management. Companies are focused on outcomes that place a high priority on data analysis. Being able to crunch the latest sales figures concerning customer demographics and current internal workforce levels is critical to deciding whether you need more staff, more marketing, or a reduction in human assets performing repetitive tasks.
All of this analysis must be personalized to the needs of the business. It has to consider each specific function, and that is going to be wildly different when you compare a line of jewelry stores to a group of hospitals. The point is that one solution is not going to suffice.
Then there is the human factor. Errors and interpretation are much easier to handle when performed by a software system. Even your best worker, scientist, or data expert will occasionally make a mistake. Humans cannot make the leaps of intuitive data investigation that software can. With a high need for business relevance in data analysis, a solution that can uncover hidden insights, assets, efficiencies, and potential risks are far more valuable.
That is where an adaptable service is more beneficial than a strict SaaS solution. It can consider data relevance with various business inputs through every data interpretation stage. With a service-led technology, you see distinct differences compared to SaaS solutions like:
- The ability to blend personalization into the mix of data standardization, so outcomes are far more relevant to a business’s current needs and goals.
- Traditional data management service models use a layer of services and methodologies to create software solutions. Services-enabled solutions leverage software routines to automate business rules by applying them to specific situations based on an enterprise’s unique needs – making them more adaptable over time.
- Service-based solutions begin with the desired business outcome in mind first. Then it breaks down the requirements and processes needed to achieve that result. This leverages a library of software automation routines and blends them together using methodologies to enforce discipline and quality while building data governance routines for accuracy and compliance.
The Alternative Data Management Service Model – Services Led Technologies
When looking at the available options on the market, it only makes logical sense to go with a solution that changes and adapts to the need of a business as it grows and responds to the fast-paced marketplace. Trying to retrofit software into this scenario seems a waste of time and money when there are solutions that will evolve on their own.
At a small scale, this could be a team of birth centers trying to use a patient management system that doesn’t allow for the intake of certain locations or demographic data for later analysis.
On a large scale, this could be a government organization trying to capture data from neighborhoods and break it down over time as those locations fluctuate with different people moving in and out.
Taking all that data from such a wide range of sources could be everything from sampling to tax information. That requires a lot of data preparation to ensure all sources are properly consolidated into the correct data lake. The solution requirement here is to analyze the data correctly and then categorize it as needed for insight while also transforming it to the various needs of interdepartmental use, all while cleansing it to remove duplicates and ensure compliance. That is a lot of complexity to consider for any system.
The government agency in question has the option to purchase a COTS (Commercial off the Shelf Software) subscription through a SaaS model based on a demo that will most likely not adapt over time. This will require having the expertise on hand to install, implement, and configure that software platform while identifying any gaps and customization needs.
Then, that expert or team will need to create software routines by utilizing standard software solutions like Python, SQL, and more to fill in the gap logic. That requires a lot of iteration and investment on the organization’s side. Trying to manage and maintain various components of the SaaS platform will become more challenging as the vendor updates the software.
The result is a locked-in commitment to a single vendor regardless of the fit and flexibility of the existing software because the cost of starting over almost becomes a sunken endeavor economically. A business will have introduced human assets on a team to ensure the software platform and new adaptive custom code are always functioning. The financial commitment to this kind of solution to govern and manage any scalability has high long-term costs.
The alternative solution is to utilize a services-led data management service model. This solution will understand the required business outcome by evaluating the processes and elements required to achieve these goals. Many of these solutions rely on open-source software routines with vibrant communities who love to tweak and improve such tools.
A services-led solution will integrate various software routines with the correct framework that is flexible enough to ensure the completeness of processes as well as adequate controls for observability and governance – a critical need if the client is a government organization.
The modular design is easier to reuse in other conditions. It integrates smoothly with other platforms because it naturally avoids the locked-in vendor-proposed technology. There is adaptability and flexibility that meets the specific needs of each business requirement.
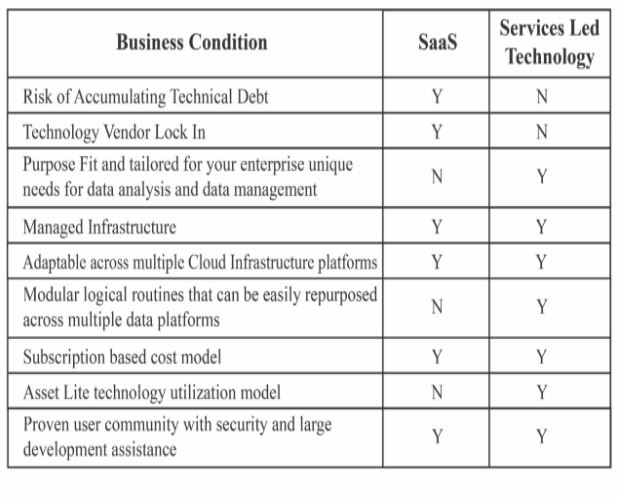
High-Level Comparison between SaaS and Services Led
Conclusion
Industry leaders in data management have recognized this need to create a more services-led solution for businesses and organizations. This has created the term “servware” where analytical services and software converge to disrupt the traditional vendor practice of locked-in software solutions.
Even if you look at Gartner’s Data Ops Essentials, the emphasis on servware solutions cannot go unnoticed. Many open-source technologies are actively participating in this industry today that empower a more adaptable service-led solution. These include:
- Soda.io – Data Observability
- dbt – Data Transformation
- Datahub – Meta Data Management
- Airflow – Data Orchestration
- Meltano – Data Ingestion
- Great Expectations – Data Validation
- Superset – Data Visualization
At NextPhase, we have successfully worked with many of these industry-leading open-source technologies. This has allowed us to create a library of automation routines that can be deployed and integrated into customer services-led solutions for any of our clients. Two common use cases of such servware solutions in the market today include:
Data Catalog as a Service – improving the overall data quality by introducing powerful new tools to observe, trace, and ensure accuracy by leveraging logical metadata management.
Data Validation as a Service – increasing the speed to a value of data conversions by identifying gaps, comparing heterogeneous data, and streamlining quality checks.
Reach out to our team today to discuss how these powerful services-led solutions can revolutionize your data management service models. We look forward to customizing a new solution for your unique business needs.