Trust: The Silent Foundation Beneath Cryptography
In many security discussions, it’s common to hear a quiet confidence in the power of cryptography, the assumption that mathematical rigor makes systems unbreakable, that if data is encrypted and signatures are valid, trust becomes irrelevant. But that assumption misses a fundamental truth: cryptography only works if you already trust something.
Every verifiable cryptographic operation, from checking a TLS certificate to validating a digital signature or decrypting a secure message, ultimately relies on a pre-established root of trust. When your browser displays a secure connection icon, it’s because it trusts a certificate authority (CA) pre-installed by your operating system or browser vendor. When a software update is verified, it’s accepted because the signature was made with a public key that your system was often told by a vendor to trust. Even advanced systems like zero-knowledge proofs or blockchain consensus models require initial trust assumptions: someone had to create the keypair, sign the genesis block, or define the root of validation.
In this way, cryptography doesn’t eliminate trust, it formalizes and obscures it. It gives us mechanisms to verify integrity and authenticity, but the authority to verify must originate from a place we’ve chosen or been told to trust. Someone, somewhere, has to say: “I trust this root.”
This becomes even more complex in cloud-native environments. Take a seemingly simple example: an application that uses Wako, a hypothetical IDaaS vendor, for identity. You are trusting Wako, yes but you’re also implicitly trusting everything Wako depends on: their use of AWS, the reliability of their CI/CD pipeline, the integrity of the machines they build on, and even the physical security and firmware integrity of the hardware in Amazon’s data centers. These dependencies quickly spiral into a transitive, recursive chain of trust, much of which you can’t see and didn’t choose. And yet your system and your customers depend on it.
This is the quiet truth that makes trust a cornerstone of all modern systems. It’s not a layer we can simply abstract away. Trust is deeply embedded in protocols, in vendor contracts, in code we didn’t write, and in defaults we rarely challenge.
This is where the conversation must shift from “how to eliminate trust” to “how to understand, measure, and manage it.” And to understand why that matters, we only need to look at where trust misapplied or unexamined has brought systems down.
In the last decade, some of the most devastating cybersecurity incidents didn’t happen because cryptography failed or passwords were guessed. They happened because trust unverified, inherited, or misplaced was abused.
In late 2020, the SolarWinds breach made headlines worldwide. Attackers compromised the build system of a widely trusted IT management tool and inserted a backdoor into its software updates. Organizations, including U.S. government agencies, installed this poisoned update precisely because they trusted the update channel. Cryptography wasn’t broken. The signature was valid. But trust had been weaponized.
Three years later, in 2023, the MOVEit data breach once again reminded us of the dangers of excessive trust. MOVEit, a managed file transfer product embedded in critical workflows across finance, healthcare, and government, was found to have a zero-day vulnerability. Attackers exploited it silently exfiltrating sensitive data without tripping alarms. Organizations had integrated it deeply, treating it as a safe, trusted backbone. When that trust turned out to be misplaced, the damage was swift and wide-reaching.
More recently, in 2025, AustralianSuper, one of the largest pension funds in the country, suffered a major attack due to credential stuffing. The breach wasn’t technically complex, nor did it involve advanced cryptanalysis. It simply exploited the fact that multifactor authentication had not been enabled, despite repeated warnings. The system had trusted that a username and password were sufficient and attackers took advantage.
These stories aren’t isolated. They’re part of a larger pattern. Again and again, we see that trust, not cryptography, is the real vulnerability. When trust is static, implicit, or opaque, it becomes a liability. And the more complex our systems become, the more we are forced to extend trust to vendors, libraries, dependencies, third-party services without truly understanding the scope of what we’ve delegated.
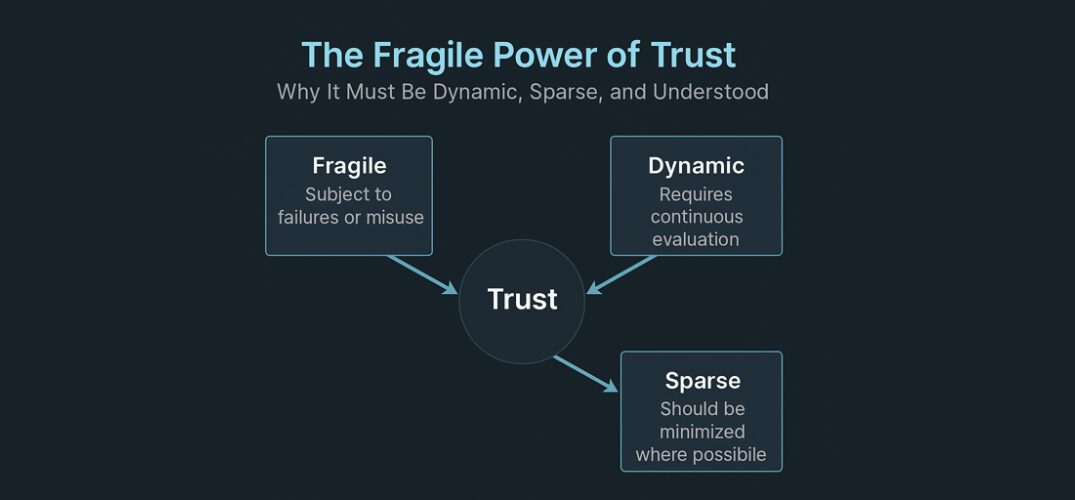
These failures show why we need a different model. One that treats trust not as a binary state but as a dynamic property. One that assumes compromise is always possible, and demands continuous validation. One where trust is earned, observable, contextual, and revocable.
That model is known as Zero Trust and it’s not a product or a buzzword. It’s a strategy for surviving in a world where the old boundaries of security no longer exist.
Mr.Nandagopal Seshagiri is a seasoned cybersecurity architect, a Distinguished Fellow of the Soft Computing Research Society (SCRS) and a Member of IEEE, with over a decade of experience designing and implementing secure systems at scale. His work spans both product and infrastructure domains, with a particular focus on applying Zero Trust principles in real-world, high-stakes environments.
At the forefront of identity and cloud security, Nandagopal has led initiatives ranging from secure machine-to-machine authentication and ephemeral credential systems to enterprise-grade MFA platforms and cloud access gateways. His approach blends technical depth with architectural rigor, always grounded in the belief that trust is not a default, it’s a decision, and one that must be continuously earned.
Through years of building and securing distributed systems, he has developed a nuanced, pragmatic view of Zero Trust not as a marketing slogan, but as an operational necessity in today’s fragmented and hyper-connected landscape. He writes and talks at prestigious international conferences as keynote speaker on topics related to trust and how to bridge deep technical insight with actionable strategy for builders, architects, and security leaders alike.
In Zero Trust We Trust: Deconstructing the Catchy Contradiction
“Zero Trust” is one of the most provocative and widely adopted phrases in cybersecurity today. At first glance, it sounds absolute: trust no one, no thing, no action unless proven otherwise. But the moment you look beneath the surface, a contradiction emerges. We clearly do trust some things, identity systems, certificate authorities, hardware manufacturers, SDKs, cloud providers. So what does Zero Trust really mean?
Nandagopal emphasizes, “The answer lies not in eliminating trust but in redefining it. Zero Trust is about replacing implicit trust with measured, conditional, and explicit trust.”. It transforms trust from a static assumption into a dynamic property. Rather than trusting once and continuing indefinitely, Zero Trust encourages us to constantly reevaluate whether trust is still deserved, given the context, behavior, and time.
This principle becomes particularly important when you realize how much of modern computing is built on pre-established trust anchors. Even cryptography, which is often perceived as a substitute for trust, relies on initial assumptions. A secure web connection, for example, depends on your browser trusting a root certificate authority. A signed software package is only verifiable if you trust the origin and safekeeping of the signing key. Cryptographic primitives are sound, but their value depends entirely on the correctness and integrity of the trust chain that feeds into them. In short, cryptography does not eliminate trust, it codifies it.
When you build or run services in today’s cloud-based ecosystem, your trust model rapidly becomes both deep and wide. You might directly trust a cloud identity provider to authenticate users, but that decision pulls in an entire transitive chain: their infrastructure platform, their code signing processes, their hardware roots of trust, and their operational security practices. The result is a sprawling trust graph, often unacknowledged, which quietly becomes part of your system’s security posture.
This is why Zero Trust as a strategy matters. Nandagopal argues that “it recognizes that trust is both fragile and cumulative.” Each additional dependency widens the surface area. Each long-lived credential extends the window of risk. Each system that fails to revalidate trust contributes to an illusion of safety that may no longer be justified. Trust, under Zero Trust thinking, is never assumed—it is earned, proven, bounded by context, and decays over time.
Zero Trust also reframes how we think about applications. Traditionally, security has been seen as something handled at the perimeter or by the identity provider. But applications—especially those enabling privileged actions—must take on an active role. This includes implementing step-up authentication for sensitive operations, enforcing real-time risk-based policies, and enabling multi-party approvals where necessary. It also includes rejecting stale sessions, rotating secrets frequently, and observing not just who is making a request but how, from where, and with what level of assurance.
In this model, machine-to-machine interactions also become first-class citizens of the trust graph. Rather than relying on static tokens or hard coded secrets, systems should prefer ephemeral credentials, workload identity, and short-lived assertions. The age of a secret becomes a critical risk signal. Machine identity should be issued based on attestation, posture, and the operational context in which a service is running, not just its presence in a config file.
As systems grow, the complexity of managing trust grows with them. No human operator can fully reason about a live trust graph spanning dozens of microservices, multiple cloud accounts, and third-party APIs. This is where instrumentation, graph-based visibility, and eventually automation and AI become necessary. Questions like “Am I trusting this service?” or “Where does this credential reach?” are no longer straightforward. Yet these are the questions that matter most when designing and securing modern systems.
“A Zero Trust architecture answers these questions not by reducing them to yes-or-no gates, but by making trust observable and contextual.” proposes Nandagopal. Every decision to allow or deny should be auditable, traceable, and rooted in current information. Risk should be calculated in real time, using signals from the user, the device, the network, the authentication method, and the resource being accessed. Trust should be limited in scope, tied to least privilege, and time-bound.
And so we return to the phrase: “In Zero Trust We Trust.” At first glance, it may seem contradictory, even ironic. But in fact, it captures the essence of what Zero Trust aims to accomplish. We still trust, but we trust differently. We trust with clarity, with conditions, and with expiration. We acknowledge that trust is essential, but we no longer let it operate silently.
Zero Trust is not a rejection of trust. It is a shift in how we manage it. It is not a technology or a vendor solution, it is a security philosophy that brings visibility and control to something we have always relied on, but rarely challenged. It replaces assumptions with accountability. And in doing so, it helps us build systems that are not only more secure, but more resilient, adaptable, and aligned with the realities of the modern computing landscape.
Agility and management of Trust
In modern cloud-native systems, trust is rarely local. When you make a decision to trust a service, a library, or a provider, you are also—often unknowingly—trusting everything that service relies on. “This is the essence of the transitive trust problem: each explicit trust decision brings with it a chain of implicit dependencies that may be far outside your control, visibility, or even awareness.” observes Nandagopal.
For example, imagine you authenticate users through a cloud-based identity provider. You are explicitly trusting that provider to correctly verify credentials, issue tokens, and manage user sessions. But by doing so, you also inherit a broader trust surface. You are trusting their underlying infrastructure provider, their API gateway, their certificate management lifecycle, their internal build tools, their software libraries, and the operational discipline of their engineering team. In most cases, you do not have visibility into these dependencies. Yet your system’s security now depends on all of them functioning correctly and being safeguarded from compromise.
This transitive model of trust is not unique to identity systems. The same applies to cloud platforms, container registries, telemetry agents, CI/CD pipelines, and open-source packages. Each time you use a service, you consume a nested set of trust relationships. These relationships are recursive, dynamic, and usually undocumented. What seems like a narrow, intentional trust choice often becomes a sprawling web of indirect reliance.
One of the core challenges in managing transitive trust is that it grows silently. You may audit your direct integrations and credentials, but rarely do organizations model the second- and third-order connections that follow. And yet, these hidden dependencies are just as capable of introducing risk. A misconfigured CDN used by a vendor can affect the availability or integrity of your authentication flow. A compromised third-party SDK embedded in a trusted service can introduce backdoors. Trust failures do not respect contractual boundaries.
Given this, it becomes clear that trust is no longer a static configuration. It is a dynamic system property. The real question shifts from “Do I trust this vendor or service?” to “Where does that trust extend, and how far does it reach?” Unfortunately, most systems cannot answer that question in a reliable or timely way.
To address this, organizations need new approaches. “One strategy is to explicitly model trust relationships as graphs,” opines Nandagopal. This means tracking which services, libraries, machines, and third-party APIs are involved in your application workflows, and capturing metadata about their origin, risk posture, and lifecycle state. Another is to use tagging and dependency declarations across infrastructure-as-code and service catalogs, so that transitive relationships can be queried and analyzed. Over time, organizations can layer automation on top of this visibility to detect when trust paths change or when a dependency enters a high-risk state.
Ultimately, the transitive trust problem is not a mistake—it is a byproduct of scale, abstraction, and integration. But ignoring it is not an option. To build resilient systems, we must stop viewing trust as a local, binary decision. Instead, we must treat it as a flowing, interconnected network of assumptions, each of which needs to be surfaced, contextualized, and periodically challenged. Only then can we begin to reason intelligently about what we are trusting, and whether that trust is still deserved.