
Trust isn’t a soft concept. It’s built through timely data delivery, architectural consistency, and the prevention of silent failures. When a customer clicks “confirm” and the system drops a write, you lose more than revenue. You lose the relationship.
Modern digital services, shaped by multi-cloud environments, microservices, and event-driven APIs, now operate over a transactional surface that is both powerful and fragile. Distributed systems must coordinate hundreds of interdependent operations in real time. When trust fails in this setup, the consequences are normalized when they shouldn’t be.
Distributed systems can either reinforce or erode trust in digital services, especially when working on high-volume business systems at a global scale. Done right, they serve as the invisible infrastructure that enables reliable, verifiable, and secure transactions across industries.
The insights I share here reflect my personal perspective and do not represent the views of any company, employer, or affiliated organization.
Why Trust in Digital Systems is Under Threat
Modern organizations are accelerating toward decentralization. McKinsey notes that distributed architecture is now foundational to digital transformation. Teams ship independently, consume shared data, and plug into automated workflows using APIs. These changes increase development speed, but also multiply coordination points and complexity.
I’ve seen systems that technically “succeed” while producing ambiguous outcomes for the user. One service might finalize a charge while another silently fails to generate the corresponding invoice. We label it “intermittent” and move on. But these inconsistencies compound both for operations and customer confidence.
Uptime Institute’s 2024 report attributes 10% of major outages to flaws in data center design or omissions in infrastructure planning. In distributed contexts, those oversights often involve incomplete retry logic, lack of visibility across asynchronous components, or inconsistent failure-handling pathways.
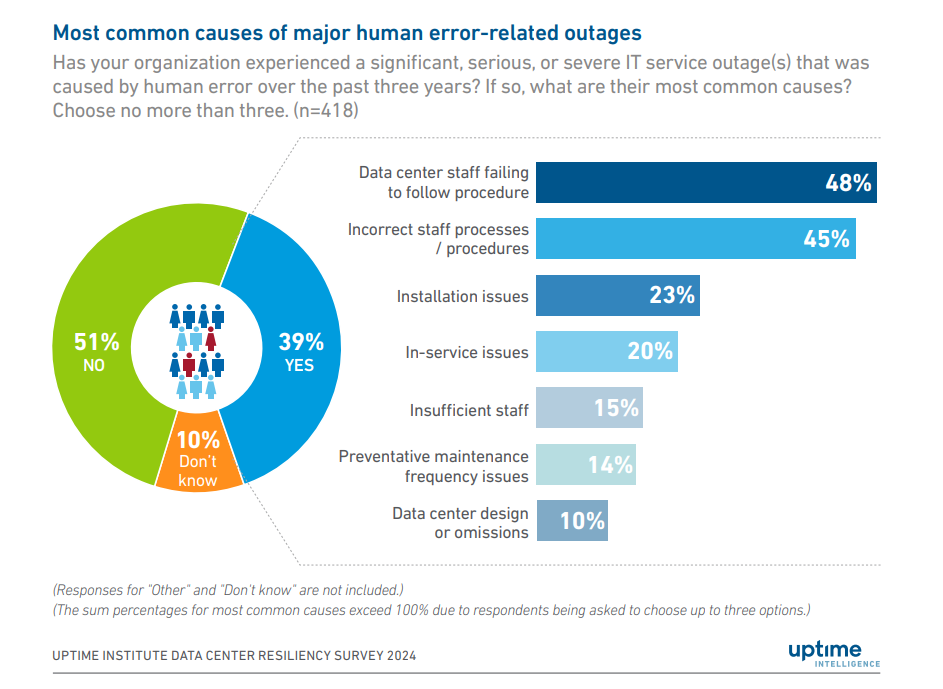
Here are three recurrent trust failures commonly seen in production:
1) Race conditions between loosely coupled services. For example, a billing service triggers a charge before inventory is confirmed. The customer pays for an out-of-stock item, prompting a refund loop that may itself fail due to missing context propagation.
2) Partial failures during distributed writes. Consider a shared payments flow, where one region completes a verification, and another times out. The transaction is stuck in limbo, with no service aware of the full failure.
3) Lack of attribution in asynchronous event chains. Without correlated traces and consistent identifiers, teams can’t diagnose why an invoice failed. Was it a gateway timeout, data mutation, or write conflict? Without clarity, recovery becomes risky guesswork.
Trust rarely collapses suddenly in such environments. It decays gradually through quiet inconsistencies, like when the UI returns a success code, but the actual write fails. What seem to be minor issues translate into higher support costs, increased returns, and loss of customer confidence.
The Role of Distributed Systems in Rebuilding Reliability
Distributed systems, when properly designed, can reestablish operational trust. However, reliability isn’t automatic. It’s engineered through architectural constraints and system-level discipline.
Multi-Region Replication with Control Mechanisms
Data replication improves responsiveness, especially for global users. But multi-region setups introduce coordination issues: replication lag, version conflicts, and timestamp mismatches. Developers must control write sequencing, resolve version differences, and ensure consistency where needed, especially in payment and order flows.
Event-Driven Workflows with Observability
Services often emit events to trigger downstream actions. This decouples logic but makes errors harder to trace. Workflows like business registration and order processing use AWS EventBridge and Step Functions for stateful orchestration.
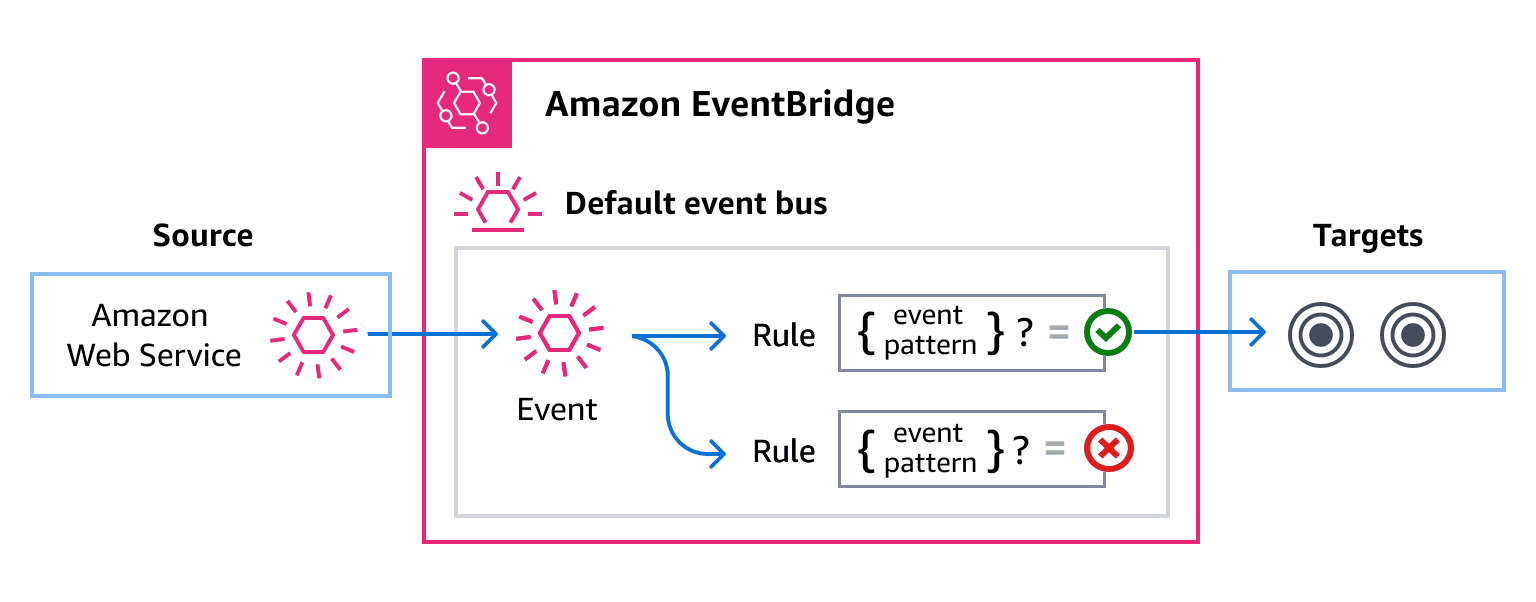
This design enables modular scaling but also makes failure harder to detect. Without structured observability, critical events can disappear midstream.
Consensus Protocols for Shared States
In operations like invoicing or payment confirmation, partial success is not acceptable. The system must reach an agreement before any action finalizes. Consensus protocols such as RAFT or Byzantine Fault Tolerance (BFT) ensure that even under load, crash, or attack, all participants either confirm or reject a transaction together.
Case Study: Building Trust in E-Commerce Transactions
E-commerce is among the most complex distributed environments. A single purchase involves dozens of services: authentication, tax calculation, address verification, payment, fraud detection, and fulfillment. Each microservice carries its own failure domain and operational state.
State machines, such as AWS Step Functions, manage this complexity by enforcing structured execution paths. They allow systems to pause for external responses (e.g., bank authorizations) without losing context, and offer built-in support for retries, timeouts, and failure recovery..
To better illustrate this pattern, the diagram below shows how Step Functions coordinate asynchronous services while managing retries, timeouts, and branching logic.
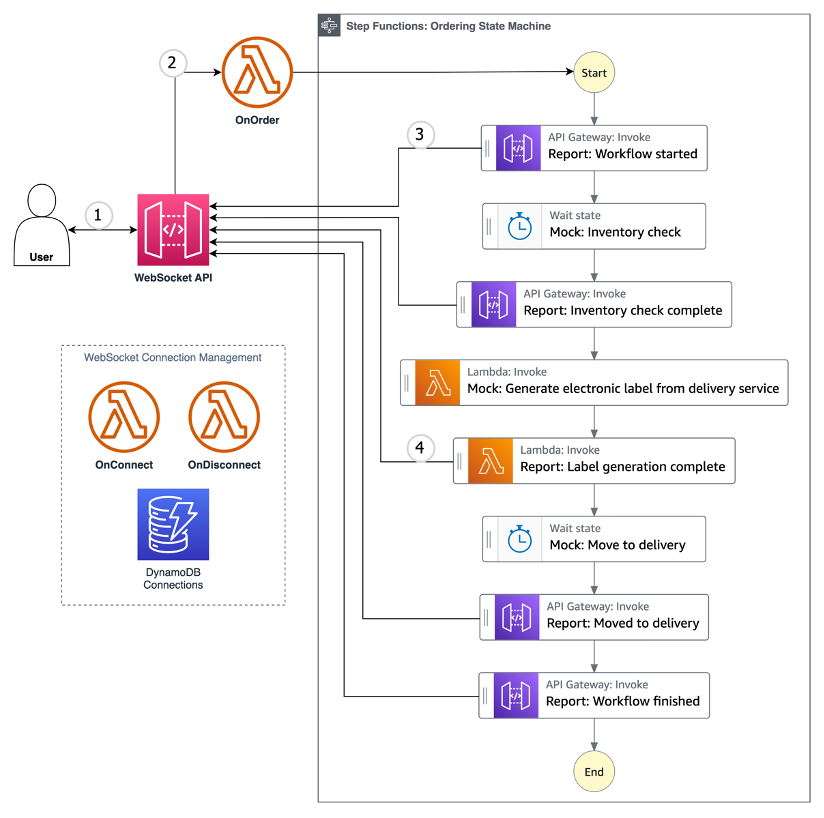
To make these transactions more reliable, the following practices were implemented:
- Instruction Queues: Services log actions before execution, allowing for rollbacks and preserving the correct order.
- Retry Logic with Deduplication: Failed operations can be retried without duplication, using unique request IDs to verify execution status.
- Sequenced Execution: Dependencies are strictly ordered to avoid premature actions that later steps depend on.
These controls helped ensure that pricing logic remained predictable, auditable, and failure-tolerant. When applied together, they help ensure that even under peak demand, systems remain predictable and support recoverability.

Image: Joyseulay | Shutterstock
Designing for Consistency Across High-Stakes Domains
E-commerce isn’t the only domain demanding reliability. Finance, healthcare, and public services also depend on distributed systems where correctness is essential. Hospitals need patient records to reconcile across clinics. Payment processors must log every step for compliance audits. Public agencies cannot afford dropped benefits due to invisible pipeline failures.
These environments require architecture that is accountable at every step. Not only must the system remain operational, but it must be able to explain what it did and why.
“Delivery models have to be reconfigured to embrace distributed services. The world didn’t think it would be trying on clothes in a digital dressing room two years ago.”
– David Groombridge, Gartner Research Vice President
This shift from centralized control to distributed coordination demands infrastructure that supports both continuity and accountability. These design strategies help distributed systems meet that challenge:
1) Selective Replication: Sync only the minimum required fields (status flags, timestamps, and user IDs) across regions to minimize overhead and reduce the scope of failure.
2) Instruction Queues: Log every state change request before applying it. This ensures changes can be replayed or reverted after transient failures.
3) Data Attribution: Every write is tied to a unique service or user ID. This supports audits, debugging, and traceability..
4) Smart Checkpoints: Identify stages in the flow where reconciliation is enforced, limiting divergence without requiring full ACID guarantees.
Applied consistently, these patterns enable distributed systems to explain their state transitions and support transactional review without introducing brittle dependencies.
Conclusion: Operational Trust at Scale
In systems engineering, trust is a reflection of consistency, transparency, and recoverability. It’s earned when a service performs as expected, transactions are fully attributed, and failures are contained without escalation.
What I’ve learned through my work is that reliability in distributed environments is defined by whether a system can surface root causes under pressure. If your platform can’t account for its own behavior, users will assume the worst.
As IoT networks and autonomous agents generate more cross-system transactions, failure points will multiply. The systems that maintain trust will be those designed to track and explain their own behavior before users ask. Architectural decisions, not post-incident responses, define the true reliability of a system.
About the Author:
Sonali Suri is a software developer with experience in designing fault-tolerant, scalable, and distributed systems for high-throughput, real-time platforms. Her work spans customer registration pipelines, messaging integrations, and distributed pricing engines. Sonali is also a published researcher on Byzantine fault-tolerant systems and scalable IoT infrastructure.
References:
What is digital transformation? (2024, August 7). McKinsey & Company. https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-digital-transformation
Annual Outage Analysis 2024. (2024, April 1). Uptime Institute. https://uptimeinstitute.com/resources/research-and-reports/annual-outage-analysis-2024
Automating Step Functions event delivery with EventBridge. (2019, February 26). AWS Documentation. https://docs.aws.amazon.com/step-functions/latest/dg/eventbridge-integration.html
Xie, T., & Liu, X. (2022, November 20). A Raft Algorithm with Byzantine Fault-Tolerant Performance. ICISS ’22: Proceedings of the 5th International Conference on Information Science and Systems. https://doi.org/10.1145/3561877.3561892
Smith, B. (2023, February 15). Implementing reactive progress tracking for AWS Step Functions. Amazon Web Services. https://aws.amazon.com/blogs/compute/implementing-reactive-progress-tracking-for-aws-step-functions/
Wheatley, M. (2021, October 18). Gartner predicts the rise of distributed data architectures, smarter AI, and accelerated automation. SiliconANGLE. https://siliconangle.com/2021/10/18/gartner-predicts-rise-distributed-data-architectures-smarter-ai-accelerated-automationtomation/
Featured Image: one photo | Shutterstock








































