
Nearly every modern product today markets itself as “real-time,” from AI personalization to fraud detection and recommendation engines. Users expect instant responses, and businesses pledge to deliver. Yet few teams manage to turn that promise into a production-grade reality.
I’ve seen it firsthand: teams stitching together batch ETL jobs or leaning on brittle scripts that crumble under pressure. They work for a while, but when data volumes surge or latency requirements tighten, these temporary fixes turn into bottlenecks, triggering silent failures that ripple across analytics and decision-making.
The real issue isn’t the tools; it’s the architecture. Without scalability and resilience built in from the start, you’re just laying bricks on sand. Real-time systems need asynchronous, durable pipelines that can process massive throughput without interruption. That’s where serverless infrastructure and modern data lakes come into play, provided they are implemented correctly.
I’m Sheshank Kodam, a senior platform engineer with over a decade of experience designing and scaling real-time, cloud-native systems. I’ve led the architecture of event-driven pipelines, audience segmentation platforms, and mission-critical systems using AWS and Databricks.
In this article, I’ll break down how to design a production-ready, serverless data pipeline from Lambda-based ingestion and Protobuf serialization to Delta Lake analytics and automated validation. This blueprint enables scalable, resilient, and low-maintenance real-time systems.
Real-Time Ingestion with Lambda and DynamoDB
The first challenge was designing a data ingestion layer that could withstand burst traffic without becoming a maintenance burden. Our solution: AWS Lambda functions triggered via API Gateway, writing directly to DynamoDB for immediate persistence.
Each write to DynamoDB activated a change stream, which allowed us to eliminate traditional queues and streamline downstream processing. By using DynamoDB Streams, we sidestepped the complexity of brokers and batch jobs; the pipeline processed events in a clean, reactive, serverless flow.
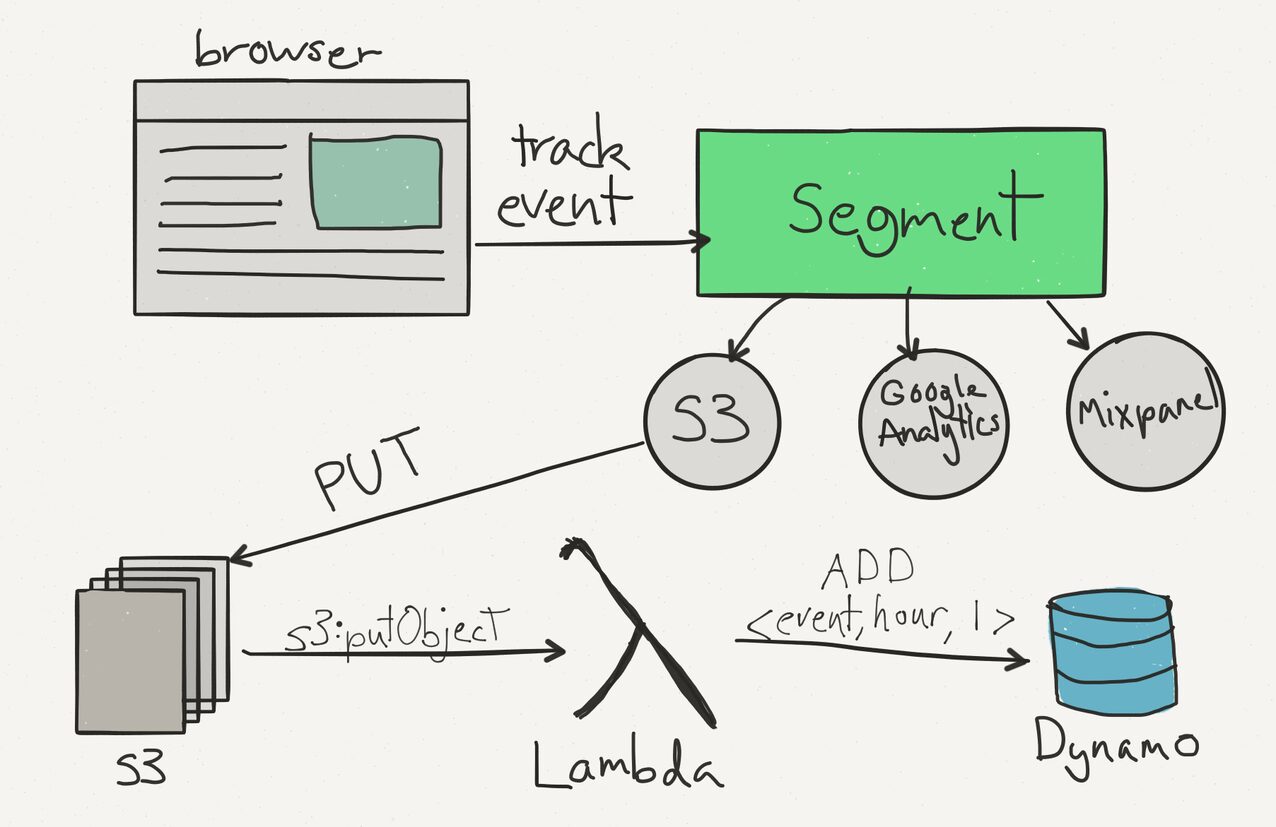
This architecture echoed principles from Segment’s event collection framework: decoupled, scalable, and built for modern cloud ecosystems. It proved critical in production, where millions of user actions, redemptions, purchases, and geolocation updates needed to be processed in real time with high reliability.
A study on ResearchGate confirmed our experience: pairing Lambda with DynamoDB Streams efficiently decouples ingestion from transformation, supporting both high throughput and fault tolerance. We validated these outcomes in production benchmarks.
Protobuf: Compact, Schema-Safe Serialization
Once data is streamed in, it needs to be transmitted with minimal overhead. Initially, we relied on JSON or CSV formats, which are human-readable but prone to errors and resource-intensive. As volumes grew, so did the inefficiencies.
We replaced these with Protocol Buffers (Protobuf). This binary serialization format is significantly smaller and enforces a predefined schema, which improves both consistency and performance.
After capturing changes from DynamoDB, a secondary Lambda function serializes the data using Protobuf and sends it to Amazon S3 or Kinesis, thereby shrinking the payload size and enforcing schema discipline. This binary format significantly reduced overhead compared to JSON, minimized decode errors, and standardized the structure across the pipeline, delivering faster ingestion and improved consistency for downstream analytics.
Ingesting into Databricks and Storing in Delta Lake
The next layer of the pipeline focused on ingesting the Protobuf data into Databricks, where downstream teams could perform aggregations, build models, and trigger decisions in real-time.
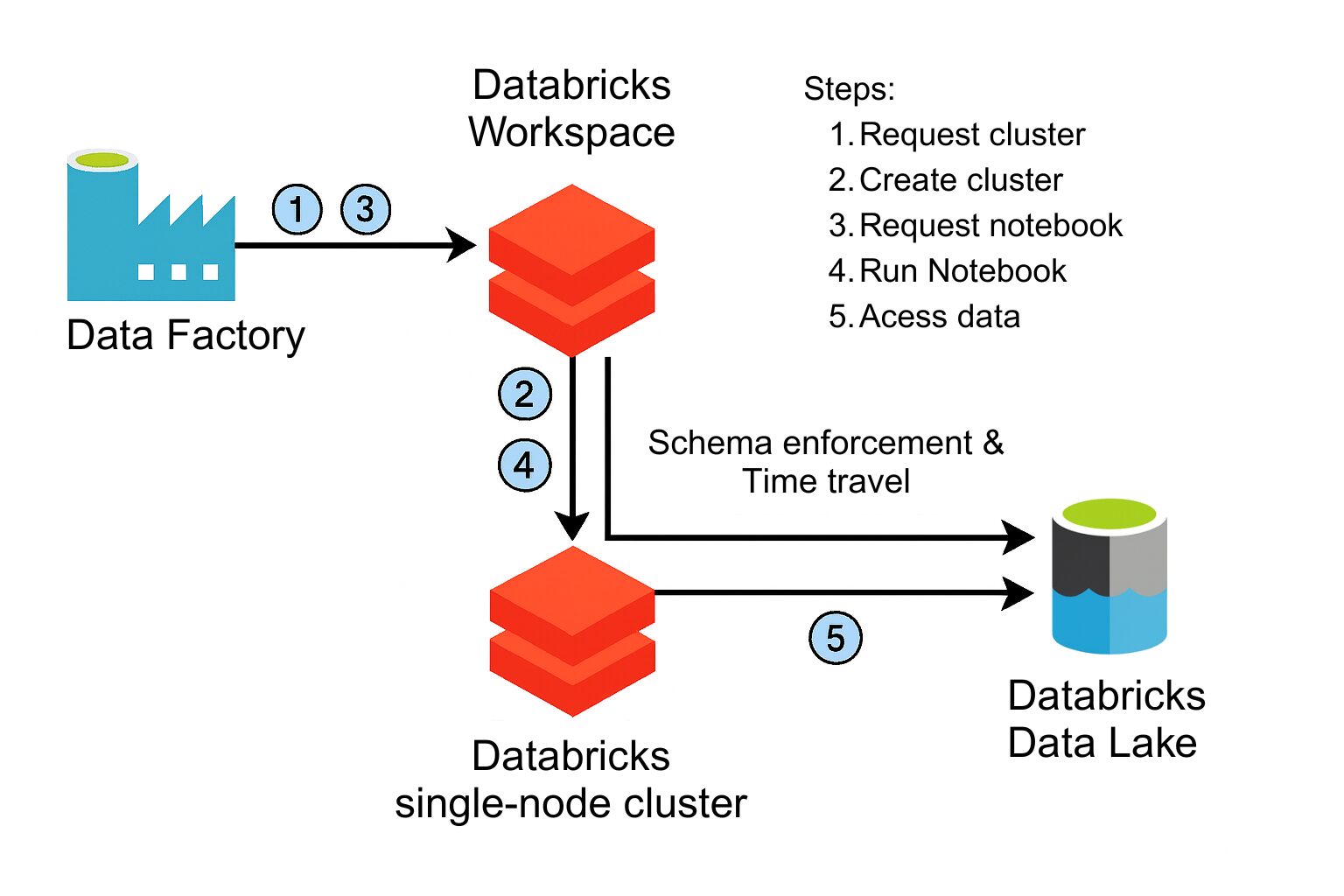
We used Databricks Auto Loader with Structured Streaming to continuously pull data from cloud storage. This system automatically tracked new files and delivered them into Delta Lake, providing a high-throughput yet low-maintenance ingestion path.
Delta Lake offered three foundational capabilities that made it central to our architecture:
- Schema enforcement and ACID compliance, preventing partial writes and schema corruption
- Time travel, allowing us to revert changes from downstream errors
- Schema evolution, enabling field updates without pipeline rewrites
This architecture reduced both the cost and operational burden of managing traditional ETL, while giving me confidence in the integrity of our data. Building on Delta Lake helped us prevent schema drift, simplify backfills, and maintain end-to-end consistency across the pipeline.
As highlighted in a technical paper published in IRJMETS, integrating Delta Lake into cloud-native pipelines enables teams to maintain both flexibility and correctness at scale, something I can attest to from direct experience.
Validating the Pipeline with User Acceptance Testing
Photo: Miha Creative | Shutterstock
Even the most efficient pipeline can fail silently if validation is bolted on late in the process. That’s why we built User Acceptance Testing (UAT) into the ingestion lifecycle from day one. In environments where correctness and auditability are critical, such as the real-time data platforms I’ve helped build, ensuring trust in every dataset is non-negotiable.
We embedded automated UAT checks directly within Databricks workflows, verifying record counts, schemas, and business logic like timestamp integrity and value ranges.
By placing these gates early in the pipeline, we can detect problems such as late-arriving events or malformed payloads before they reach downstream systems.
As emphasized in a Functionize article, incorporating UAT into data workflows helps teams avoid silent data corruption, especially when dealing with diverse sources and evolving schemas. From my experience, UAT not only safeguards data quality, but it also builds cross-team trust by preventing downstream surprises.
Orchestration with AWS Step Functions
Once the ingestion, transformation, and validation layers were established, the next challenge was to coordinate them reliably. Connecting Lambdas, S3, and Databricks jobs manually quickly became a maintenance headache, making failures hard to trace and workflows brittle.
Our answer: AWS Step Functions. Each stage, from ingestion and Protobuf serialization to validation and alerting, was modeled as a state machine. This gives us:
- Visual flowcharts for debugging and audits
- Built-in retries and backoff policies
- Metrics and alerts for pipeline health
Step Functions gave us a modular, self-healing pipeline with built-in observability, turning opaque glue code into a visual, traceable system. Unlike hand-stitched workflows prone to silent failures, Step Functions enabled declarative coordination with retries, metrics, and auditing built in.
An excellent technical breakdown of this approach can be found in a Medium article by Platform Engineers, which walks through chaining Lambda functions via Step Functions with retry logic and fail-safe mechanisms.
If you’re building pipelines that must ingest real-time data, evolve quickly, and scale cost-effectively, combining a serverless architecture with Delta Lake is a strategy worth serious consideration. It has helped my teams eliminate infrastructure overhead while enabling flexible, continuous processing and validation at scale.
After years of building real-time data systems in production, here are the principles that consistently deliver long-term value:
- Design around event-driven triggers to build in scalability and resilience from day one.
- Use efficient serialization formats like Protobuf to improve performance and enforce schema discipline.
- Embed user acceptance testing early to safeguard data quality and prevent silent failures.
- Orchestrate with tools like Step Functions to replace glue code with visibility, retries, and auditability.
In the end, this architecture let our teams stop firefighting and start delivering insights that are fast, reliable, and ready for scale. Real-time systems don’t succeed by adding more complexity. They succeed when integration replaces improvisation and resilience is designed in from the start.
If you want systems that move as fast as your users and don’t melt under pressure, this blueprint is battle-tested and built to last.
About the Author
Sheshank Kodam is a senior platform engineer who has led the design of secure, real-time data systems used in large-scale, customer-facing applications. With over a decade of experience, his expertise spans cloud-native infrastructure, serverless event processing, and big-data pipelines engineered to scale under high concurrency and evolving business needs.
References:
- Functionize. (September 23, 2024). Acceptance testing: A step-by-step guide. https://www.functionize.com/automated-testing/acceptance-testing-a-step-by-step-guide
- Platform Engineers. (May 9, 2024). Serverless data pipelines with AWS Step Functions and AWS Lambda. Medium. [Blog]. https://medium.com/@platform.engineers/serverless-data-pipelines-with-aws-step-functions-and-aws-lambda-6571b59b48a2
- Remala, R., Mudunuru, K. R., & Nagarajan, S. K. S. (June 29, 2024). Optimizing data ingestion processes using a serverless framework on Amazon Web Services. International Journal of Advanced Trends in Computer Science and Engineering. https://www.researchgate.net/publication/382077726_Optimizing_Data_Ingestion_Processes_using_a_Serverless_Framework_on_Amazon_Web_Services
- Segment. (November 30, 2021). The anatomy of a modern data pipeline. https://segment.com/blog/data-pipeline/
- Shaik, A., Jena, R., Vadlamani, S., Kumar, L., Goel, P. D., & Singh, S. P. (December 12, 2021). Data lake using Delta Lake – a real-time data management approach. International Research Journal of Modernization in Engineering Technology and Science, 3(12): n.p. https://www.irjmets.com/uploadedfiles/paper/volume_3/issue_12_december_2021/17965/final/fin_irjmets1732617799.pdf


































