Quarantine increased time spent on social media websites. People are increasingly consuming more content and social media platforms are with relevant content and Ad recommendations. Have you ever wondered how these intricate systems work? In today’s tech series, we talked with Karun Singla, who has built the recommendation engine for one of the largest Ecommerce clients of vernacular content platform Dailyhunt. You can guess the client when we say, they come with a catalog size of over 2.5 billion products.
Problem Overview
Fig Shows Overview of Dailyhunt’s two model system for Ecommerce recommendations
Our models need to pick up relevant products from a catalog or corpus of over 2 billion products. For every product sold through our recommendation, Dailyhunt charges a commission. Today we will talk about how to build a highly accurate recommendation system that drove million dollars in quarterly commissions.
Recommendation Systems are the backbone
Recommender systems have been around for over 4 decades. The first recommender system was built in 1979 called Grundy. It was a computer-based librarian that provided suggestions to the user on what books to read.
Traditionally used models for recommendations are based on Matrix Factorisation, We will not cover them in detail here. While the model is simple to use :
- The difficulty of using side features (that is, any features beyond the query ID/item ID). As a result, the model can only be queried with a user or item present in the training set.
- Relevance of recommendations – popular items tend to be recommended for everyone, especially when using dot products as a similarity measure. It is better to capture specific user interests.
At dailyhunt, AI Labs We build Deep neural network (DNN) models that can address these limitations of traditional recommendation systems. DNNs can easily incorporate query features and item features (due to the flexibility of the input layer of the network), which can help capture the specific interests of a user and improve the relevance of recommendations. The whole model can be broken down into 2 sub models
- Candidate Generation
- Candidate Reranker
Candidate Generation Model Architecture
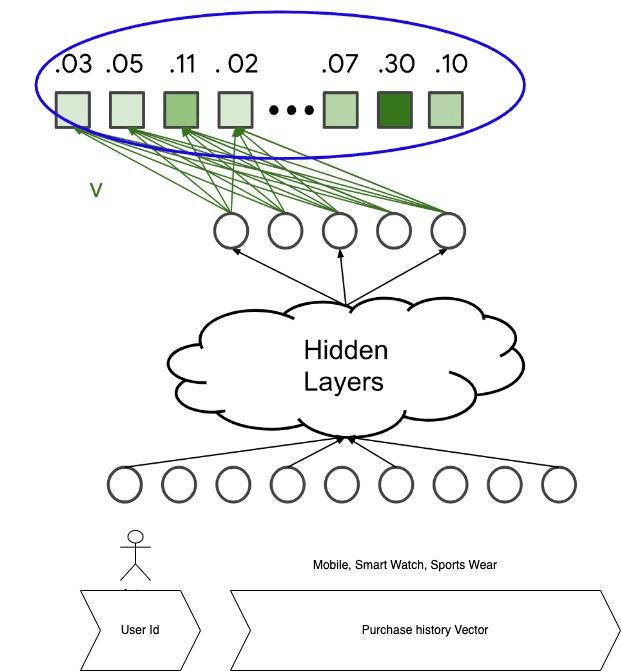
Figure shows Modified Neural Collaborative Filtering, the output layer is a softmax distribution of probabilities of purchase of size=length of corpus
The first model is a modification to Neural Collaborative Filtering: https://arxiv.org/abs/1708.05031 published by researchers at National University of Singapore, Columbia University, Shandong University, and Texas A&M University, with following changes proposed:
- The input is the user query. We add static features along with user embedding such as country, age, IOS vs Android as sparse features
- We add a history vector of past purchases (mean(pi) for i in past purchases)
- For this we use RESNET64 as base model to find embeddings of Images of products purchased by the user and average them.
- The output is a probability vector with size equal to the number of products in the corpus, representing the probability to interact with each item; for example, the probability to purchase an item.
But WAIT .. What about Complexity of the Algorithm? Ever Heard about Folding?
What if the product catalog is million, the complexity of softmax is quadratic in nature, therefore as the catalog size increases. In the figure, assuming that each color represents a different category of queries and items. Each query (represented as a square) only mostly interacts with the items (represented as a circle) of the same color. For example, consider each category to be an Ecommerce category on Amazon say HomeDecor, Electronics etc.. A typical user will mostly interact with products of one category..
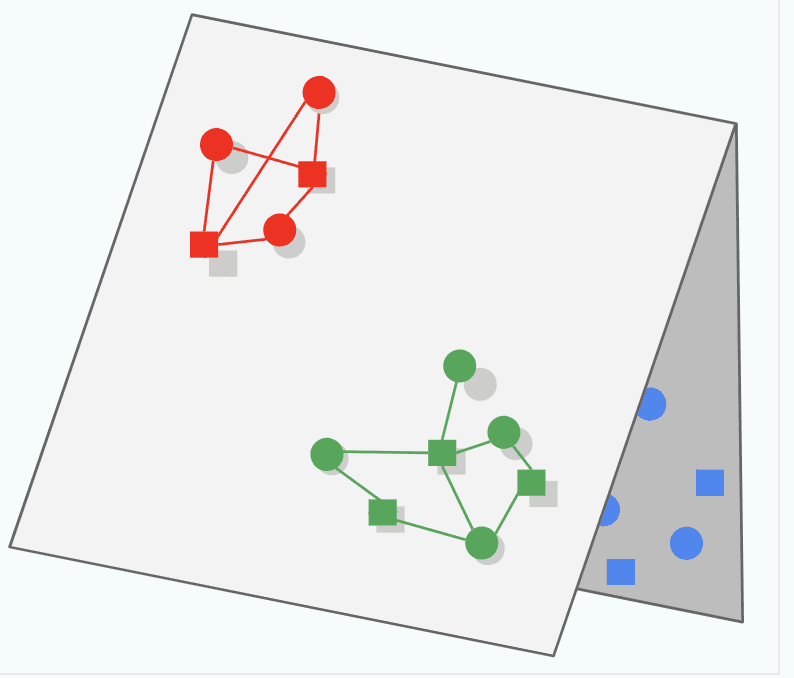
Different colors indicate different Ecommerce Categories
The model may learn how to place the query/item embeddings of a given color relative to each other (correctly capturing similarity within that color), but embeddings from different colors may end up in the same region of the embedding space, by chance. This phenomenon, known as folding, can lead to spurious recommendations: at query time, the model may incorrectly predict a high score for an item from a different group.
How to solve this?
Negative examples are items labeled “irrelevant” to a given query. Showing the model negative examples during training teaches the model that embeddings of different groups should be pushed away from each other. So to summarize, in your training of softmax layer use
- All positive items (the ones that appear in the target label)
- A sample of negative items to compute the gradient for backpropagation
Candidate Reranker model
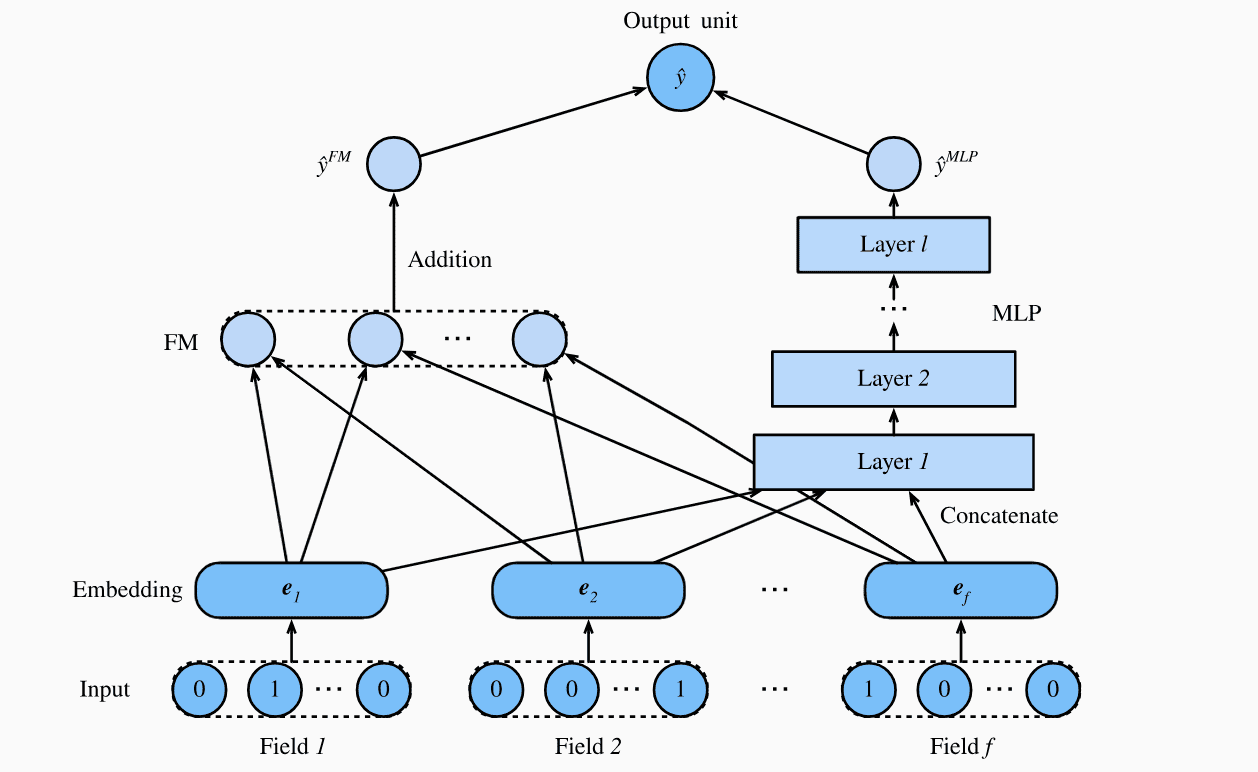
Architecture for Deep Factorization Machine, FM part computes sparse interactions
Since this model will be sorting recommendations from the candidate generation stage, we can make it complex and add sparse feature interactions.
Often we would want to fine-tune our recommendations based on context features that can be broadly categorized into
- Product features – Price of the product, category of the product – say electronics, fashion, lifestyle, home-decor
- User Features – user current location, language, Age
- We can add context features such as time of the day, month, year to capture context, but for simplicity, We will skip this set of features.
Results
We conducted 3 experiments using three models(green, red and blue), and training at multiple depths in the Candidate models (4,8,12). There are multiple metrics that can be used to evaluate recommender systems – HR (hit ratio), MRR (Mean Reciprocal Rank), MAP (Mean Average Precision), NDCG (Normalized Discounted Cumulative Gain). For this experiment we will stick to MAP.
The combined Candidate Generation + Reranker outperformed at 0.13 MAP

About the Author

Karun Singla is one of the emerging top tier data scientists in India. He holds a B.Tech degree from prestigious Delhi Technological University. With 6 years of experience in Big Data and AI. he is currently working as Senior Machine Learning Engineer at Dailyhunt to solve ad recommendations problems using distributed computing