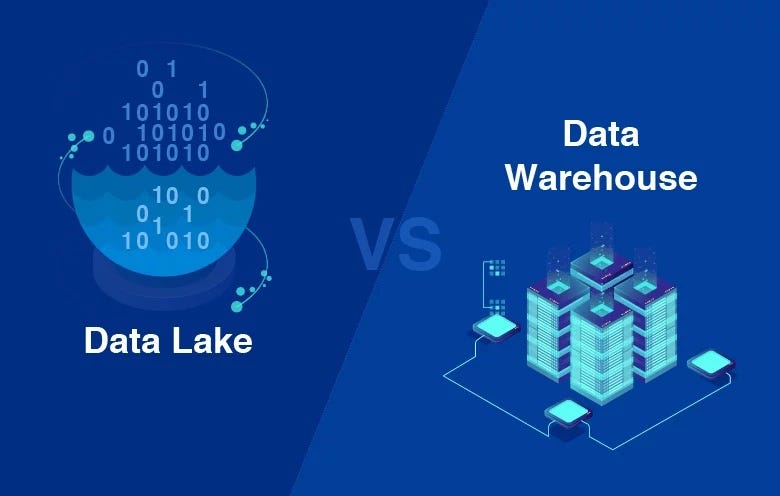
In today’s data-driven world, where information is the currency of success, organizations face critical decisions about how to manage and harness their data effectively. Two prominent solutions have emerged as pillars of modern data management: Data Warehouses and Data Lakes. In this comprehensive guide, we will embark on a journey to explore, compare, and contrast these data storage paradigms. We’ll delve into their definitions, architectures, use cases, and benefits, supported by real-world examples and expert insights. By the end of this journey, you will be equipped with the knowledge to navigate the complex data landscape and make informed decisions for your organization.
Introduction Setting the Stage
How has the growing importance of data impacted modern businesses?
In the age of digital transformation, data has become a strategic asset, driving decisions, innovation, and competitive advantage. Organizations that harness data effectively gain insights, enhance customer experiences, and optimize operations.
What role do data storage solutions play in harnessing the power of data?
Data storage solutions are the foundation of a data-driven strategy. They determine how efficiently an organization can store, access, and analyze its data. The choice between Data Warehouses and Data Lakes significantly influences an organization’s data capabilities.

Section 1: Understanding Data Warehouses Definition and Purpose
Can you provide a clear definition of what a Data Warehouse is?
A Data Warehouse is a centralized repository that stores structured data from various sources. It is optimized for query and analysis, enabling organizations to perform complex reporting and gain insights into historical data.
What are the primary functions and objectives of a Data Warehouse?
The primary functions of a Data Warehouse include data consolidation, transformation, and storage. Its objectives are to provide a single source of truth for reporting, support business intelligence, and facilitate data-driven decision-making.
Architecture and Structure
What are the key components that make up a Data Warehouse architecture?
A typical Data Warehouse architecture comprises data sources, ETL (Extract, Transform, Load) processes, data storage, and query tools. These components work together to ensure data is ingested, transformed, and made accessible for analysis.
How does schema design influence the effectiveness of a Data Warehouse?
Schema design defines how data is organized within the Data Warehouse. It impacts query performance, data accessibility, and adaptability to changing business needs. A well-designed schema is essential for efficiency.
Use Cases and Benefits
How do Data Warehouses serve businesses in terms of data analytics and decision-making?
Data Warehouses empower organizations with quick access to high-quality, structured data. They facilitate ad-hoc querying, historical analysis, and reporting, enabling data-driven decision-making.
Could you share some real-world examples of successful Data Warehouse implementations?
Certainly. Let’s explore two case studies that highlight the advantages of Data Warehouses in different industries:
Case Study 1: Retail Analytics
A leading retail chain implemented a Data Warehouse solution to consolidate data from its various stores, online sales, and supply chain. By analyzing sales trends, inventory levels, and customer behavior, they optimized stock management, reduced overstocking, and improved customer recommendations. This resulted in a 15% increase in revenue and a 20% reduction in operational costs.
Case Study 2: Financial Reporting
A global financial institution adopted a Data Warehouse to meet regulatory reporting requirements. By centralizing financial data, they could generate accurate and timely reports for compliance purposes. This not only ensured regulatory adherence but also enhanced the institution’s reputation for transparency and reliability.
Section 2: Unpacking Data Lakes Definition and Purpose
What exactly is a Data Lake, and how does it differ from a Data Warehouse?
A Data Lake is a repository that can store structured, semi-structured, and unstructured data in its raw, unprocessed form. Unlike Data Warehouses, Data Lakes do not enforce a specific structure on data, allowing for greater flexibility.
Can you explain the fundamental concept behind Data Lakes?
The fundamental concept of Data Lakes is to store data without predefined structure or schema. Data is ingested as-is and is structured upon retrieval, enabling organizations to explore and analyze data without constraints.
Architecture and Structure
What are the core components that constitute a Data Lake’s architecture?
A Data Lake architecture includes storage layers (like Hadoop Distributed File System or cloud-based storage), data processing engines (such as Apache Spark), and metadata management. These components enable data storage, processing, and discovery.
How does the concept of Schema-on-Read differ from Schema-on-Write in Data Lakes?
Data Lakes employ a Schema-on-Read approach, where data remains in its raw format until accessed. Schema-on-Read allows organizations to apply structure and meaning to data only when needed for analysis, providing flexibility.
Use Cases and Benefits
In what scenarios do Data Lakes excel, and how do they benefit organizations?
Data Lakes excel in scenarios where organizations need to ingest, store, and analyze vast volumes of diverse data types, including unstructured and semi-structured data. They offer agility, cost-effectiveness, and scalability.
Could you provide some case studies that illustrate the advantages of Data Lakes?
Certainly. Let’s explore two case studies that showcase the advantages of Data Lakes in different contexts:

Case Study 1: Healthcare Research
A healthcare research organization implemented a Data Lake to store a wide range of medical data, including electronic health records, research papers, and imaging data. By applying machine learning algorithms to this vast dataset, they discovered previously unnoticed patterns and potential treatments. This led to breakthroughs in disease research and more personalized patient care.
Case Study 2: Social Media Analytics
A social media analytics company leveraged a Data Lake to collect and analyze social media data from multiple platforms. With the ability to ingest data in real-time and process it at scale, they provided valuable insights to businesses seeking to understand consumer sentiment, trends, and brand perception. This resulted in improved marketing strategies and customer engagement for their clients.
Section 3: Key Differences Data Model and Schema
What are the key distinctions between structured and semi-structured data in Data Warehouses and Data Lakes?
Data Warehouses excel at handling structured data with well-defined schemas, making them suitable for traditional reporting and analytics. In contrast, Data Lakes accommodate both structured and semi-structured data, allowing organizations to work with diverse data types.
How does the flexibility of schema design in Data Lakes compare to the rigidity of Data Warehouses?
Data Lakes offer schema flexibility, allowing data to be ingested without predefined structures. This flexibility makes them well-suited for organizations dealing with evolving or unstructured data. Data Warehouses, on the other hand, require data to be structured before storage, which can limit adaptability.
Data Processing
What are the differences in data processing approaches between Data Warehouses (batch) and Data Lakes (real-time)?
Data Warehouses typically use batch processing, where data is collected and processed periodically. This approach is well-suited for structured data analysis. In contrast, Data Lakes embrace real-time processing, allowing organizations to analyze data as it arrives, making them suitable for streaming and near-real-time use cases.
Could you explain the contrast between ETL and ELT processes in the context of Data Warehouses and Data Lakes?
ETL (Extract, Transform, Load) processes transform data before loading it into Data Warehouses, ensuring that it conforms to the warehouse’s schema. In contrast, ELT (Extract, Load, Transform) processes load raw data into Data Lakes and perform transformations during analysis. ELT in Data Lakes offers greater flexibility and agility.
Data Storage and Costs
Scalability Considerations:
Both Data Warehouses and Data Lakes, when hosted on cloud platforms like AWS, Azure, or Google Cloud, offer horizontal scalability. Organizations can easily add more computing nodes or storage resources to handle increased workloads. This scalability helps in accommodating growing data volumes and processing demands.
Cost Factors
Cloud-based Data Warehouses and Data Lakes follow a pay-as-you-go pricing model. Scaling horizontally in the cloud typically incurs additional costs as more resources are provisioned. Organizations should closely monitor their cloud resource usage to optimize costs and ensure cost-effectiveness.
Section 4: When to Choose What Decision Factors
What are the primary decision factors that businesses should consider when choosing between Data Warehouses and Data Lakes?
Businesses should consider factors like data structure, analysis requirements, data volume, and the need for real-time processing. Structured, well-defined data may favor Data Warehouses, while diverse, unstructured data may lean toward Data Lakes.
How do business goals and the types of data being handled impact this decision?
Business goals dictate the importance of factors like agility, cost-effectiveness, and scalability. For example, a goal to analyze real-time customer interactions may favor a Data Lake’s flexibility.
Scenarios and Recommendations
Can you provide guidance on when it’s most suitable to choose Data Warehouses?
Data Warehouses are suitable for scenarios where organizations primarily work with structured data and require traditional reporting, historical analysis, and a single source of truth. Consider Data Warehouses for structured, business-critical data.
When should organizations opt for Data Lakes, and what are the advantages in those situations?
Data Lakes are ideal when organizations deal with diverse data types, require agility in data exploration, need to ingest data at scale, and seek cost-effective storage options. They excel in scenarios where the data structure is not predefined and may evolve.
Hybrid Approaches
How can organizations leverage hybrid approaches to combine the strengths of both Data Warehouses and Data Lakes effectively?
Hybrid approaches, often referred to as “Lakehouses,” aim to combine the strengths of Data Warehouses and Data Lakes. By using Data Lakes for raw data storage and Data Warehouses for structured reporting, organizations can achieve flexibility and performance.

Section 5: Challenges and Best Practices Data Governance
What strategies and best practices should be in place to ensure data quality and security in Data Warehouses and Data Lakes?
Robust data governance frameworks, including data cataloging, access control, and encryption, are essential to maintain data quality and security across both storage solutions.
How can organizations navigate regulatory compliance challenges in their data storage solutions?
Meeting regulatory compliance requires thorough data lineage tracking, auditing, and adherence to data privacy regulations. Organizations must stay informed and adapt to evolving compliance standards.
Data Exploration and Analytics
What tools and techniques can organizations employ to enable efficient data exploration and analytics within Data Warehouses and Data Lakes?
Utilize advanced analytics platforms, visualization tools, and data science techniques to extract valuable insights. Data lakes benefit from technologies like Apache Spark and Presto for analysis.
How do these solutions empower data scientists in their work?
Data Warehouses and Data Lakes provide data scientists with rich, well-structured data for analysis. They can apply machine learning and AI algorithms to derive predictive insights and drive innovation.
Scalability and Performance
What best practices should be adopted to maintain efficiency and handle growing data volumes in Data Warehouses and Data Lakes?
Scaling storage and processing resources as needed, optimizing queries, and implementing data compression techniques are essential practices to ensure efficiency.
What are the key considerations for ensuring scalability and high performance in these environments?
Consider factors like workload management, data partitioning, and query optimization to ensure scalability and high performance in both Data Warehouses and Data Lakes.
Section 6: Future Trends Evolving Technologies
How are machine learning and AI being integrated into Data Warehouses and Data Lakes, and what benefits do they offer?
Machine learning and AI enhance data analysis, predictive modeling, and anomaly detection within both Data Warehouses and Data Lakes. These technologies unlock deeper insights and automation opportunities.
What is the role of serverless computing in shaping the future of data storage solutions?
Serverless computing promises agility, cost-effectiveness, and simplified infrastructure management. It is poised to play a significant role in optimizing data storage solutions, reducing operational overhead.
The Convergence
How do you see the line between Data Lakes and Data Warehouses blurring in the near future?
The convergence of Data Lakes and Data Warehouses, often referred to as “Lakehouses,” is becoming more prevalent. Organizations seek solutions that combine the benefits of both paradigms while simplifying data management.
Data-Driven Future
In what ways will data storage solutions contribute to the data-driven future of enterprises, and what can businesses expect?
Data storage solutions will be central to the data-driven future. Businesses can expect streamlined data management, enhanced analytics capabilities, and the ability to turn data into a strategic asset.
Conclusion Summarizing the Journey
What are the key takeaways from the exploration of Data Warehouses and Data Lakes?
Key takeaways include recognizing the strengths and weaknesses of each storage solution, understanding their suitability for different scenarios, and aligning choices with strategic objectives.
The Right Choice
How can businesses effectively match their data storage solutions to their specific needs?
To make the right choice, businesses must assess their data types, analysis requirements, compliance obligations, and scalability needs. Tailoring the solution to their unique context is key.
Embracing the Data Revolution
What steps should organizations take to prepare themselves for the data-driven future and the evolving landscape of data storage?
Organizations should invest in data governance, foster a data-centric culture, stay updated on emerging technologies, and adopt flexible solutions to adapt to the evolving data landscape. The data-driven future awaits, and preparation is paramount.
As we conclude our journey through the realm of Data Warehouses and Data Lakes, you are now equipped with a comprehensive understanding of these data storage paradigms. The dynamic world of data demands informed decisions, and your newfound knowledge, enriched by Pivot-al insights, will guide you in harnessing the power of data effectively.