Cloud costs are rising fast, and many companies don’t realize where the waste is hiding. In this article, AWS Systems Development Engineer Sreekar Jami explains the real reasons cloud budgets spiral out of control and shares practical strategies engineers can use to manage costs without sacrificing performance. Based on real-world experience, this guide shows how smart architecture, automation, and cross-team collaboration can make cloud systems more efficient and sustainable.

Source: Shutterstock
More than two-thirds of enterprises blew their cloud budgets last year.
Not because they lacked funding, but because they lacked visibility. In a cloud-first world, overspending isn’t a technical glitch. It’s a design flaw.
As a Systems Development Engineer at Amazon Web Services, I’ve seen this pattern repeat across organizations of every size. Teams build for scale and performance. Without guardrails, that same flexibility becomes the reason costs spiral out of control.
In this post, I’ll walk you through the common engineering habits that inflate cloud costs without warning. You’ll see real-world examples of where budgets slip, why it happens, and the practical, battle-tested strategies that have helped teams I work with cut spend by up to 40% while improving system reliability, not trading it away.
If you want your cloud to scale smartly, not just quickly, it starts here.
The Core Challenge: Performance Overhead Meets Budget Pressure
Cloud services are easy to consume and even easier to overspend on. We are trained to prioritize scalability and resilience, often without thinking about cost.
This leads to common patterns like:
- Choosing oversized instances “just in case”
- Leaving test environments running overnight
- Storing all data in premium storage without lifecycle policies
These habits seem harmless individually. But across dozens or hundreds of workloads, they quietly accumulate into major financial waste.
According to the Flexera 2024 State of the Cloud Report, 84% of organizations now list managing cloud costs as their primary concern. Meanwhile, Gartner reports that 69% of enterprises overspent their cloud budgets in 2023, largely due to a lack of optimization frameworks.
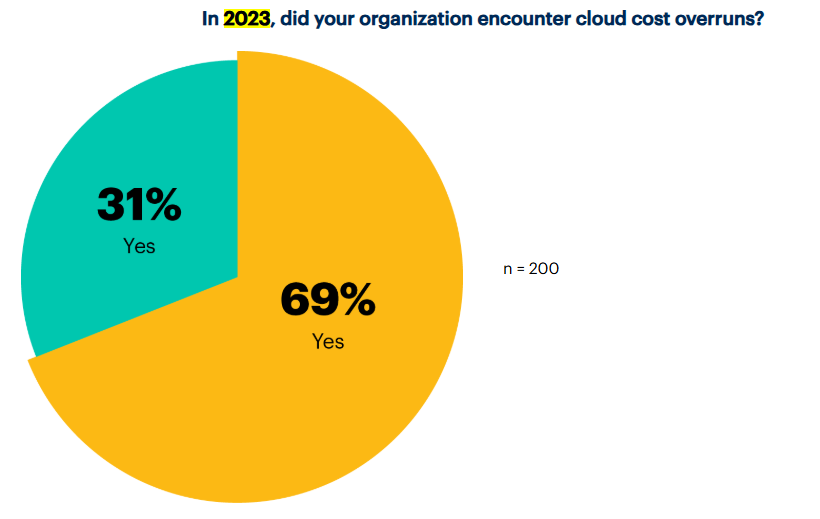
Source: Gartner
The issue isn’t the cloud itself. It’s unchecked consumption.
Where Cloud Waste Typically Hides
It’s rarely one big mistake that drives up your cloud bill. More often, it’s a series of overlooked decisions—resource sizing, environment sprawl, forgotten storage—that quietly accumulate into serious waste. Let’s break down where that tends to happen first.
1. Oversized Compute Resources
One of the first places I look during a cost audit is instance sizing.
In one project, I found a development environment running r5.xlarge instances with workloads consistently under 10% CPU utilization. Switching them to t3.medium instances achieved the same outcomes—with a 70% reduction in compute costs.
Oversized instances often hide behind “better safe than sorry” reasoning. But in a dynamic cloud environment, resource flexibility can replace static overprovisioning if you engineer for it.
2. Always-On Environments
Development, QA, and testing systems frequently run 24/7, even when teams only use them 40 hours a week.
At American Airlines, we automated non-production shutdown schedules using a custom script to autoscale the cluster in IBM Cloud. Shutting down unused environments outside office hours consistently cut non-prod infrastructure costs by 65%.
This strategy doesn’t just save money. It reinforces discipline around resource usage across engineering teams.
3. Storage and Data Transfer Inefficiencies
Storing cold or infrequently accessed data on expensive general-purpose SSD volumes is surprisingly common.
Without automated storage lifecycle policies, companies end up paying premium prices for data that hasn’t been accessed in months.
Transferring large amounts of data across regions or accounts also inflates bills. In AWS, data transfer between regions can cost up to $0.02 per GB, depending on the services involved.
At one client site, moving archival data to S3 Glacier Deep Archive and redesigning traffic patterns for regional stickiness cut storage and transfer costs by more than 80%.
Solutions Engineers Can Implement Right Now
Spotting the problems is only half the job. The real value comes from knowing exactly what to do next. These are the practical, engineering-driven solutions I’ve used to reduce cloud spend without compromising performance or reliability.
Use Automation to Scale with Demand
Manual provisioning inevitably leads to overprovisioning. Instead, systems should adjust dynamically based on real usage.
Here’s a basic example for dynamic auto-scaling:
def auto_scale_resources(metrics):
current_load = metrics.get_cpu_utilization()
if current_load < 30:
downscale_instance()
elif current_load > 70:
upscale_instance()
AWS Auto Scaling Groups, Kubernetes Horizontal Pod Autoscaler (HPA), and Terraform scaling modules enable scaling based on CPU, memory, or custom application metrics.
When automation governs scaling decisions, costs naturally track demand instead of arbitrary provisioning.
Architect for Efficiency
Good architecture eliminates unnecessary consumption at its root. Here are specific design principles:
- Tier storage intelligently. Move cold data to cheaper storage tiers automatically.
- Use caching layers like Redis or Memcached to offload repetitive queries.
- Minimize cross-region traffic with smart CDN use and zone-aware services.
- Adopt Spot Instances wherever possible. For batch, analytics, and training workloads, spot usage can lower compute spend by up to 90% compared to On-Demand pricing.
The Well-Architected Framework Cost Optimization Pillar emphasizes these same ideas. Building cost awareness into architecture, not just operational practices, is the real unlock for sustained savings.
Building a Monitoring Framework That Surfaces Problems Early
Optimization shouldn’t be a one-time effort. You need ongoing visibility into how systems are behaving and consuming resources.
Here’s how to design a monitoring framework that actually helps:
1. Real-Time Metrics
Track basic but critical indicators:
- CPU utilization
- Memory utilization
- Disk I/O and throughput
- Network bandwidth usage
Set clear thresholds to detect underutilization before it leads to waste. If a server maintains less than 20% CPU for a week, it’s a signal to downsize.
2. Resource Tagging for Ownership
Enforce a strict tagging policy at the deployment stage:
- Owner: who is responsible for the resource
- Environment: dev, staging, production
- Cost Center: for financial tracking
- Expiration Date: particularly for temporary or ephemeral environments
Resource tagging is the foundation for automated reporting, chargeback models, and financial accountability.
3. Automated Policies and Guardrails
Combine real-time insights with automated enforcement.
For example:
- Auto-shut down unused non-prod instances nightly.
- Cleanup unattached volumes every week.
- Alert when workloads consistently underutilize allocated resources.
By embedding cost hygiene into CI/CD and monitoring systems, you make optimization a permanent part of operational practice.
Practical Playbook for Engineering Teams

Source: Shutterstock
The most effective cloud cost management isn’t just about saving money. It’s about sustainable engineering practices.
Here’s the playbook:
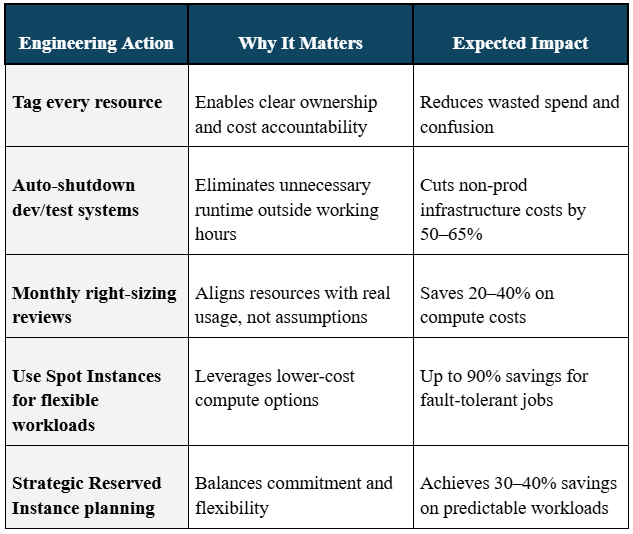
- Tag every deployed resource.
- Set up automatic shutdowns for lower environments outside working hours.
- Conduct monthly right-sizing reviews based on CloudWatch or third-party monitoring data.
- Use Reserved Instances cautiously. Prefer 1-year reservations unless workloads are truly static.
- Deploy spot instances for interruptible tasks like analytics, training, and rendering jobs.
- Educate every engineering team on the real cloud costs of their systems.
When cost optimization is part of the engineering culture, it no longer feels like a burden. It feels like the way things should be built.
Quick Reference: Cloud Cost Optimization Actions
Collaboration: The Missing Piece in Many Organizations
One of the most important lessons I learned from experience is that cost efficiency is a cross-functional effort.
It’s not enough for finance to care. Engineers, product owners, and infrastructure teams all need to own their slice of the budget.
As J.R. Storment, Executive Director of the FinOps Foundation, said in an interview with ITPro Today:
“The big thing in the space that we found is that it’s not about spending less; it’s about spending the right amount.”
That insight reflects what we experienced firsthand. We instituted regular cloud cost reviews as part of our sprint cycles. These weren’t top-down audits. They were working sessions.
These reviews included:
- Reviewing service utilization vs. costs
- Identifying optimization opportunities
- Celebrating teams that made meaningful improvements
This approach aligns with the FinOps Foundation model: making cloud spend a shared operational concern rather than a billing afterthought.
According to a 2023 Deloitte report, organizations implementing FinOps practices achieved cloud savings of 20–30% within their first year.
That level of impact doesn’t come from magic dashboards or secret discounts. It comes from collaboration, consistency, and shared ownership.
Real-World Success Stories
Regional Optimization for a Global Retail Client
A previous client had redundant services spread across multiple cloud regions, leading to unnecessary costs and complexity.
Analysis showed that over 90% of user traffic originated from just two regions.
By consolidating compute workloads, reducing cross-region replication, and deploying smarter CDN strategies, we reduced their cloud costs from $180,000 to $120,000 per month without degrading performance or reliability.
The final system had better observability, faster failover, and leaner operational overhead.
Tuning a GenAI Application for Affordability
Another project involved a GenAI application generating customer account summaries.
The initial deployment used larger models that required GPU-backed instances for inference, which drove costs up significantly.
We improved the design by:
- Moving simple requests to lightweight LLM models for inference.
- Implementing aggressive edge caching for common outputs
- Using microservices like Lambda to scale batch processing up and down with demand.
The result was a 40% reduction in compute spend and a 25% faster median response time.
Every optimization decision was driven by monitoring, data, and technical pragmatism—not assumptions.
Final Thoughts
Cloud cost optimization isn’t about stripping systems to the bone. It’s about building the right system at the right size, with the right level of flexibility and resilience.
The most effective cloud environments aren’t the ones with the most features or biggest specs.
They are the ones that deliver exactly what the business needs—no waste, no surprises.
If you want to make a real difference, start by asking this one simple question during every system review: “Are we using exactly what we need?”
Because in the cloud, precision isn’t optional. It’s essential.
Disclaimer:
The views and opinions expressed in this article are solely those of the author and do not necessarily reflect the official policies or positions of the author’s current or former employers, or any affiliated organizations.
References
- Flexera (2025). New Flexera report finds 84 percent of organizations struggle to manage cloud spend. Flexera.
https://www.flexera.com/about-us/press-center/new-flexera-report-finds-84-percent-of-organizations-struggle-to-manage-cloud-spend - Gartner (2024). Keeping cloud costs in check: IT leader perspectives. Gartner Peer Insights.
https://www.gartner.com/peer-community/oneminuteinsights/omi-keeping-cloud-costs-check-it-leader-perspectives-rfz - ITPro Today (2021). Why FinOps is key to cloud cost optimization. ITPro Today.
https://www.itprotoday.com/ops-and-more/why-finops-is-key-to-cloud-cost-optimization - Deloitte (2024). TMT Predictions 2025: FinOps tools will help lower cloud spending. Deloitte Insights.
https://www2.deloitte.com/us/en/insights/industry/technology/technology-media-and-telecom-predictions/2025/tmt-predictions-finops-tools-help-lower-cloud-spending.html
About the Author
Sreekar Jami is a Senior Systems Development Engineer at Amazon Web Services. He has more than 10 years of experience designing cloud infrastructure that is scalable, secure, and cost-efficient. Sreekar focuses on helping teams build smarter systems through automation, right-sizing, and engineering best practices that control costs without compromising performance.




























