
As businesses engage with the global market, their audience continuously expands—more people engage with their goods and services, resulting in increasing demand.
However, many businesses forget that as their customer base grows, so should their systems—it allows businesses to keep up with the increasing number of users, ensuring a seamless experience for everyone.
When businesses fail to adapt to traffic spikes, they can risk going down, and all efforts to expand will go down the drain.
This is where auto-scaling comes in handy—it adapts to and manages load fluctuations, even when millions of people use the app or software simultaneously.
But is there a secret to auto-scaling? Can businesses scale their systems that quickly?
I’m Gaurav Bansal, a Senior Staff Software Engineer, and I’m here to tell you what you need to know about auto-scaling and designing adaptive infrastructure.
Auto-Scaling for Growth: Beyond the Basics
For many businesses, implementing auto-scaling practices is the first step in keeping up with constantly changing demand. While this is true, companies should not focus entirely on it. They need to look deeper—at the infrastructure.
But where should you start?
As complex as it might seem, ensuring your software is scalable and adaptable starts with three things:
- Understanding the nature of load fluctuations
- Differentiating between reactive and proactive auto-scaling
- Aligning technology choices.
Businesses need to remember that adding more resources doesn’t necessarily mean you’re adapting, especially when every system has its limits. What we need to keep up with increasing demand is a system that can sense change and respond to it even before the surge happens.[1]
If that’s how things should be, what does today’s typical auto-scaling strategy look like? And why is it filled with gaps?
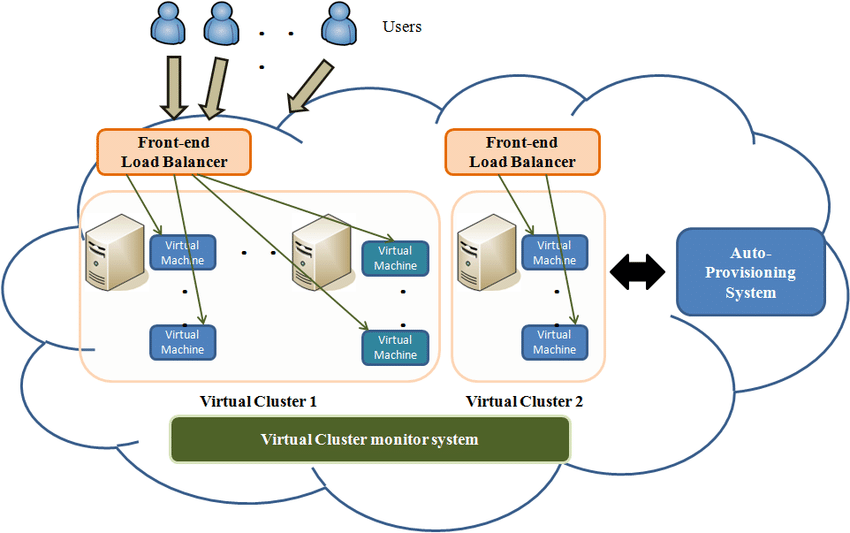
Auto-Scaling Model for Cloud Computing Systems. (Source: Yu Chen Hu et. al)[2]
The Future of Auto-Scaling: Effective Strategies for Better Handling Increasing Demand
Businesses start their auto-scaling strategy by automatically scaling resources based on predefined metrics such as CPU or memory usage. Many companies rely on this strategy, and while it is effective, it doesn’t consider other factors, such as:
- Load
- Types of traffic.
However, these aren’t enough, especially in today’s tech-driven world. Let’s enumerate strategies that enable companies to auto-scale dynamically.
Predictive Auto-scaling
Implementing advanced auto-scaling strategies, particularly predictive scaling, enables us to anticipate demand using historical data and machine learning models. This enables us to adjust our systems proactively instead of waiting to meet thresholds.[3]
During my time at Amazon, I’ve seen firsthand how predictive scaling works. It is useful in environments where we can reasonably forecast traffic patterns.
With this auto-scaling method, businesses can scale up their systems in anticipation of increased demand, ensuring they can handle the influx of traffic without delays.
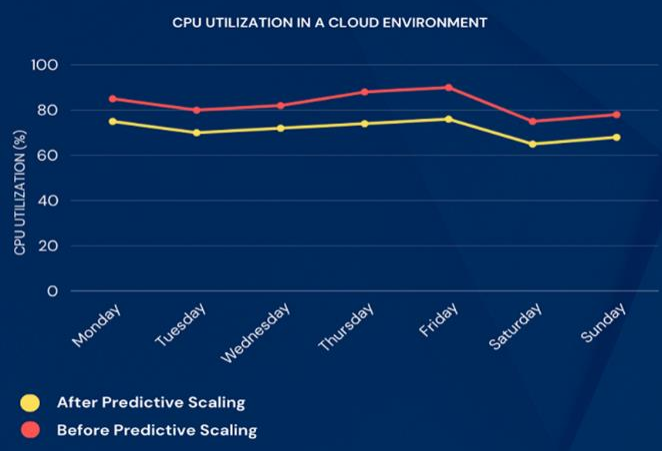
CPU Utilization Before and After Predictive Scaling. Source: IRE Journals[4]
We all know how annoying it can be during peak buying season, say Black Fridays or holidays. With predictive scaling, we can ensure the infrastructure is ready for the forthcoming traffic—before it even happens. This capability prevents any slowdowns, maintaining optimal performance, even when millions of users access the website or app simultaneously.
In simple terms, auto-scaling that uses technological advancements such as Artificial Intelligence ensures a smooth experience for every user, anytime and anywhere.
For example, Netflix developed Scryer, the platform’s auto-scaling engine, to address the limitations posed by its existing engine.
But how is Scryer different from traditional scaling methods like AAS?
AAS adjusts server counts based on current workloads, while Scryer analyzes historical traffic patterns to forecast demand and proactively provision resources. The company’s reason for such capability is simple: AAS cannot respond swiftly to sudden traffic spikes or outages caused by instant startup delays.
With this approach, the platform can ensure adequate capacity during peak periods and optimize resources during off-peak times. Scryer’s architecture includes the following:
- Modules for data collection
- Prediction algorithms (linear regression, Fast Fourier Transformation)
- Action plan generation
- Scaling execution.
When integrated into existing systems, this architecture enhances Netflix’s performance, cost efficiency, and resilience.[5, 6]
Load Balancing
Auto-scaling goes beyond adding or removing resources on demand—businesses also need to determine how to balance loads.
With load balancing, we can ensure the system routes traffic efficiently across all available resources, resulting in a smoother experience for users worldwide.
For example, Layer 4 (Transport) and Layer 7 (Application) are advanced load balancers that allow your system to distribute traffic efficiently based on a deeper understanding of user requests.
Let’s say Netflix and Amazon. This company considers uptime and low latency essential, so it’ll need an intelligent routing system that can account for factors such as session rates and geographic locations.
With such a requirement, Netflix and Amazon will implement Layer 7 to balance their traffic. This implementation will enhance the user experience while reducing delays, which is essential when scaling distributed applications globally.
![Layer 4 (Transport) and Layer 7 (Application) Load BalancersSource: Kemp Technologies[7]](https://techbullion.com/wp-content/uploads/2025/03/Layer-4-and-Layer-7-load-balancers.png)
Layer 4 (Transport) and Layer 7 (Application) Load Balancers. Source: Kemp Technologies[7]
- Layer 4 distributes traffic across servers based on network information such as IP addresses and TCP ports.
- Layer 7 routes traffic based on URL path, content type, or the user’s geographic location.[7]
These load balancers adopt granular rules, ensuring the right server handles the proper request—-optimizing performance while saving costs.
Challenges to Modern Auto-Scaling
Auto-scaling proves invaluable in an era when web applications serve a wide variety of content. It allows systems to adapt to the varying content and the demand for each type of content.
However, albeit effective, auto-scaling and load balancing also come with challenges.
As I worked with different organizations, I found cold starts, over-provisioning, and thrashing obstacles we needed to address. Let’s break them down together.
1) Cold Starts
Cold starts occur when a system forcefully spins up resources to handle increased load. These occurrences result in delays and potential service degradation, affecting the system’s performance.
While at Amazon, we encountered performance issues related to these cold starts as we scaled our services. The reason? We needed to use significant computational resources.
To address these risks, we focused on:
- Improving the warm-up times of instances
- Optimizing the provisioning logic to minimize the cold start overhead
- Using tools like AWS Lambda’s “Provisioned Concurrency” to ensure pre-warming and readiness of functions.[8]
2) Over-provisioning
As we took on more projects, the challenges we encountered grew—one of those included over-provisioning.
But what is it, and how does it happen?
Overprovisioning occurs when we allocate resources more than we need. When the system overestimates the traffic or workload, it leads to unnecessarily high resource utilization and increased costs.
And this is where predictive scaling comes into the picture.
With predictive scaling, we can leverage historical data and machine learning models to forecast resource requirements more accurately, enabling a more efficient and cost-effective capacity allocation.
At Amazon’s Cap Service, we had to handle 20,000 transactions per second (TPS) efficiently and without overloading our systems.
We balanced the load more effectively through predictive auto-scaling, ensuring we could handle the traffic spikes without over-allocating resources.
3) Thrashing
Systems can experience thrashing—constantly adjusting their capacity based on slight fluctuations in demand. This issue undermines auto-scaling efficiency and is prominent in dynamic environments with high variability, like Netflix and Amazon.
To prevent thrashing, we must fine-tune our auto-scaling policies—setting sensible minimum bounds for scaling and introducing hysteresis to reduce the frequency of scaling actions.
At Amazon, I led the initiative to improve the reliability of the Vendor Financial pipeline, carefully tuning our auto-scaling policies to ensure we weren’t scaling up and down unnecessarily. This initiative resulted in a more stable system that could handle traffic spikes without over-allocating resources.
However, are these initiatives enough, especially in large-scale systems?
While auto-scaling and load balancing are critical in maintaining a scalable system, software performance still plays a crucial role in ensuring low latency and optimal user experience.
For example, at Amazon:
Amazon Prime Video optimized its use of Amazon DynamoDB to support its growing global user base and high-demand video streaming. Key optimizations included implementing auto-scaling to manage traffic spikes during popular events, reducing read and write capacity by 50% using efficient indexing techniques, and utilizing Time-to-Live (TTL) for data management. These improvements significantly reduced latency, eliminated throttling, and resulted in a substantial reduction in operational costs. (Source: AWS)[9]
4) Reliability
Since the beginning of my career, I have realized that reliability is another crucial factor when designing scalable systems. Ensuring a system’s scalability will also rely on its fault tolerance—the capability to recover quickly from failures.
When we designed Amazon’s scalable systems, we built architectures that can withstand anticipated failures and unpredictable anomalies, increasing reliability. Whether redundancy, disaster recovery, or the use of circuit breakers, we implemented strategies that ensure continued services even in critical failures like an outage.
5) Observability
Can we say our system is adaptive and scalable if it can’t be monitored, logged, and traced?
An observable system enables us to understand how it performs—overloaded or underloaded—to identify potential bottlenecks. Tools like Prometheus, Grafana, and ELK (Elasticsearch, Logstash, and Kibana) enable us to see real-time insights about system performance, which can help us identify strategies to ensure efficiency.
With observability, we can rapidly identify issues and optimize our system—resulting in better performance and, ultimately, satisfied customers.
Final Thoughts: Auto-Scaling for a Future-Proof System
Reflecting on my career, I’ve seen companies like Amazon and Netflix achieve astounding results by designing and implementing adaptive and scalable systems that provide reliability while enabling flexibility as they continuously grow.
When scaling for millions of users, we need to ensure that every aspect of the system is finely tuned—handling unpredictable traffic, optimizing resource usage, and providing a constantly smooth experience across the globe.
And the only way we can achieve such a system is through its architecture, which goes beyond auto-scaling and integrates multiple advanced and innovative strategies and techniques.
By understanding the application’s specific demands, we can design an architecture that’s future-proof and ready to provide services to users whenever and wherever they need them.
References
1) Nan Labs Blogs. (2024). Best Practices for Building a Scalable Infrastructure
Retrieved from https://www.nan-labs.com/blog/scalable-infrastructure/
2) Hung, C.-L., Hu, Y.-C., & Li, K.-C. (2012). Auto-scaling model for cloud computing system. International Journal of Hybrid Information Technology, 5(2), 181–188. Retrieved from https://www.researchgate.net/publication/256441401_Auto-Scaling_Model_for_Cloud_Computing_System
3) Google Cloud. (2021). Introducing Compute Engine predictive autoscaling. Retrieved from https://cloud.google.com/blog/products/compute/introducing-compute-engine-predictive-autoscaling
4) IRE Journals. (2021). AI-Powered Predictive Scaling in Cloud Computing: Enhancing Efficiency through Real-Time Workload Forecasting. Retrieved from https://www.irejournals.com/formatedpaper/17029432.pdf
5) Netflix Technology Blog. (2013). Scryer: Netflix’s predictive auto-scaling engine. Retrieved from https://netflixtechblog.com/scryer-netflixs-predictive-auto-scaling-engine-a3f8fc922270
7) Netflix Technology Blog. (2013). Scryer: Netflix’s predictive auto-scaling engine – Part 2. Retrieved from http://techblog.netflix.com/2013/12/scryer-netflixs-predictive-auto-scaling.html
8) Kemp Technology Blog. (2023). Layer 4 vs. Layer 7 load balancing: Which should I choose?. Retrieved from https://kemptechnologies.com/blog/layer-4-vs.-layer-7-load-balancing-what’s-the-difference-and-which-one-do-i-need
9) Cui, Y. (2019). AWS Lambda provisioned concurrency: The end of cold starts. Retrieved from https://lumigo.io/blog/provisioned-concurrency-the-end-of-cold-starts/
10) AWS Blogs. (2024). Amazon DynamoDB use cases for media and entertainment customers. Retrieved from https://aws.amazon.com/blogs/database/amazon-dynamodb-use-cases-for-media-and-entertainment-customers/
About the Author
Gaurav Bansal is a Senior Staff Software Engineer at Uber with experience designing and implementing adaptable and scalable architecture for software and applications. As a leader, Gaurav is dedicated to creating solutions that support millions of users globally. Whether auto-scaling large-scale systems or suggesting strategies, Gaurav ensures that his work directly impacts an application’s reliability and efficiency.
Views and Opinions expressed in the above doc are my own and not affiliated with Uber


































