Athmakuri Naveen Kumar – Senior Software Engineer.
Author: Athmakuri Naveen Kumar – Senior Software Engineer.
A proper and timely diagnosis is essential for effective rehabilitation and treatment of leukaemia, a kind of cancer that can be deadly. Automated computer technologies have replaced traditional techniques for analysing, diagnosing, and forecasting symptoms. In this study, a comparison of two distinct leukaemia detection techniques was conducted. The techniques were a multi-class classification model, which used to be once an image-processing technique, and sequence of genomic approach, it is a binary classification mannequin. The enter values for the strategies varied. But for their neighbourhood design, they every employed convolutional neural networks (CNN). Additionally, they used 3-way cross-validation to divide their datasets. Learning curves, a confusion matrix, and a classification file have been the evaluation methods used to analyse the outcomes. The results verified that the genome mannequin carried out higher, with a total accuracy of 98% for a number of values that were accurately predicted. This result was contrasted with the findings of the image processing technique, which had a total accuracy value of 81%. The varying test results of the algorithms may be caused by the size of the various data sets.
Introduction
Every year, medical practise is modernising and transferring toward extra computerized techniques that beautify and enhance the healthcare industry’s potential to grant greater wonderful remedies and correct diagnoses. By utilising machine learning, diagnostic techniques are redefined and values are raised. Cancer research has expanded over time into other domains and used deep learning techniques like genome sequencing and image screening. The accuracy of test findings for cancer predicting techniques has also grown as a result of the new therapies and diagnostic approaches. It can be difficult for doctors to manually diagnose different forms of cancer, but there are techniques like genome sequencing that can successfully find patterns in input data and recognise patterns in input values. Deep learning, which is a subset of artificial intelligence, is described as a laptop computer that gathers raw data using a logical framework and functions similarly to the human brain. The neurons that make up Artificial Neural Networks (ANNs) are where information is accepted and stored at each layer before moving on to the next. It creates a multi-layered complicated structure. As a result, the system can obtain data without assistance from humans. An effective example of an ANN is a convolutional neural network (CNN). Advanced techniques can be utilised to assist patients in identifying deadly diseases like leukaemia, a prevalent cancer type in youngsters and a lethal illness. A type of cancer called leukaemia starts in bone marrow and blood cells, where it produces immature blood cells when the body doesn’t require them. A frequent blood take a look at referred to as a white blood count number (WBC), which is normally carried out manually to seem to be for leukaemia cells, can be computerized through the use of computer mastering strategies like CNN. It is an effortless and speedy method to behavior a take a look at and locate blood abnormalities. Genomic sequencing is any other approach used to discover aberrant markers in DNA sequences and coding and non-coding regions. Using biomarkers, this is performed to predict or discover most cancers. DNA sequences are the input data for genomic sequencing, which is made up of nucleotides. Adenine, cytosine, guanine, or thymine are the four nitrogen bases found in nucleotides. The primary structure of DNA is a double helix, which is formed by their base pair. Despite all the advantages of AI, such as its potential to cure illnesses, there remain worries and ethical issues. These worries centre on data privacy and how it can impact both the patients’ and their genetic relations’ safety. Additionally, it provides benefits for the scientific system, supporting docs and offering 2d views to enhance the precision of diagnosis. However, there is a chance of genetic discrimination.
Purpose
In order to resolve the trouble of automatic diagnosis, the intention of this lookup is to habits a comparative analytical find out about on most cancers detection fashions that utilise deep learning. The initiative additionally employs two wonderful leukaemia detection methods. The cause of this lookup is to evaluate two fashions that utilise deep gaining knowledge of to diagnose leukaemia in order to talk about how AI is used in this field. The goal is to showcase, educate, and engage in a discussion on a few specific applications of cancer predictive AI techniques as well as the advantages and difficulties of cancer detection models.
Biological Theory
DNA
Deoxyribonucleic acid, or DNA, is the substance that gives rise to genes and is found in the cells of living things. It contains instructions on how to make the proteins necessary for eukaryotic organisms’ chromosomes to function. An organism that has one or greater cells having genetic cloth that can be determined indoors the mobile membrane is referred to be a eukaryotic organism. Nucleotides, which are massive macromolecules made up of sugar, a base, and a phosphate group, make up the DNA. These elements combine to create a DNA strand, and when two strands join forces, It produces a double helix, a kind of DNA structure. The nitrogenous bases are what link these strands together. Figure 1 shows that there are four distinct nitrogenous base molecules. They are Thymine (T), Guanine (G), Adenine (A), and Cytosine (C). Adenine binds with Thymine, whereas Cytosine bonds with Guanine, and the base shape solely pairs and bonds with different nitrogenous bases. diverse genetic traits created by diverse nitrogenous base arrangements store information about the various activities of cells.

Figure 1. Nitrogenous base – DNA sequence
Genomes are collections of DNA that include many different genes. These genes, which are present in all cells, contain the information needed to create and maintain an organism. Base pairs are the fundamental units that make up a DNA helix. They are made up of two nucleotides joined together by hydrogen bonds.
Genome annotations are used to pinpoint the region of a gene that determines its function. This method identifies the coding and non-coding sections on a DNA sequence and sheds moderate on the attribute of the sequence. The DNA’s non-coding regulatory strand controls how and when genes are employed, whilst the coding strand carries the message code for producing proteins for the cells. 2.1.2 Malignancy Cancer is the 2nd most frequent purpose of mortality, in accordance to the WHO. Any region of the body might experience it as quickly expanding aberrant cells. Cancer is a category of illnesses that can manifest in various ways and exhibit a variety of symptoms. Cancer can occur for a number of causes, including genetic mutation and bad lifestyle choices. The DNA amino acid sequence is altered or shifted by the genetic mutation, which results in mutant cells with a changed sequence order. Examining potential cancer patients involves numerous phases, including blood testing and physical examinations. Leukaemia is a type of blood cancer that can create more or less different types of blood cells. The immune gadget and white blood cells (WBC) are the main organs affected through this. Neutrophils, lymphocytes, monocytes, eosinophils, and basophils are the 5 outstanding sorts of white blood cells; solely the ranges of the first 4 range when the physique has cancer. The WBC check is designed to be carried out automatically, counting the volume of white blood cells and evaluating it to a reference desk that may range between locations. The relationships between the more than a few white blood telephone sorts for ordinary blood levels are shown in Table 1. A body’s immune system battling a virus and an inability to manufacture enough antibodies are both indicated by a reduction in lymphocytes and neutrophils. Eosinophil and monocyte counts rising might be signs of blood diseases including leukaemia. The number of cell types per microliter of blood, which also includes blood plasma and other physiological fluids.
Table 1. Reference for WBC count
| WBC Types | WBC Count – % |
| Neutrophil | 60-70 % |
| Lymphocytes | 25-35 % |
| Monocyte | 4-9 % |
| Eosinophil | 1-4 % |
Machine learning
Artificial intelligence includes the concept of machine learning, which is commonly understood as a software program machine with the understanding to analyze from trip whilst performing a set of tasks. How laptop studying works is described via three key factors. Tasks, experience, and overall performance are these factors. Tasks are datasets used to hone a computer’s performance. The laptop gadget can strengthen into a subtle mannequin over time and with practise, gaining knowledge of from its errors and prognosticating the answer to a problem. Machine mastering makes use of a range of methods, however they may additionally be divided into two groups: supervised studying and unsupervised learning. The method the use of a set of education records was once additionally referred to as the supervised studying group. Each pattern in the dataset carries an enter object and an output object. The algorithm ought to function on manually provided responses in order to try to categorise the output. The education statistics is necessary to this type of working procedure. As a result, for the algorithm to make experience of the data, the set need to be accurate. Unsupervised getting to know is when an algorithm searches thru a significant volume of facts for hidden patterns. This variety of strategy allows the laptop algorithm to run and decide the in all likelihood end result patterns. Because of this, it is not possible to decide which response is right or incorrect. There are established and unbiased variables in laptop learning. Predictor or manipulate enter are different names for the impartial variables, which include the values that govern the experiment. The impartial variables manipulate the based variables, once in a while referred to as the output values.
Deep learning architectures
A division of desktop mastering is deep learning. It is a way of mastering that works with various layers and progresses to a greater diploma of abstraction. The severa layers of a neural community made up of nodes are referred to as “deep” layers. Based on the output from the preceding layer, every layer in the community used to be educated on a unique characteristic. By constructing an structure primarily based on neurons, deep gaining knowledge of is stimulated by way of the shape of the human brain. Massive numbers of neurons are interconnected in the human Genius and shape a community of conversation via alerts it receives. An synthetic neural community (ANN) is the title given to this idea. The ANN algorithm builds layers that pass by enter values from one layer to the next, culminating in the output end result proven in discern.

Figure 2. Neural Network – Outlines of System
When using deep learning, people do not affect the neural network’s layers or the data being processed. Since the system algorithms have been taught using data and learning processes, humans do not need to handle it manually. Higher-dimensional data may now be managed using the approach. With regard to managing categorization, analysis, and translations of more complex regions, the system technique has shown encouraging results.
Convolutional neural networks
There are many tiers of reliance for CNN, one relying on spatial distances. Grid-structures, which are archives containing three-d snap images and shut via spatial relationships linked to the color values of every and each pixel in an photograph, are how it operates. It can file shades the use of 3D structured input. CNN indicates a variable diploma of translation and interpretation, which may additionally manner an augmented picture, which is an image that has been grew to be upside down or shifted in a couple of instructions. With different grid-structured data, this is unusual. The CNN consists of at least one convolutional layer, even though it can incorporate extra layers. It is considered as a simple neural community to train. A absolutely related layer or layers comply with the convolutional layer in a traditional multiple-layer network. A convolutional layer that approaches an picture extracts facets from an enter that passes via more than a few kernels. The pooling layer down samples an input with the aid of shrinking its dimensions whilst retaining all of the pertinent data. The absolutely related layer connects the neurons in the following layer to the output from the previous levels. Numerous hyper parameters, or network-structure-determining factors, are blanketed in CNN.
processing of genetic information earlier than use While many algorithms can interpret vector-matrix data, it is extra hard to convert DNA sequences into matrices. Since values from genomic facts are no longer designed to be processed as ordinary text, the facts ought to be transformed into a structure that the mannequin can use. With the useful resource of Label Encoder() from the Sklearn package, the enter is modified into numerical labels with values ranging from zero to N-1. Using a one-hot encoding() feature from Sklearn, the one-hot encode strategy resolves the hierarchy trouble barring introducing one for the mannequin with the label encode data. By dividing the values into columns and turning them into binary integers that completely have the values zero and 1, it converts the sequence. As a end result of the deep mastering algorithm’s lack of ability to deal without delay with specific records or words, this is achieved in order to make the statistics greater expressive and allow the gadget to lift out logical operations.
Pre-processing of Image data
In order for an AI model to process a picture, it must be enhanced or have some valuable information extracted from it. This process is known as image processing. The mathematical feature (x,y), the place x and y are the coordinates of an image, defines an photograph as a two-dimensional array of integers. The array integers characterize pixel values in the zero to 255 range. The photo height, coloration scale, width, and wide variety of levels/pixel are the photograph enter parameters. Red, Green, and Blue (RGB) are now and again recognised as channels when referring to the colour spectrum. Making ensuring that all of the photos have the same base dimension is the first stage of pre-processing. The next step is to resize the pictures once every image has the same aspect ratio. Several library functions can be used to upscale or downscale them. To provide a comparable data distribution, they are also normalised. Each cost in the normalised pixel values levels from zero to 1. This is due to the truth that a community methods inputs the use of weight values, and decrease values would possibly hasten the network’s getting to know process. The RGB channel can be converted into a grayscale picture to further minimise the size. Another processing method called data augmentation uses picture conversion to broaden the variety of a dataset. An picture may be enhanced by rotating, zooming, or adjusting the brightness.
Evaluation model
The assessment process includes the analysis and interpretation of the data, and there are several evaluation techniques accessible. This is done to arrange and provide clear outcomes that are understandable so that they may be used and improved. 2.3.1 Matrix of Confusion A classification model’s prediction outcome is summarised by a confusion matrix or error matrix. Figure 3 compiles information about a model’s overall performance on a dataset in a easy manner. It categorises them to display how the mannequin is confused when making a forecast whilst additionally highlighting the faults seen. The first column of the matrix represents a high quality forecast, and the 2nd column a terrible prediction, in accordance to the interpretation. A right statement category is proven in the first row, whilst a bad remark type is proven in the 2d row. True effective (TP) is the designation for tremendous observations and wonderful predictions in the first column. In different words, the classifier’s prediction is right and favourable. True terrible (TN) denotes a correctly negative forecast. False-positive refers to a forecast that is wrong yet positive, whereas false negative (FN) refers to a prediction that is erroneously classed as being negative.

Figure 3. A Confusion matrix
Validation
A trained model is tested using a piece of the testing data as part of the validation phase. This is carried out following model training and is used to consider the overall performance of a post-trained mannequin.

Figure 4. 3-way cross validation
The holdout approach falls under the kind of three-way cross-validation. Cross-validation is a approach for assessing the output of a prediction model. This technique is a reachable validation in which the datasets are first limit up into educating and making an try out sections. The holdout set, which is considered in determine 4, consists of the validation segments that have been presented from the instructing set. The holdout set is set apart and utilised to alter the hyper-parameters and take a look at the prediction mannequin the usage of new records that have been now not used at some stage in mannequin education or trying out. The data samples are divided into subsets that are utilised for analysis and for validating the analysis as part of the validation process. It is employed to lessen bias and overfitting.
Logarithmic Loss
A classification loss characteristic used in desktop studying that is based totally on chances is known as a logarithmic loss. This feature assesses how nicely a mannequin predicts when the likelihood values vary from zero to 1, and it may also be used to calculate the loss in a model. Because it improves the classifier’s accuracy, the goal is to limit the fee till it reaches zero. The mannequin would then be considered as flawless. This attribute determines the everyday big difference between the likelihood distributions for predicting a classification price that are actual and predicted. Another loss attribute used for multi-class classification is ignore by using entropy, the vicinity every cost in the set of values 0, 1, and three has an impartial integer value. The feature determines the well-known discrepancy between the anticipated opportunity distributions and the actual hazard for each and every class worried in the problem. When it is 0, the calculation’s ranking price is minimised and ideal.
Method
The goal of the study process is to analyze greater about the theme of deep mastering and its use in the discipline of medicine. Two fashions are carried out and evaluated for the duration of the experimentation phase. Due to its simple organised find out about sketch and iterative technique, Takeda’s General Design Cycle (GDC), which is depicted in parent 4, used to be chosen as the lookup methodology. Each cycle yields a result that is compared to the outcome of the following effort. This is done to evaluate the research’s quality and continually advance it. These are qualities that are crucial for the project because it calls for comparing and contrasting tests in various ways.

Figure 4. Research Methodology – Development of System
Identify and Analyse
The analysis phase of the process is when ideas are formed from a problem. The primary issues are determined by a literature review of prior, relevant efforts in the fields of genetics and ethics with deep learning. The concept chapter, which is stated in Chapter 2, consists of the crucial elements that furnish readability and are utilised to bring together a trouble tree that emphasises the project’s more expansive domains. In Chapter 1, the bother is delineated with the useful resource of the research questions RQ1–RQ2.2. System Design 4.2 The second phase involves designing a diagram that illustrates the project’s workflow from data collection through testing and outcome evaluation. Making a representation of the process and outlining the needed functionalities might be creatively done during this step. A process description of the system’s many phases, including dataset selection and preparation, is described in chapter 5. All of these processes are necessary to get the models ready for use and testing so that the output produces reliable results.
Model Implementation
The model was put to the test in the third stage. In this step, all the specifics for the application and testing of both models are described. The models are put into practise using the knowledge and design from earlier processes. The datasets from the genomic sequence method and the picture processing technique are used to educate and consider the model’s community architecture. 4.4 Assessment The machine is discovered and evaluated in the fourth stage of the procedure, which is an chance to decorate the take a look at results. This phase’s records proven if the cost supplied in formerly checks is in accordance with the experimental results. The output from the effects is utilised to reply to the lookup query about the range of approaches, which is beneficial for the following stage. The mastering curve and confusion matrix are utilised in each strategies to examine and check the overall performance of the fashions.

Figure 5. Problem tree
Google Collaboratory, a free cloud-based imitation of the Jupyter pocket book programme, used to be employed in this procedure. There is a giant library covered with Google Colab, which additionally provides the most famous deep getting to know apps. Through a Google account that hyperlinks to Github to down load or submit repositories, one may access it to process algorithms. Python is the programming language used in the software, which can construct and display graphs and matrices. An open-source software library called Tensor flow employs tensor-capable mathematical techniques. The output of the library is expressed as graphs and an n-dimensional matrix. It is adaptable and simple to utilise for training architecture thanks to its modularity properties. Multiple networks might also be processed and skilled via Tensorflow. As a result, it is beneficial whilst utilising a higher system. Tensorflow is the backend science used with the aid of the Python neural neighborhood library Keras to create fashions and graphs for laptop computer learning. It can be used in honestly any neural neighborhood fashions and processed swiftly on every the CPU and the GPU. When working with photographs or text, Keras is normally utilised and handy to use. Python’s Scikit-learn module can also be used to enforce algorithm(s) in difficult mannequin training. It performs a large vary of tasks, together with mannequin decision and classification. The library affords features like cross-validation that decide the model’s correctness. To extract statistics from images or text, Scikit Learn additionally manages unsupervised neural networks and characteristic extraction. A computer gaining knowledge of library referred to as Numpy collaborates with different libraries to lift out array operations. For implementations of state-of-the-art mathematics, the library is easy to use. When working with binary expression in an array of n-dimensions, pictures, or sound waves, these properties are used. Panda is a Python package with a variety of capabilities for data structure analysis. The library’s built-in capabilities, which include data manipulation and operation translation, offer flexibility and high functionality.
Data preparation
The gathering and pre-processing of the dataset is a crucial phase in the production of the data. This explains the sources of the datasets and the websites that provide databases containing blood sample image data. Datasets for both approaches are acquired and prepared during the pre-processing step by way of formatting the measurement of the genomic sequences and photos. This stage explains the place the dataset originates from and the pre-processing coaching processes, and that it is to adapt them to the models.
Experiment
The experiment stage comprises of two models: the blood smear picture for the leukaemia diagnostic technique and the cancer marker detection approach. The models use CNN architecture and are trained one at a time. Each action that takes place during the experimentation phase is described in this stage. It describes the pre-processing and uploading of the datasets. Three-way cross-validation is being used to split up the datasets for the models. The datasets are divided 75:25 between a training set and a testing set. 25% are used for testing, whereas 75% are for training. This section also explains how the models are developed, evaluated, and used to carry out classification tasks. 5.1.4 Observation and Assessment In this phase, both approaches have generated findings that are examined separately and contrasted in sections 5.4 and chapter 6. It is to go via the drawbacks and blessings of each fashions as properly as how nicely they labored in positive situations. The mannequin employs a confusion matrix as its classification document and a studying curve to measure overall performance at some point of training. The furnished findings in part 5.4 will check the model’s predictability and correctness.

Figure 6. System Design
Collecting datasets
This step explains how to locate and create a dataset for both techniques. It outlines how the samples of data will need to be pre-processed before being incorporated into the models. Genome dataset (5.2.1.1) A database of assets for biotechnology and informatics equipment is accessible from the National Centre for Biotechnology (NCBI), a country wide organization of fitness. A sizable gene bank with billions of nucleotide base pairs is kept by NCBI. The NCBI Genebank provided the data sample that was utilised for the genomic sequencing technique. They provide a search option that may be customised on their website. It made it easier to focus the search results from their extensive database. Leukaemia was typed into the search box, and the parameters were modified to homo-sapiens and at least 100000 bases per nucleotide. This would have removed any other species-related search results. A competent biotechnical team handled the cancer annotation, which is the cancer markers, in the cancer dataset. The samples utilised had a pattern measurement of 10500 bp, have been saved in textual content layout with 2000 rows, and every row had 50 bp. They were in the Fasta format. The dataset’s rows were seen as individual inputs.

Figure 7. Formatted Genome Dataset
The dataset required to be formatted and reshaped during pre-processing once all the data had been collected. Figure 7a displays the raw data without a 2000 by 50 grid and with space and annotation numbers. All sequences were manually formatted by being copied to a undeniable textual content document. Then, all of the numbers in every row have been eliminated. Then, to make positive there were 50 nucleotides on each row, the number of nucleotides in each area was tallied. There was no gap between any of the letters. The dataset was prepared for the pre-processing stage in figure 7b once it resembled figure 7b.

Figure 8. Pre-processing steps of Genomic
Blood smear images
White blood cell subtype images from the BCCD dataset were represented by the blood smear data samples. Additionally, BCCD’s GitHub and Kaggle accounts contain these samples. The data sample includes 10,000 JPEG photos that have been independently confirmed. In order for the algorithm to spot the aberrant cells, the WBCs were coloured to make them more noticeable. Additionally, it features CSV file cell-type labels, and each folder had around 2500 enhanced photos for each cell-type.

Figure 9. microscope images of different white blood cells
For quicker model training, the picture dimensions were downsampled from 640×480 to 120×160. There were photos for each type of WBC in the datasets, which had been divided into education and trying out sets. To increase the pattern measurement and variety, the pics have been more advantageous such that there had been an equal wide variety of pix of the a number of mobile phone sorts in every education and trying out folder.
Pre-processing
The essential datasets were ready for use thanks to the pre-processing data. Figure 9 depicts the four components that made up the step. By locating and eliminating incorrect and inconsistent properties, data was cleaned. This was done to lessen the chance that a result would be incorrect or rejected by the model. Cleaning the dataset includes removing whitespace and other characters. The datasets were combined throughout the integrating process to prevent confusion and duplication of effort when the same variables are used to refer to distinct values. The dataset needs to be modified after cleaning and integrating.

Figure 9. Phases of Pre-processing
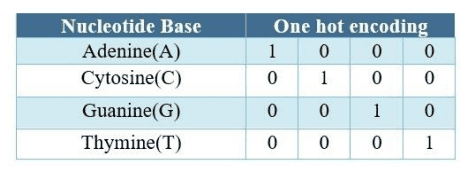
Numerical matrix containing four-dimensional vectors, the data used to be once organized for compression. A variety between zero and three was once assigned to every nucleotide. As a result, the dataset obtained a numerical context that the algorithm ought to without difficulty interpret. The nucleotides now have values encoded by way of labels, which resulted in a range order that may also throw the mannequin off. The mannequin was once uncertain due to the fact it idea that adenine was once continually first however the enter sequence due to the fact of how the enter values had been carried out in a hierarchy. The scikit-learn one-hot encoding strategy would possibly be used to overcome the hierarchy issue. In desk 2, you can see how this modified the sequences by using the usage of along with four columns and remodeling the values into a four-digit binary code. The previous integers had been modified to ones and zeros, arranging every digit in an personal column. Each row represents a nucleotide with a predetermined fee that was once entered into the cells.
Table 2. Labels of DNA- sequence and one-hot encoding
Model implementation
Method 1 for genomic sequencing The raw datasets were stored in a text file and submitted through a URL. The data was organised into a format that could be handled thanks to the filter() function, which made sure that no empty sequences remained. The matrix was created from the DNA sequence. One hot encoding from Sklearn enabled it to be completed. The bases were transformed into an integer array by LabelEncoder(), which was then transformed into a matrix by OneHotEncoder(). The coaching set was once similarly separated into validation and education sets, which saved parts of the dataset to decide whether or not or no longer the based variables symbolize a predictor of cancer. A 1D convolutional neural community served as the groundwork for the model’s community design. To rapidly create the community the usage of the library Keras. In the pooling layer the usage of MaxPooling1D, the 32 filters had been down-sampled. By converting the matrix from each pooling layer into columns in the following layer of CNN, the matrix was created. The layer with 16 tensors was applied using activation=’relu’ for the dense function, while softmax was utilised as the secondary activation function. Following training, it showed a learning curve and plotted the accuracy and loss of the network using the binary classification task. The model’s loss was calculated using binary_crossentropy before utilising the compile function.
Image processing- Method 2
The pics have been pre-processed by way of bettering them and the usage of a coloration enhancer to make the WBC mobilephone exhibit up elevated on the RGB scale. This used to be carried out so that the snap pictures may additionally moreover prefer to be considered increased easily. It used to be as soon as quickly as performed by the utilization of the use of that modified them to integers. The CSV file with labels used to be encoded in a single pass. The train_test_split() attribute used to be used to divide the files samples into training and testing. Validation_split=0.25 used to be utilized to the schooling samples. That is, 25% of the teaching statistics used to be used for validation. To assurance that the values had been sampled at random, a random module used to be used to shuffle the photographs such that every new take a appear at produced a one of a kind image. This mannequin used to be as quickly as educated the utilization of 2D convolutional kernels and, as previously described in chapter theory, entails of many layers that the pics bypass thru. CNN eliminated the enter layer and utilised the activation characteristic ReLU, activation=’relu’, to discover probably poor values in an photo dimension matrix. Because the pictures have been too large to analyse, the mannequin used a pooling layer to limit the measurement to 120×60 by using executing Keras Max Pooling. Learning curves had been utilised to affirm the educated model’s performance. The optimizer for a multi-class classification problem used to be ‘adam,’ the loss attribute used to be set to loss=’categorical_crossentropy,’ and the accuracy metric used to be as soon as quickly as ‘accuracy.’ After training the model, the output was once as soon as plotted the utilization of a plot function. A confusion matrix used to be additionally generated by means of the model.
Evaluation
The outcome of genomic sequencing The goal of this approach used to be to become aware of most cancers. Each row has 50 nucleotides. To train the model, the epochs had been set to 50. The model’s overall performance is depicted in the two figures beneath 10a-b. The model loss represents the uncertainty of the model prediction, whereas the accuracy measures the mannequin prediction performance. In mum or dad a and the accuracy plot, the gap between the training and validation lines is modest. The training and validation lines begin to diverge from each other about 0.92 and end around 0.97.
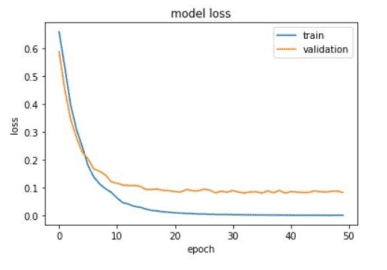
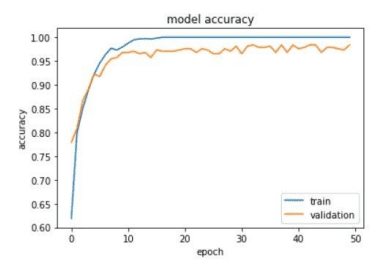

Figure 10. genomic sequencing test – plots
According to the confusion matrix, the mannequin had a prediction rating of 0.97, TP, indicating that it detected markers and efficiently seen them 97% of the time. The TN authentic expected non-cancer markers 99% of the time. The percentages for the two mistake types were 3% and 1%, respectively.
The outcome of the image processing procedure The trained model’s overall performance was once decided with the aid of accuracy and validation loss, as proven in figures 11a-b. It also demonstrated the precise identification of distinct kinds of white blood cells using the confusion matrix. The method used to be as soon as designed to find out the four kinds of white blood cells: eosinophils, lymphocytes, monocytes, and neutrophil s. To consider whether or not the analysis was once most cancers or not, the diploma of WBC had been excessive or low from CBC.
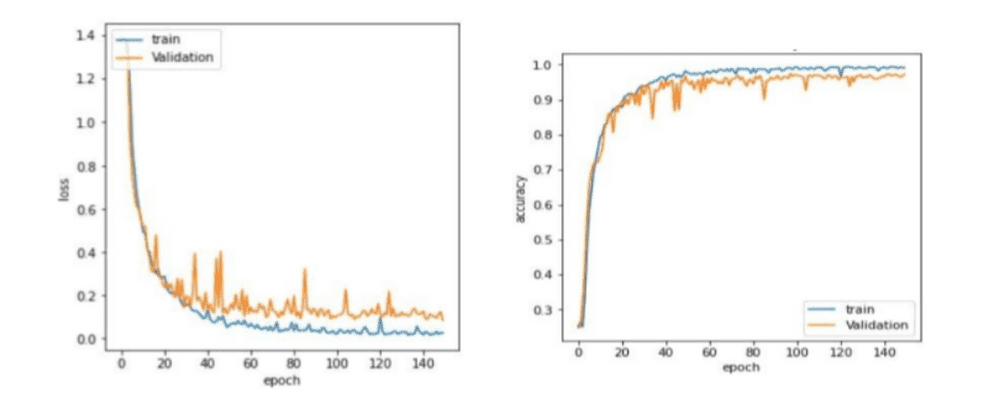

Figure 11. Image processing test – plots
On the other hand after about forty epochs, the traces commenced out to diverge. This can also moreover propose that the mannequin had a pretty excessive prediction value, as considered in dad or mum 11c, the area the accuracy was once as soon as quickly as calculated the use of accuracy_score and prediction values from sklearn metrics. The confusion matrix additionally blanketed the numbers 0-3. The absolute best genuine prediction price and the lowest false prediction fee when in contrast to the different WBC kinds. Monocytes and eosinophils ought to be in decrease numbers than neutrophils and lymphocytes. It boosted WBC two and three ranges whilst lowering WBC kind 0, and 1 was once a signal of leukaemia.
Classification Report
It assessed the accuracy of the algorithms’ predictions the usage of the confusion matrix. The computations had been gathered into two tables and based totally on equation. The tables under exhibit the prediction accuracy for every category as properly as the standard accuracy. It refers to the universal overall performance of the approach. The categorization document for the first method for genomic sequencing is proven in Table. Positive most cancers symptoms are categorized as category 0, whereas non-cancer markers are categorized as type 1. Table three suggests the classification document for the genomic sequencing approach.
| Class | Recall | Precision | F1-Score | Total accuracy |
| 0 | 0.93 | 0.91 | 0.92 | 0.95 |
| 1 | 0.95 | 0.96 | 0.96 |
Table 4 revealed the recall, F1-score, precision, and accuracy for every white blood mobile from the photograph processing classification report. It additionally shows the complete overall accuracy technique. Table 4: Image processing technique classification report.
| Class | Recall | Precision | F1-Score | Total accuracy |
| Neutrophil (0) | 0.65 | 0.85 | 0.74 | 0.86 |
| Lymphocytes(1) | 0.86 | 0.64 | 0.73 | |
| Monocytes (2) | 0.94 | 0.74 | 0.81 | |
| Eosinophils (3) | 0.94 | 0.94 | 0.98 |
Discussion
Analyzation Methods
Takeda’s GDC approach was once chosen in the venture due to the fact of its iterative skills and flexible shape on every phase, as explained. The Takeda strategy used to be simple and adaptable. This supposed that the ranges would possibly be reinterpreted to meet one’s grasp of the mannequin as lengthy as they adhered to the methodology’s predominant principles. The framework of Chapter 5 was once based totally on every step of the GDC method and furnished the consequences of every phase. Consideration of comparable work Papers on lookup that have been comparable or had some relation to this venture had been blanketed in the associated works section. Each information was once as soon as crucial to a certain neighbourhood of the research, One conceivable clarification for the first model’s increased accuracy is that the dataset utilised used to be as soon as quickly as a fantastic deal an awful lot much less than the snap photographs dataset, which consists of ten thousand images. The dataset sizes had been chosen to exquisite go properly with every and each approach; lowering the photo method dataset would be useless in minimising bias in the strategy and would overfit the model. It is difficult to find out a in a associated way massive dataset for a genomic sequence, and manually pre-processing the dataset would be time-consuming. The genome mannequin is likewise a binary classification, with the sole aim of classifying markers as cancerous or not. This decreased the model’s workload, however it additionally intended that the mannequin used to be a primary CNN implementation as adverse to the model, which used to be a multi-classification model.
The writer writes about integrating imaging software program equipment and transferring from guide labour to an automatic manner in the find out about titled Artificial Genius in digital pathology: a roadmap to hobbies utilization in medical practise. This article targeted on histology, which used to be same to the 2d approach, which processed images of blood smears. The WBC take a look at was once generally carried out manually, and only these days has the labour procedure end up increasingly more mechanised. The article mentions how automation of pathology exams speeds up the technique and reduces ready time. The creator examined the advantages of AI in healthcare as properly as moral difficulties in his paper Artificial talent in healthcare: a vital overview of the prison and moral consequences. The creator raised troubles such as prejudice and facts infiltration that would possibly occur whilst dealing with touchy affected person information. This dissertation made use of human DNA sequences. Despite the truth that acquiring a pattern used to be now not difficult, the NCBI internet site did no longer expose the wide variety of people to whom the pattern belonged and solely had a confined dataset accessible for public usage. The blood pattern pics have been elevated challenging to reap seeing that they had to come from leukaemia patients, and most internet websites required a carried out consent form to be delivered to the proprietor of the samples in order to use them. These are the norms and pointers that may additionally moreover be mostly primarily based absolutely on the GDPR regulation specified. Because it safeguards the privateness of the data owner, the rules makes working with computer gaining knowledge of problematic.
Findings from the analysis
The paper used to be a evaluation lookup that employed an awesome strategy to become aware of most cancers in their separate records collections. The structure of each methods used to be a Convolutional neural network. These more than a few evaluation methods had been put in vicinity to analyse and consider the overall performance of every model. The part established that the mannequin was once correct trained, as considered by means of the tiny hole between the validation and education lines. The strains commence to flatten out about 0.97, which used to be roughly the equal degree the place the mannequin accomplished its fantastic accuracy—when in contrast to the confusion matrix True positive, which used to be additionally 0.97, confirmed that the plot was once correct. The statistics had been interpreted to suggest that the mannequin accurate labelled 97% of the most cancers indicators.
The 2nd strategy analysed blood-smear snap shots and ran a WBC test. It recognized and counted the extent of high-quality sorts of white blood cells in order to healthy every and each and every WBC stage to the reference desk and decide whether or not or no longer or no longer a affected man or lady had cancer. The mannequin loss and mannequin accuracy from teaching the approach have been provided. It proven that this approach had now no longer been as suitable skilled as the prior method. The method’s accuracy used to be no longer cautioned in percentage shape in the confusion matrix, as was once as soon as done. This used to be due to the WBC test’s requirement to measure the extent of white blood cells found. After all, the degree of every mobile impacted the most cancers outcome—average blood neutrophil and lymphocyte ranges need to be the greatest. Despite this, the outcomes printed low numbers of neutrophils and lymphocytes, as properly as enormous portions of monocytes and eosinophils. The peculiar quantities of WBC kinds recommended the opportunity of leukaemia. The whole accuracy of the mannequin was once 81%, which was once decrease than the genomic sequence technique, in accordance to the categorization report. It used to be evident that the first mannequin had a higher accuracy, which would perchance be attributed to the dataset. The picture sample was once as soon as ten thousand snap shots in size, which used to be 5 situations the dimension of the genome mannequin sample. A large dataset was once as soon as necessary for the take a look at given that limiting the extent of snap pictures would no longer create an appropriate picture of the blood sample. It would totally be a small fraction of the entire sample, ensuing in an insufficient blood test. According to the classification record for the photo processing approach, the type blunders for WBC sorts had been already significant, and lowering the dimension of the snap pictures will enlarge the range error even more. Reducing the pattern dimension for the WBC take a appear to be at is as a outcome no longer a first-rate desire due to the truth it can moreover compromise the test’s accuracy and it requires a precise fluctuate of samples. Increasing the genome dataset would be difficult thinking about that acquiring a large ample dataset was once as soon as difficult, and pre-processing manually was once as soon as a outstanding deal higher onerous. It might also moreover be a future enhance concept to optimise the pre-processing step and make it absolutely automated. The genome method’s diagnoses were no longer impacted by the quantity of markers, which was a notable contrast between these two tests. In addition, the WBC take a seem at was once as soon as a multi-class categorization and dealt with greater requirements than the genomic approach, which entirely labored with two labels: most cancers and non-cancer markers. This made the 2nd mannequin notably extra tough and necessitated in addition testing.
The real effective used to be no longer the solely correct element of the confusion matrix that used to be important. Because it is a most cancers detection test, it is integral to have a low vary for the two kinds of mistakes, false exquisite and false negative. The false-positive give up end result supposed that the model identified most cancers on the other hand found none. The false-negative give up end result used to be that no most cancers markers had been identified, alternatively this was once incorrect. The genomic method published that the two kinds of errors had modest levels, alternatively the values for the photo processing confusion matrix differed for every WBC type. The neutrophils(0) produced the most wrong predictions amongst the 4 phone types, at 422. Because of the excessive quantity of misguided prediction, the neutrophils’ stage raises higher issues about how correctly the neutrophil snap shots had been recognised. The recall had a share of sixty one and an accuracy of 88%, in accordance to the categorization report. This end result was once seen as the algorithm predicting most of the time successfully however with few results. However decrease precision, indicating that the method used to forecast classification 1 was once erroneous. A excessive proportion in each recall and accuracy would have been ideal. These low type-error numbers name into doubt the accuracy of the WBC check due to the fact the methods are leukaemia detectors and ought to be as actual as feasible. Misdiagnosis is a serious error that can have serious implications when used in actual life. Although the accuracy confirmed that the genome sequencing approach was once as soon as greatest for diagnosing cancer, the WBC take a look at is increased normally utilised owing to its low rate and utility in third-world nations. The take a look at has the advantage of being successful to manipulate the end result manually, then again it can be time-consuming. The troubles with gathering DNA, altering it into data, and storing it in a impenetrable database is a hard and highly-priced operation in and of itself. If sources for DNA sequencing are available, that is a higher option.
Conclusion
Because the topic area was complex and difficult to accomplish, detecting leukaemia using CNN as an architectural network was both intriguing and demanding. Nonetheless, it includes fascinating characteristics such as genetic. Both fashions employed identical hyper-parameters and neural networks, with wonderful categorization models as a good starting point for comparison.
References:
- Zhou X, Li C, Rahaman MM, Yao Y, Ai S, Sun C, et al. A Comprehensive Review for Breast Histopathology Image Analysis Using Classical and Deep Neural Networks. IEEE Access 2020;8:90931–56. https://doi.org/10.1109/ACCESS.2020.2993788.
- Sutanto DH, Ghani Mka. A Benchmark Of Classification Framework For Non-Communicable Disease Prediction : A Review 2015.
- Gautam R, Kaur P, Sharma M. A comprehensive review on nature inspired computing algorithms for the diagnosis of chronic disorders in human beings. Prog Artif Intell 2019;8:401–24. https://doi.org/10.1007/s13748-019-00191-1.
- Mahmood M, Al-Khateeb B, Alwash WM. A review on neural networks approach on classifying cancers. IAES Int J Artif Intell 2020;9:317–26. https://doi.org/10.11591/ijai.v9.i2.pp317-326.
- Fatima N, Liu L, Hong S, Ahmed H. Prediction of Breast Cancer, Comparative Review of Machine Learning Techniques, and Their Analysis. IEEE Access 2020;8:150360–76. https://doi.org/10.1109/ACCESS.2020.3016715.
- Wisesty UN, Mengko T, Purwarianti A. Gene mutation detection for breast cancer disease: A review. IOP Conf Ser Mater Sci Eng 2020;830:32051. https://doi.org/10.1088/1757-899X/830/3/032051.
- Pang T, Wong JHD, Ng WL, Chan CS. Deep learning radiomics in breast cancer with different modalities: Overview and future. Expert Syst Appl 2020;158:113501. DOI Foundation.
- Punitha S, Amuthan A, Joseph KS. Enhanced Monarchy Butterfly Optimization Technique for effective breast cancer diagnosis. J Med Syst 2019;43:206. DOI Foundation
- Umamaheswari TS, Sumathi P. Enhanced firefly algorithm (EFA) based gene selection and adaptive neuro neutrosophic inference system (ANNIS) prediction model for detection of circulating tumor cells (CTCs) in breast cancer analysis. Cluster Comput 2019;22:14035–47. DOI Foundation.
- Chen R, Yang L, Goodison S, Sun Y. Deep-learning approach to identifying cancer subtypes using high-dimensional genomic data. Bioinformatics 2019;36:1476–83. DOI Foundation.
- Dhannoon BN. Predication and Classification of Cancer Using Sequence Alignment and Back Propagation Algorithms in Brca1 and Brca2 Genes. Int J Pharm Res 2019;11. DOI Foundation
- Mostavi M, Chiu Y-C, Huang Y, Chen Y. Convolutional neural network models for cancer type prediction based on gene expression. BMC Med Genomics 2020;13. DOI Foundation.
- Liu Q, Hu P. Association Analysis of Deep Genomic Features Extracted by Denoising Autoencoders in Breast Cancer. Cancers (Basel) 2019;11. DOI Foundation
- Romo-Bucheli D, Janowczyk A, Gilmore H, Romero E, Madabhushi A. A deep learning based strategy for identifying and associating mitotic activity with gene expression derived risk categories in estrogen receptor positive breast cancers. Cytometry A 2017;91:566–73. DOI Foundation
- El-Nabawy A, El-Bendary N, Belal NA. A feature-fusion framework of clinical, genomics, and histopathological data for METABRIC breast cancer subtype classification. Appl Soft Comput 2020;91:106238. DOI Foundation.
- Karakış R, Tez M, Kılıç YA, Kuru Y, Güler İ. A genetic algorithm model based on artificial neural network for prediction of the axillary lymph node status in breast cancer. Eng Appl Artif Intell 2013;26:945–50. DOI Foundation.
- Zhang F, Chen J, Wang M, Drabier R. A neural network approach to multi-biomarker panel discovery by high-throughput plasma proteomics profiling of breast cancer. BMC Proc 2013;7:S10–S10. DOI Foundation.
- Alsaleem MA, Ball G, Toss MS, Raafat S, Aleskandarany M, Joseph C, et al. A novel prognostic two-gene signature for triple negative breast cancer. Mod Pathol 2020;33:2208–20. DOI Foundation.
- Lancashire LJ, Powe DG, Reis-Filho JS, Rakha E, Lemetre C, Weigelt B, et al. A validated gene expression profile for detecting clinical outcome in breast cancer using artificial neural networks. Breast Cancer Res Treat 2010;120:83–93. DOI Foundation.
- Rawat RR, Ruderman D, Macklin P, Rimm DL, Agus DB. Correlating nuclear morphometric patterns with estrogen receptor status in breast cancer pathologic specimens. Npj Breast Cancer 2018;4:32. DOI Foundation
- Zhang D, Zou L, Zhou X, He F. Integrating Feature Selection and Feature Extraction Methods With Deep Learning to Predict Clinical Outcome of Breast Cancer. IEEE Access 2018;6:28936–44. DOI Foundation.
- Beykikhoshk A, Quinn TP, Lee SC, Tran T, Venkatesh S. DeepTRIAGE: interpretable and individualised biomarker scores using attention mechanism for the classification of breast cancer sub-types. BMC Med Genomics 2020;13:20. DOI Foundation.