The world of generative artificial intelligence has moved at a lightning pace over the last two years. We have transitioned from the excitement of static image generation to the awe-inspiring potential of AI-generated video. However, for most creators, there has always been a significant hurdle: the “silent film” problem. Until recently, AI video models focused almost exclusively on the visual, leaving the auditory component as an afterthought or a separate process entirely.
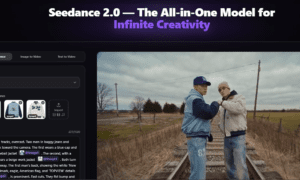
With the release of Seedance AI, developed by the ByteDance Seed team, that era is officially over. Seedance 2.0 represents a monumental shift from simple video synthesis to a fully integrated, multimodal cinematic engine. By introducing a unified architecture that treats sound and vision as a single, cohesive output, ByteDance is redefining what is possible in the realm of AI-driven creativity.
The Paradigm Shift: Unified Multimodal Architecture
At its core, Seedance 2.0 is powered by a Unified Multimodal Model (UMM). To understand why this is a breakthrough, we must look at how previous AI video tools functioned. Traditionally, if you wanted a video of a thunderstorm, you would generate the visuals first and then use a separate audio AI—or a library of sound effects—to find a matching thunderclap. This often resulted in a “disconnect,” where the timing and texture of the sound didn’t quite match the intensity of the light on screen.
Seedance 2.0 eliminates this friction. Its architecture is trained to understand the inherent relationship between visual motion and auditory resonance. When the model generates a scene, it isn’t just predicting pixels; it is predicting the “vibe” and the physics of the entire environment. This results in videos where every action has a corresponding, perfectly timed sound, creating an immersive experience that feels “real” to the human brain.
Key Breakthroughs in Seedance 2.0
1. Seamless Audio-Visual Synchronization
The headline feature of Seedance 2.0 is its native ability to generate synchronized audio. This isn’t just a generic background track. The model produces context-aware stereo sound effects, narration, and ambient noise that are hard-coded into the video’s timeline.
- Spatial Audio: If a car speeds from the left side of the frame to the right, the sound pans accordingly, creating a three-dimensional auditory experience.
- Physical Sound Effects: Whether it’s the clinking of a glass, the rustle of clothing, or the heavy thud of footsteps, the audio is generated in direct response to the movement shown on screen.
2. Professional-Grade Instruction Following
For professional creators, “control” is more important than “random beauty.” One of the most significant improvements in version 2.0 is its enhanced instruction-following capability. The model can now digest long scripts and complex, multi-layered prompts without losing the plot. Whether you provide a text description, a reference image, or an audio clip as an “anchor,” Seedance 2.0 respects the nuances of your creative vision. It understands camera angles, specific lighting requests, and intricate character movements, allowing the user to act less like a “prompter” and more like a film director.
3. High-Fidelity Motion and Realism
Visual artifacts and “morphing” have long been the Achilles’ heel of AI video. Seedance 2.0 addresses this through a robust Diffusion Transformer (DiT) backbone that prioritizes physical consistency. The way water splashes, the way fabric drapes, and the way human muscles move under the skin are all rendered with a new level of fidelity. This makes the output not just a “cool clip,” but a viable asset for commercial production.
Empowering the Next Generation of Creators
The release of Seedance 2.0 isn’t just a technical win; it’s a democratization of the production pipeline. The barriers to entry for high-quality video production are being dismantled in several key industries:
- Social Media & Marketing: Content creators can now produce “social-ready” videos with professional sound design in a fraction of the time. The ability to generate a high-quality ad from a single script—complete with voiceover and background music—is a game-changer for small businesses.
- Film & Concept Art: Filmmakers can use Seedance 2.0 for rapid prototyping. Instead of static storyboards, they can create living, breathing “look-dev” clips to pitch ideas to studios or investors.
- Education & Training: Complex concepts can be visualized and explained through AI-generated videos that include realistic narration, making learning more engaging and accessible.
Future of Multimodal AI
As we move further into 2026, the search landscape will increasingly prioritize “Multimodal” and “Integrated” AI solutions. Seedance 2.0 positions ByteDance at the center of this conversation. For brands and developers looking to stay ahead of the curve, understanding how to leverage these unified models is essential.
The keywords driving the industry today—AI Video Generation, Synchronized Audio, Unified Multimodal Architecture, and Instruction Following—are all embodied in Seedance 2.0. By providing a platform that handles the heavy lifting of audio-visual alignment, ByteDance is allowing the human element to shine where it matters most: in the storytelling.
Conclusion: Setting the New Standard
Seedance 2.0 is a testament to the power of integrated AI. By bridging the gap between sight and sound, it has moved us one step closer to a world where the only limit to cinematic creation is the user’s imagination. It is no longer enough for an AI to show us something beautiful; it must also make us hear it and feel it.
The model’s ability to take a vision from a simple text prompt to a finished, audible cinematic clip is a massive achievement for the Seed team. As we look forward to the future updates, it is clear that Seedance is not just participating in the AI race—it is setting the pace.
To explore the full potential of this next-generation engine and see the future of synchronized AI video for yourself, visit the official portal at Seedance 2.0.