Many software teams find it tempting to put all their effort into the “wow” factor, highlighting bright new features and slick screens. Yet too often, the foundation on which those features rest is overlooked. A survey shows that 47% of projects cannot meet their goals due to poor requirements management. Other surveys indicate that 37% of projects fail due to a lack of defined objectives and milestones.
Functional requirements describe what the system does: letting users log in, process payments, or generate reports. Quality attributes or non-functional requirements (NFRs), on the other hand, define how it does those things: how fast, how secure, how reliable, and how smoothly it all runs behind the scenes. That invisible side of software often determines whether the solution fades fast or stands the test of time.
Why Quality Attributes Matter
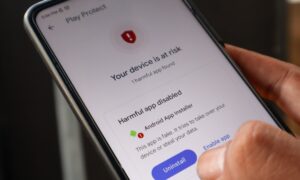
Imagine you open your banking app to transfer money, and it takes 30 seconds to load. Or worse, it crashes during a payment. You’ll probably uninstall it and switch to a competitor.
Behind that frustrating 30-second load time or the crash are missing NFRs. A stable banking app depends on well-defined goals for performance, scalability, reliability, and security. These requirements must be clearly specified and measurable.
For example, the app might be designed to load the main dashboard in under two seconds, maintain 99.9% uptime, support 10,000 concurrent users without slowdowns, and encrypt all transactions end to end. Defining such targets transforms vague ambitions like “fast” or “secure” into concrete standards engineers can design, test, and monitor against. This way, the app can be trusted to flawlessly perform in real-world conditions.
Core Software Quality Attributes
We’ve already mentioned performance, scalability, reliability, and security. But these are just a few of the NFRs that influence software success. In practice, companies such as SPD Technology focus on an even broader set of quality requirements and emphasize them from the very start of the architecture stage.
Availability
Availability defines the critical metric of how consistently a system is up and ready for use. A service that is frequently unavailable or down for extended periods creates an immediate business risk: users will abandon it. This causes a loss of revenue and, more importantly, a catastrophic loss of credibility.
Consider the scenario of an online retailer on Black Friday. If it’s inaccessible during that critical peak hour, it means the business demonstrates a lack of essential availability design features like fail-over and redundancy.
Reliability
When the system behaves consistently and correctly under expected conditions, it is reliable. Such a system doesn’t crash randomly, lose data, or produce different results for the same input.
For instance, a taxi app that often miscalculates routes or drops users off in the wrong place will quickly drive users away. Reliability means the app performs consistently and accurately, so users can trust it every time they open it.
Resilience
When we are talking about resilience, we mean the system’s ability to recover from issues, handle failures with grace, and continue functioning under pressure.
The following examples explain the concept of resilience best: when a streaming service automatically reroutes traffic during a server outage so viewers experience no interruption, or when an online store continues processing orders even if one payment gateway fails.
Scalability
A scalable system can handle growing numbers of users, transactions, or data without slowing down or crashing. To accommodate increasing demand, a scalable system is usually backed by more servers, optimized databases, or distributed workloads. These measures keep performance steady even as the user base multiplies.
A clear example of scalability is when a photo-sharing service grows from 100 active users to 10,000 overnight, and the app maintains its expected speed and responsiveness.
Performance
A system’s performance is fundamentally built upon its responsiveness and efficiency. The first refers to how quickly pages load or tasks complete, creating a smooth user experience. The second ensures the system delivers that speed without wasting memory, processing power, or energy.
When things don’t happen fast, the user notices. If a search engine returns results in full seconds rather than milliseconds, the experience feels slow and taxing.
Security
Security protects data by ensuring its confidentiality, integrity, and availability, privacy by controlling the collection, use, and sharing of personal user information, and adherence to compliance standards by implementing controls to meet industry regulations and government laws.
For example, a medical app for viewing patient test results ensures strong security through MFA and RBAC. Patient data is encrypted in transit with TLS 1.3 and at rest with AES-256. To meet HIPAA compliance, the system maintains audit logs of all access attempts and undergoes regular penetration testing.
Observability
Systems need visibility into their inner workings through monitoring, logging, and tracing. This observability is essential for detecting issues, diagnosing failures, and maintaining system health in production.
To illustrate: an eCommerce platform uses distributed tracing, logging, and monitoring to track transactions across services. When checkout speeds drop, engineers quickly trace the issue to a payment API timeout and resolve it before significant revenue loss.
Usability
If users struggle to find their way around your app, they’ll leave, no matter how strong the technical performance. That’s the test of usability: an intuitive app succeeds, a confusing one fails.
A well-designed checkout process on an eCommerce website, for example, one that includes autofill, progress indicators, and clear error messages, can significantly reduce cart abandonment. Conversely, a confusing flow with unclear fields may lead to lost sales even when products and prices are competitive.
The Art of Trade-offs
It’s rare to optimize all NFRs to their fullest because improving one often comes at the expense of another. Tightening security can slow things down, and chasing perfect availability often means more servers, higher costs, and added complexity.
The challenge lies in finding the right balance. That’s why engineering teams must align technical trade-offs with business objectives by defining what quality means for their specific context, for example:
- Finance and banking prioritize security and reliability to protect data and keep transactions uninterrupted.
- eCommerce focuses on performance and scalability to handle traffic spikes and enable smooth checkouts.
- Healthcare emphasizes data integrity, privacy, and availability to ensure patient safety and compliance.
- Media and streaming value scalability and availability to deliver content to millions without buffering.
- IoT and manufacturing rely on reliability, fault tolerance, and observability to keep devices and systems running safely.
Capturing and Validating NFRs
To make non-functional requirements truly effective, they must be specific, measurable, and tied to real-world conditions. Instead of vaguely aiming to “perform well under load,” engineers might define tests simulating 50,000 concurrent logins, keeping CPU usage below 70% and response times steady. Likewise, a resilience goal could require automatic failover to another cloud region within 30 seconds, with no data loss or duplicate transactions.
To ensure the system continues to meet those objectives, engineers use regular refactoring along with continuous validation, a process that relies on automated testing, load testing, and chaos engineering experiments. Automated testing ensures new code doesn’t break existing features, load testing checks performance under real-world demand, and chaos engineering deliberately introduces failures to verify the system’s ability to recover.
But when teams skip these practices in favor of quick releases, they accumulate what Ward Cunningham called technical debt. As he put it, “Shipping first-time code is like going into debt… the danger occurs when the debt is not repaid.” Each shortcut may save time in the moment, but it creates structural weaknesses that make future updates slower and costlier. Refactoring and continuous validation are how teams repay that debt before it becomes overwhelming.
Building a Culture of Quality
Refactoring and continuous validation are some of the core practices that help preserve technical quality over time, but they are only part of the bigger picture. True software quality comes from a culture where good engineering habits are built into every stage of development.
There are other quality-ensuring practices that are important to make an inherent part of the software development process.
- Early architecture reviews ensure that performance, scalability, and security are considered before any code is written to reduce costly rework later.
- Peer code reviews catch bugs, improve readability, and share knowledge across the team to strengthen both code quality and collaboration.
- CI/CD pipelines with automated quality gates keep releases stable by automatically testing and validating code changes before deployment.
- Performance, security, and observability checks help teams detect bottlenecks, vulnerabilities, or failures early so that systems remain reliable in production.
- Regular refactoring prevents technical debt by continuously improving the code structure as the system’s understanding evolves.
When these practices become part of the team’s daily rhythm, quality turns into a habit. That’s what gives software the best chance to succeed.
Conclusion
Features may get attention, but it’s invisible (at first glance!) quality attributes that decide whether software becomes a reliable foundation rather than a fleeting novelty. For teams and businesses alike, treating NFRs as long-term investments elevates software from something that merely works today to something built to thrive tomorrow.
Author
Yaroslav Brahinets, Engineering Manager, SPD Technology. He helps transform engineering groups into high-performing, streamlined teams with a strong focus on personal growth, business impact, and end-to-end delivery.