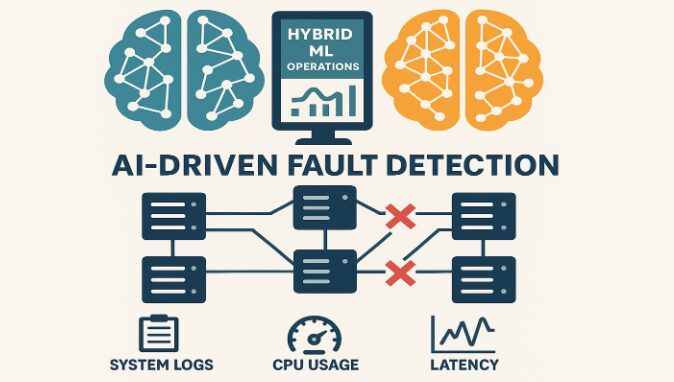
The reliability of distributed computing systems like Hadoop is critical for big data operations, where even minor node failures can cascade into major disruptions. According to Harsha Vardhan Reddy Goli in his research article published in the International Journal of Intelligent Systems and Applications in Engineering, a hybrid machine learning (ML) framework offers a transformative solution by combining classification and forecasting models to proactively detect and manage faulty nodes in Hadoop environments. This system leverages key metrics, such as system logs, CPU usage, and latency data to provide early warnings and trigger automated mitigation strategies. By reducing job failure rates, optimizing resource usage, and improving system resilience, hybrid ML frameworks redefine fault tolerance in distributed systems.
Hybrid ML and Hadoop: A Strategic Combination
Fault Detection Through Intelligent Data Analysis
Hadoop’s architecture, though robust and scalable, suffers from vulnerabilities when nodes malfunction due to hardware issues, resource contention, or network instability. Traditional monitoring systems, which rely heavily on rule-based or threshold-dependent methods, often fail to detect subtle or emerging anomalies in real time. In contrast, hybrid ML frameworks intelligently parse logs and monitor CPU and latency metrics to classify nodes as healthy or faulty. This is achieved through: Classification algorithms, Time-series forecasting models and Ensemble learning techniques
This synergy of ML approaches enhances the predictive capacity of the framework, enabling real-time intervention well before failures disrupt system operations.
Advantages of a Hybrid ML Architecture
Scalability, Automation, and Fault Tolerance
Hybrid ML frameworks offer a suite of benefits that surpass conventional fault detection systems including Early detection of anomalies using log parsing and multivariate metric analysis. Automated corrective actions such as task redistribution (node rebalancing) and dynamic resource scaling. Alert mechanisms to notify administrators while allowing the system to remain self-healing.
Additionally, the architecture’s modular design supports real-time scalability, making it suitable for clusters of varying sizes. Containerized environments or orchestrators like Kubernetes can further augment its deployment, enabling adaptive resource provisioning based on predicted workloads.
Addressing Key Challenges in Fault Detection
Managing System Complexity and Performance Overhead
Implementing ML-based systems within Hadoop clusters introduces complexity and computational costs. Hybrid models, especially those incorporating LSTM networks—require significant training time and resource consumption. As cluster sizes grow, optimizing model efficiency becomes paramount. Challenges include three of the following High computational overhead, Dependence on clean and structured data and Balancing prediction accuracy with system performance.
To mitigate these issues, preprocessing techniques such as log normalization, missing value imputation, and data scaling are used to ensure data integrity. Future versions of the framework may benefit from lightweight or distributed learning models to enhance scalability.
Experimental Results: Quantifying Impact
Improved Reliability and Resource Optimization
A series of experiments on a real-world Hadoop cluster revealed the effectiveness of the hybrid ML model. Over several months, system logs, CPU metrics, and latency data were collected and analyzed. The results were promising:
- Job Failure Rate was reduced by 40%, showcasing proactive fault prevention.
- Fault Detection Accuracy reached 92%, a 15% improvement over traditional methods.
- Resource Utilization was optimized via workload balancing and predictive scaling, leading to higher throughput and reduced idle time.
These outcomes confirm that the hybrid ML framework can enhance the stability, efficiency, and responsiveness of Hadoop environments under high computational stress.
Future Outlook for ML-Driven Cluster Management
The adoption of hybrid machine learning for fault detection in distributed systems represents a significant evolution in predictive maintenance and system resilience. Unlike reactive rule-based systems, hybrid ML models offer proactive, scalable solutions tailored for modern big data infrastructure. While computational demands remain a concern, future research may explore model simplification, federated learning, and integration with broader intelligent automation systems.
By leveraging historical and real-time metrics, ensemble ML models create a foundation for self-aware distributed environments that can anticipate and neutralize failures before they impact operations. As big data ecosystems grow more complex, such intelligent frameworks will become indispensable tools for maintaining seamless performance and reliability.
Conclusion: Advancing Fault Detection with Hybrid Machine Learning
Harsha Vardhan Reddy Goli’s study on hybrid machine learning for fault detection in Hadoop clusters delivers a practical, forward-thinking solution to a critical challenge in distributed systems. By integrating classification and forecasting models, this framework ensures proactive fault management, significantly reducing job failure rates and enhancing fault detection accuracy.
The article bridges theoretical advancements and real-world applications, demonstrating how intelligent frameworks can optimize resource utilization, improve system reliability, and adapt to varying scales. Harsha’s work is a cornerstone for IT professionals and researchers, offering actionable strategies to ensure the resilience and efficiency of modern big data infrastructures, marking a transformative step in distributed system management.