A Game-Changer in AI-Powered Document Search
Developed by Raghavan K Lakshmana, a technologist and an open-source contributor who is interested in pushing the limits of information retrieval. PDFGPTIndexer is a testament to his intellect and expertise. His work in combining Retrieval-Augmented Generation (RAG) with vector databases has led to a transformative tool that enhances document knowledge discovery.
The rapid evolution of AI-driven applications has paved the way for innovative tools that improve information retrieval. Among the latest to gain widespread attention is PDFGPTIndexer, an open-source project that skyrocketed to the top of Hacker News. This tool leverages RAG and vector databases to enable seamless interaction with large PDF documents. As enterprises and independent developers explore ways to integrate AI into document indexing, PDFGPTIndexer offers a powerful, accessible solution.
What is PDFGPTIndexer?
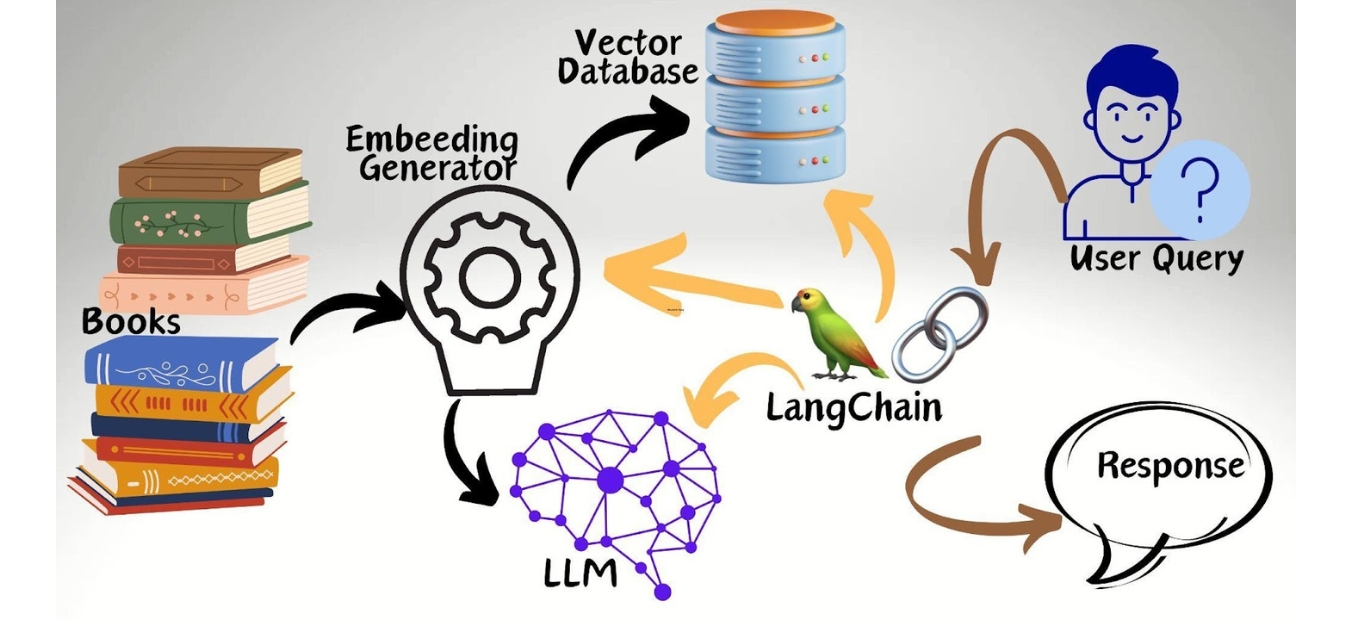
PDFGPTIndexer is a RAG-based document retrieval system designed to improve the intelligence of PDF searching and interaction. It utilizes vector databases and the Large Language Model (LLM) to allow users to query large documents conversationally. Instead of manually skimming hundreds of pages, users can ask natural-language questions and receive relevant answers, effectively turning PDFs into interactive knowledge bases without exposing them to the Internet.
Embedding Generator
At its core, the tool processes PDFs by splitting them into manageable chunks, embedding these chunks into a vector database, and leveraging a LLM for natural language query resolution. This makes it particularly useful for legal documents, research papers, company reports, and other extensive text-heavy materials.
LangChain
LangChain is a powerful framework designed to build applications that leverage LLMs by integrating components like memory, chains, and agents for dynamic AI interactions. It simplifies the development of AI-driven applications, enabling seamless integration with various data sources, APIs, and external tools.
Understanding the RAG Model
RAG is a hybrid AI approach that enhances traditional language models by incorporating retrieval mechanisms. Unlike standard LLMs, which rely solely on pre-trained knowledge, RAG models fetch relevant contextual data from external sources like a vector database to generate a response. This approach improves accuracy, reduces hallucinations, and ensures that responses are grounded in the latest, domain-specific knowledge.
PDFGPTIndexer capitalizes on RAG by storing document embeddings in a vector database, retrieving the most relevant chunks upon user query, and feeding this data into an LLM to craft informed responses.
What is a Vector Database?
Vector databases are at the heart of AI-powered search and retrieval systems. They store high-dimensional vector embeddings, which represent text data in a way that facilitates fast and efficient similarity searches. When a user queries a document, the system retrieves the closest vector matches, ensuring highly relevant results.
Several vector database solutions dominate the market
- FAISS (Facebook AI Similarity Search): An open-source library optimized for local, high-speed nearest neighbor searches.
- Pinecone: A cloud-based vector database offering managed services for scalable AI applications.
- Weaviate: A hybrid cloud-native solution integrating machine learning pipelines.
- Milvus: An enterprise-grade vector database designed for high-performance AI workloads.
Each of these solutions serves different needs, with FAISS being a preferred choice for local implementations where privacy and control are priorities.
Using FAISS for Local Vector Storage
PDFGPTIndexer leverages FAISS as its local vector storage system. FAISS is widely known for its efficiency in handling billions of vectors with low-latency retrieval. For an open-source project like PDFGPTIndexer, FAISS offers the perfect balance of performance, scalability, and accessibility without cloud dependencies. For documents where privacy is vital this could be a great solution.
By embedding PDF chunks as numerical vectors and storing them in FAISS, the tool can perform rapid similarity searches. This ensures that when a user asks a question, the system finds the most relevant text chunks almost instantaneously, improving response accuracy and speed.
Ingesting PDFs and Tokenizing Effectively
To enable seamless document interaction, PDFGPTIndexer employs text tokenization techniques. The ingestion process consists of:
- Splitting PDFs into text chunks – This prevents information loss and maintains context.
- Generating embeddings – These embeddings are stored as vectors in FAISS.
- Efficient indexing – Ensures rapid retrieval during user queries.
Tokenization plays a crucial role in optimizing storage and retrieval. By breaking text into manageable segments, the model ensures that responses are contextually relevant without exceeding LLM token limits.
Using LLMs for Chat-Based Completion
Once relevant document fragments are retrieved, the next step is LLM-powered text generation. PDFGPTIndexer integrates with various Large Language Models, such as OpenAI, Meta’s Llama, or open-source alternatives.
Upon receiving a query, the system follows these steps:
- Retrieves the most relevant document snippets via vector search.
- Passes them as context to an LLM.
- Generates a natural language response.
This approach ensures that responses remain fact-based and document-specific, making PDFGPTIndexer ideal for use cases like legal research, corporate documentation, and academic papers.
How PDFGPTIndexer Became a Viral Sensation
The open-source community thrives on innovation, and PDFGPTIndexer hit the right chord by solving a highly practical problem—intelligent document interaction. The tool gained viral traction on Hacker News, with developers and AI enthusiasts praising its simple yet powerful implementation.
Several factors contributed to its rapid rise:
- Addressing a real-world pain point – Traditional search methods in large PDFs are cumbersome; PDFGPTIndexer provides an AI-driven alternative.
- Leveraging open-source and community collaboration – The GitHub repository quickly amassed contributors, improving features and fixing bugs in real time.
- Riding the AI wave – With the growing demand for AI-powered search, PDFGPTIndexer aligns perfectly with current industry needs.
- Ease of setup and customization – The tool is easy to deploy, making it accessible for developers of all skill levels.
As enterprises continue to seek efficient AI-powered document management solutions, PDFGPTIndexer is poised to become a cornerstone tool for intelligent search and knowledge retrieval.
Conclusion
PDFGPTIndexer exemplifies the power of open-source AI innovation. By combining RAG architecture, FAISS vector storage, and LLM-powered chat interaction, it delivers a seamless document search experience. Its rise on Hacker News highlights the increasing demand for practical AI applications that enhance productivity. As the AI landscape evolves, tools like PDFGPTIndexer will continue to shape the future of document intelligence, making complex information more accessible and secure than ever.